




 本文深入探讨了深度学习的关键技术,包括权重初始化、归一化与标准化、PCA、CNN的平移不变性、AdaBoost、数据规范化的重要性、霍夫曼编码、生成与判别模型的区别、ROCAUC、模型集成、Attention机制、参数与非参数模型、KNN与KMeans、SVM、逻辑回归、卷积加速、卷积与池化操作的理解、输入图片尺寸变化、图像分类的技巧等。
本文深入探讨了深度学习的关键技术,包括权重初始化、归一化与标准化、PCA、CNN的平移不变性、AdaBoost、数据规范化的重要性、霍夫曼编码、生成与判别模型的区别、ROCAUC、模型集成、Attention机制、参数与非参数模型、KNN与KMeans、SVM、逻辑回归、卷积加速、卷积与池化操作的理解、输入图片尺寸变化、图像分类的技巧等。
这里写目录标题
- 一级目录
- 1、权重初始化
- 2、归一化、标准化
- 3、PCA(principal component analysis)
- 4、既然cnn对图像具有平移不变性,那么利用 图像平移(shift)进行数据增强来训练cnn会有效果吗?
- AdaBoost
- 5、深度学习训练中数据规范化(Normalization)的重要性
- 6、霍夫曼编码
- 7、生成模型和判别模型的区别
- 8、ROC AUC
- 9、模型集成的方法
- 10、生成模型和判别模型
- 11、attention机制SENET、CBAM模块
- 12、参数模型与非参数模型
- 13、KNN和Kmeans
- 14、SVM
- 15、逻辑回归
- 16、卷积加速
- 17、如何理解卷积、池化等、全连接层等操作
- 18、输入图片经卷积池化后的大小
- 19、图像分类任务的各种tricks
一级目录
二级目录
三级目录
1、权重初始化
1. 均匀分布
torch.nn.init.uniform_(tensor, a=0, b=1) # 服从~U(a,b)
2. 正态分布
torch.nn.init.normal_(tensor, mean=0, std=1) # 服从~N(mean,std)N(mean, std)N(mean,std)
3. 初始化为常数
torch.nn.init.constant_(tensor, val) # 初始化整个矩阵为常数val
4. Xavier
基本思想是通过网络层时,输入和输出的方差相同,包括前向传播和后向传播。
初始化会出现的问题:
- 如果初始化值很小,那么随着层数的传递,方差就会趋于0,此时输入值 也变得越来越小,在sigmoid上就是在0附近,接近于线性,失去了非线性
- 如果初始值很大,那么随着层数的传递,方差会迅速增加,此时输入值变得很大,而sigmoid在大输入值写倒数趋近于0,反向传播时会遇到梯度消失的问题
对于Xavier初始化方式,pytorch提供了uniform和normal两种:
torch.nn.init.xavier_uniform_(tensor, gain=1) 均匀分布 ~ U(−a,a)
torch.nn.init.xavier_normal_(tensor, gain=1) 正态分布~N(0,std)
5. kaiming (He initialization)
- Xavier在tanh中表现的很好,但在Relu激活函数中表现的很差,所何凯明提出了针对于Relu的初始化方法。
- 在ReLU网络中,假定每一层有一半的神经元被激活,另一半为0,所以,要保持方差不变,只需要在 Xavier 的基础上再除以2,也就是说在方差推到过程中,式子左侧除以2.
- 针对于Relu的激活函数,基本使用He initialization,pytorch也是使用kaiming 初始化卷积层参数的
pytorch也提供了两个版本:
torch.nn.init.kaiming_uniform_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’), 均匀分布 ~ U(−bound,bound)
torch.nn.init.kaiming_normal_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’), 正态分布~ N(0,std)
两函数的参数:
- a:该层后面一层的激活函数中负的斜率(默认为ReLU,此时a=0)
- mode:‘fan_in’ (default) 或者 ‘fan_out’. 使用fan_in保持weights的方差在前向传播中不变;使用fan_out保持weights的方差在反向传播中不变
6. 正交初始化(Orthogonal Initialization)
主要用以解决深度网络下的梯度消失、梯度爆炸问题,在RNN中经常使用的参数初始化方法。
torch.nn.init.orthogonal_(tensor, gain=1) # 使得tensor是正交的
7. 单位矩阵初始化
torch.nn.init.eye_(tensor) # 将二维tensor初始化为单位矩阵(the identity matrix)
8. 稀疏初始化
torch.nn.init.sparse_(tensor, sparsity, std=0.01)
- 从正态分布N~(0. std)中进行稀疏化,使每一个column有一部分为0
- sparsity- 每一个column稀疏的比例,即为0的比例
2、归一化、标准化
归一化(MinMaxScaler)(normalization)
将训练集中某一列数值特征(假设是第i列)的值缩放到0和1之间。

标准化(StandardScaler)
将训练集中某一列数值特征(假设是第i列)的值缩放成均值为0,方差为1的状态。如下所示:
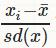
标准化之后,数据的范围并不一定是0-1之间,数据不一定是标准正态分布,因为标准化之后数据的分布并不会改变,如果数据本身是正态分布,那进行标准化之后就是标准正态分布。
对比
-
进一步明确二者含义归一化和标准化的相同点都是对某个特征(column)进行缩放(scaling)而不是对某个样本的特征向量(row)进行缩放。对特征向量进行缩放是毫无意义的(暗坑1) 比如三列特征:身高、体重、血压。每一条样本(row)就是三个这样的值,对这个row无论是进行标准化还是归一化都是好笑的,因为你不能将身高、体重和血压混到一起去!
-
在线性代数中,将一个向量除以向量的长度,也被称为标准化,不过这里的标准化是将向量变为长度为1的单位向量,它和我们这里的标准化不是一回事儿,不要搞混哦(暗坑2)。
-
好处
- 提升模型精度。归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
- 提升收敛速度。对于线性model来说,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
-
在机器学习中,标准化是更常用的手段,归一化的应用场景是有限的。
- 标准化更好保持了样本间距。当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去。
- 标准化更符合统计学假设对一个数值特征来说,很大可能它是服从正态分布的。
-
如果你不用正则,那么,标准化并不是必须的,如果你用正则,那么标准化是必须的。
3、PCA(principal component analysis)
- 只是一种总结某些数据的方法。描述一个物体有很多特征,但是其中很多属性都是相关的,因此会出现一些冗余。因此我们可以通过更少的特性总结每个物体。
- PCA并没有选择一些特性然后丢弃其余。相反,它创建一些新特性,结果这些新特性能够很好地总结我们的物体。当然,这些新特性是由旧特性构建的
- PCA寻找最佳的可能特性,那些可能总结红酒列表的特性中最好的那些(在所有可能的线性组合中)
- PCA寻找能尽可能体现红酒差异的属性。
- 所以PCA寻找能够尽可能好地重建原本特性的属性。
- PCA可以将数据投影到分布分散的平面内,而忽略掉分布集中的平面。
4、既然cnn对图像具有平移不变性,那么利用 图像平移(shift)进行数据增强来训练cnn会有效果吗?
- 平移不变性(translation invariant)指的是CNN对于同一张图及其平移后的版本,都能输出同样的结果。
- 平移等价性(translation equivalence)当输入发生平移时,输出也应该相应地进行平移。
- 就是CNN的平移不变性主要是通过数据学习来的
- 结构只能带来非常弱的平移不变性
- 而学习又依赖于数据增强中的裁切,裁切相当于一种更好的图像平移。
- 全连接层更能学到平移不变性。
- 从单层来看,只有全局池化有一定的平移不变性,其它都比较弱甚至没有。
- 如果把这些层串起来,那么在使用全连接层的时候整个CNN的结构一般不具有平移不变性。
- 能用于分类的平移不变性主要来源于参数。因为卷积层的平移等价性,这种平移不变性主要是由最后的全连接层来学习,而对于没有全连接层的网络更难有这种性质。
AdaBoost
将多个弱分类器进行合理的结合,使其成为一个强分类器。
- 弱分类器:强分类器是能够正确的识别过程,弱分类器就是那个易错的。
- AdaBoost算法一般是用单层决策树作为弱分类器,也就是决策树的最简化版本,只有一个决策点。也就是说对于多维特征的训练数据,这个弱分类器也只能选择其中的一个一维特征来做决策。
- AdaBoost的两种权重:一种为数据权重、一种为分类器权重
- 数据权重:用于确定分类器权重(弱分类器寻找其分类最小的决策点,找到之后用这个最小的误差计算出弱分类器的权重)
- 分类器权重:说明了弱分类器在最终决策中拥有发言权的大小
5、深度学习训练中数据规范化(Normalization)的重要性
-
在pytorch附带的模型中我们可以选择预训练模型。预训练模型即模型中的权重参数都被训练好了,在构造模型后读取模型权重即可。
-
但是有些东西需要注意:
- 模型的权重参数是训练好的,但是要确定你输入的数据和预训练时使用的数据格式一致。
- 要注意什么时候需要格式化什么时候不需要。
-
平常输入的图像大部分都是三通道RGB彩色图像,数据范围大部分都是[0-255],也就是通常意义上的24-bit图(RGB三通道各8位)。
-
在pytorch的官方介绍中也提到了,pytorch使用的预训练模型搭配的数据必须是:
- 3通道RGB图像(3 x H x W)
- 而且高和宽最好不低于224
- 并且图像数据大小的范围为[0-1]
- 使用mean和std去Normalize。
-
格式化(Normalization)
在一组图中,每个图像的像素点首先减去所有图像均值的像素点,然后再除以标准差。这样可以保证所有的图像分布都相似,也就是在训练的时候更容易收敛,也就是训练的更快更好了。- 显然,格式化就是使数据中心对齐,如cs231n中的示例图,左边是原始数据,中间是减去mean的数据分布,右边是除以std标准差的数据分布,当然cs231n中说除以std其实可以不去执行,因为只要数据都遵循一定范围的时候(比如图像都是[0-255])就没有必要这样做了。

-
这个函数强调的是把数据的方差和均值调整为1和0,具体数据落在哪个区间不重要,因为to tesor已经把数据落在0、1区间了,我试验了一下,在0、1区间内,任意调整数据,标准差是1和均值是0,最终数据都在-2~2之间。
6、霍夫曼编码
- 霍夫曼(Huffman)编码是1952年为文本文件而建立,是一种统计zhi编码。属于无损压缩编码。
- 霍夫曼编码的码长是变化的,对于出现频率高的信息,编码的长度较短;而对于出现频率低的信息,编码长度较长。这样,处理全部信息的总码长一定小于实际信息的符号长度。
- 步骤进行:
- 将信号符号按概率大小进行排列.
- 给概率最小的两个信源符号分配一个码位0和1,然后将这两个符号合并为一个,计算其概率和作为一个新的符号进行重新排列.
- 重复第二步操作,直至信源只剩两个符号为止,此时两个符号的概率之后必为1. 然后依照最后一级开始,依编码路径向前返回,得到各个信源符号对应的码字.
这种编码方式实现了两个重要目标:
1.任何一个字符编码,都不是其他字符编码的前缀。
2.信息编码的总长度最小。
总结:
- 构建的时候创建二叉树,小概率在左,大概率在右,然后加和之后重新判断
- 左边分配0,右边分配1,最后从顶端读取每个字符的霍夫编码
- 得到的结果不是唯一的
7、生成模型和判别模型的区别
- 按照求解的方法,可以将分类算法分为判别模型和生成模型。给定特定的向量x与标签值y,生成模型对联合概率p(x,y)建模,判别模型对条件概率p(y|x)进行建模。
- 上述含义可以这么理解:生成模型对条件概率p(x|y)建模,判别模型对条件概率p(y|x)建模。前者可以用来根据标签值y生成的随机的样本数据x,而后者则根据样本特征向量x的值判断它的标签值y。
- 常见的生成模型有:贝叶斯分类器、高斯混合模型、隐马尔可夫模型、受限玻尔兹曼机、生成对抗网络等。
- 典型的判别模式有:感知机、决策树、kNN算法、人工神经网络、支持向量机、logistic回归和AdaBoost算法、最大熵模型、boosting方法、条件随机场 (conditional random field, CRF)等。
8、ROC AUC
参考链接
ROC (Receiver Operating Characteristic) 曲线和 AUC (Area Under the Curve)(Area Under theCurve) 值常被用来评价一个二值分类器 (binary classifier) 的优劣。
几乎我所知道的所有评价指标,都是建立在混淆矩阵基础上的,包括准确率、精准率、召回率、F1-score,当然也包括AUC。
ROC曲线
-
对于某个二分类分类器来说,输出结果标签(0还是1)往往取决于输出的概率以及预定的概率阈值。
-
实际上,这种阈值的选取也一定程度上反映了分类器的分类能力。我们当然希望无论选取多大的阈值,分类都能尽可能地正确,也就是希望该分类器的分类能力越强越好,一定程度上可以理解成一种鲁棒能力吧。
-
为了形象地衡量这种分类能力,ROC曲线横空出世
-
横轴:False Positive Rate(假阳率,FPR)
假阳率,简单通俗来理解就是预测为正样本但是预测错了的可能性,显然,我们不希望该指标太高。
-
纵轴:True Positive Rate(真阳率,TPR)
真阳率,则是代表预测为正样本但是预测对了的可能性,当然,我们希望真阳率越高越好。
-
ROC曲线的横纵坐标都在[0,1]之间
-
特性
- (0,0):假阳率和真阳率都为0,即分类器全部预测成负样本
- (0,1):假阳率为0,真阳率为1,全部完美预测正确,happy
- (1,0):假阳率为1,真阳率为0,全部完美预测错误,悲剧
- (1,1):假阳率和真阳率都为1,即分类器全部预测成正样本
- TPR=FPR,斜对角线,预测为正样本的结果一半是对的,一半是错的,代表随机分类器的预测效果
-
于是,我们可以得到基本的结论:ROC曲线在斜对角线以下,则表示该分类器效果差于随机分类器,反之,效果好于随机分类器,当然,我们希望ROC曲线尽量除于斜对角线以上,也就是向左上角(0,1)凸。
AUC(Area under the ROC curve)
ROC曲线一定程度上可以反映分类器的分类效果,但是不够直观,我们希望有这么一个指标,如果这个指标越大越好,越小越差,于是,就有了AUC。AUC实际上就是ROC曲线下的面积。AUC直观地反映了ROC曲线表达的分类能力。
- AUC = 1,代表完美分类器
- 0.5 < AUC < 1,优于随机分类器
- 0 < AUC < 0.5,差于随机分类器
总结
- ROC曲线反映了分类器的分类能力,结合考虑了分类器输出概率的准确性
- AUC量化了ROC曲线的分类能力,越大分类效果越好,输出概率越合理
- AUC常用作CTR的离线评价,AUC越大,CTR的排序能力越强
9、模型集成的方法
转自该网站,侵删
这个比较简单,侵删
集成学习:
集成学习是一种机器学习范式。在集成学习中,我们会训练多个模型(通常称为「弱学习器」)解决相同的问题,并将它们结合起来以获得更好的结果。最重要的假设是:当弱模型被正确组合时,我们可以得到更精确和/或更鲁棒的模型。
集成方法的思想是通过将这些弱学习器的偏置和/或方差结合起来,从而创建一个「强学习器」(或「集成模型」),从而获得更好的性能。
在集成学习理论中,我们将弱学习器(或基础模型)称为「模型」,这些模型可用作设计更复杂模型的构件。在大多数情况下**,这些基本模型本身的性能并不是非常好,这要么是因为它们具有较高的偏置(例如,低自由度模型),要么是因为他们的方差太大导致鲁棒性不强(例如,高自由度模型)。**
集成方法的思想是通过将这些弱学习器的偏置和/或方差结合起来,从而创建一个「强学习器」(或「集成模型」),从而获得更好的性能。
- bagging,该方法通常考虑的是同质弱学习器,相互独立地并行学习这些弱学习器,并按照某种确定性的平均过程将它们组合起来。
- boosting,该方法通常考虑的也是同质弱学习器。它以一种高度自适应的方法顺序地学习这些弱学习器(每个基础模型都依赖于前面的模型),并按照某种确定性的策略将它们组合起来。
- stacking,该方法通常考虑的是异质弱学习器,并行地学习它们,并通过训练一个「元模型」将它们组合起来,根据不同弱模型的预测结果输出一个最终的预测结果
非常粗略地说,我们可以说 bagging 的重点在于获得一个方差比其组成部分更小的集成模型,而 boosting 和 stacking 则将主要生成偏置比其组成部分更低的强模型(即使方差也可以被减小)。
集成学习的分类:
- 个体学习器之间存在强依赖关系,必须串行生成的序列化方法——Boosting;
- 个体学习器之间不存在强依赖关系,可同时生成的并行化方法——Bagging
通常认为Bagging的主要作用是降低方差,而Boosting的主要作用是降低偏差。
Boosting
Boosting原理:Boosting是一族可将弱学习器提升为强学习器的算法,先用初始训练集训练出一个基分类器,然后,重新对所有样本的权重进行调整,使得当前基分类器分错的样本格外收到关注,根据当前基分类器的预测误差设置当前基分类器的权重。然后,将权重调整后的样本重新训练基分类器,逐步重复上述过程,直到达到指定次数,最终将多个基分类器的预测结果加权结合。
Bagging
Bagging是并行式集成学习方法的代表。该方法采用bootstrap随机重采样方法构成若干训练子集,对每个训练子集构建基分类器,再将这些基分类器的输出结果采用简单投票法进行结合。
10、生成模型和判别模型
- 生成模型,就是生成(数据的分布)的模型;
- 判别模型,就是判别(数据输出量)的模型。
生成式模型:
- 朴素贝叶斯!
- 混合高斯模型!
- 隐马尔科夫模型(HMM)!
- 贝叶斯网络
- Sigmoid Belief Networks
- 马尔科夫随机场(Markov Random Fields)
- 深度信念网络(DBN)
判别式模型:
- K近邻(KNN)
- 线性回归(Linear Regression)
- 逻辑斯蒂回归(Logistic Regression)
- 神经网络(NN)
- 支持向量机(SVM)
- 高斯过程(Gaussian Process)
- 条件随机场(CRF)
- CART(Classification and Regression Tree)
11、attention机制SENET、CBAM模块
SENet
SENET是2017年的世界冠军,SE全称Squeeze-and-Excitation是一个模块,将现有的网络嵌入SE模块的话,那么该网络就是SENet,它几乎可以嵌入当前流行的任何网络
一个feature map经过一系列卷积池化得到的feature map,通常我们认为这个得到的feature map的每个通道都是同样重要的,我们并没有分那个通道重要,那个通道不怎么重要,那么实际上会不会有这种情况呢,就是得到的featurmap 的每个通道的重要性都不一样。
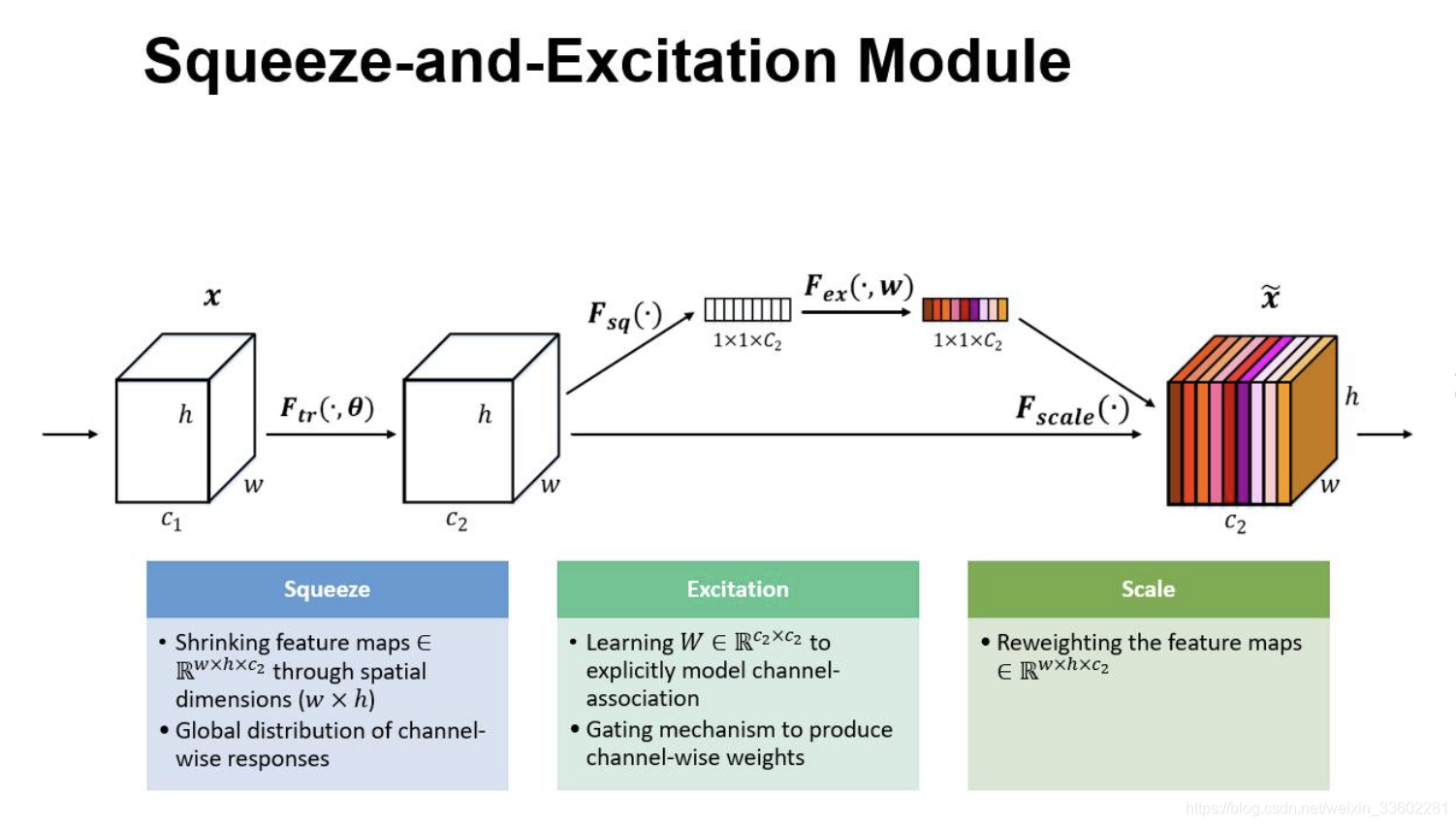
每个通道的权值或者重要性怎么来呢,做法如下:
- 其实很简单,假入原来feature map 是 h * w * c的,给它做一个global池化(池化窗口就是h * w 得到的就是1 * 1窗口,通道数不变)得到 1 * 1 * c的feature map,然后它再接两个全连接层(第一个全连接层神经元个数是c/16,相当于对c进行了降维,输入是c个特征,第二个全连接层神经元个数为c,相当于又增维回到了c个特征,这样做比直接用一个 Fully Connected 层的好处在于具有更多的非线性,可以更好地拟合通道间复杂的相关性,极大地减少了参数量和计算量),然后再接一个sigmod层(这里采用sigmod应该是通道之间是具有相关性的,所以不能用softmax,softmax的话,最终加起来必须为1),输出1 * 1 * c,原来的feature map维度h * w * c,得到的是通道的权值维度1 * 1 * c,然后它们进行相乘,这里是全乘,不是矩阵相乘,然后得到的feature map对应的每个通道重要性就不一样了(可能更重要的它的值要大些)
- 每个通道的权值都是网路学习出来的,那么怎么学习呢,记住学习,只要有参数和loss就可以
- 所以它主要学习的是SE模块这两个全连接层的参数,它们学到了,自然最终结果就有了,所用用最终的分类损失去更新这两个全连接层的参数就可以了
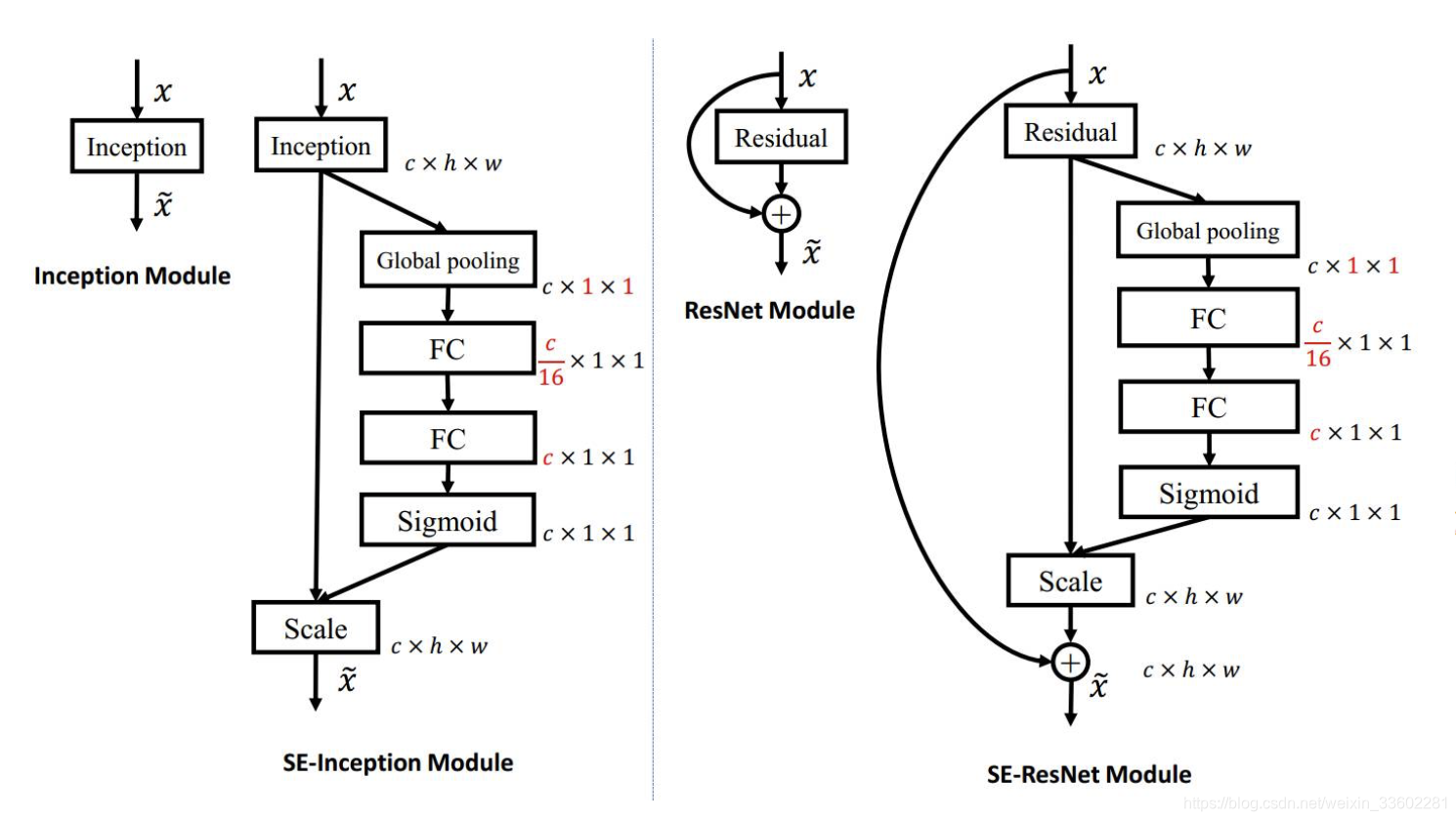
CBAM
- 它是2018年的分类冠军,它和SE一样也是一个模型,现在任何流行网络都可以嵌入这个模块
- SE的由来是因为不同通道的像素的重要性可能不一样,那么既然这样,同一个通道的不同位置像素重要性也可能不一样,所以就有了CBAM,既考虑不同通道像素的重要性,又考虑了同一通道不同位置像素的重要性
- Convolutional Block Attention Module (CBAM) 表示卷积模块的注意力机制模块。
- SE只关注通道,它既关注通道,也关注宽高
- 它的大概流程如下:
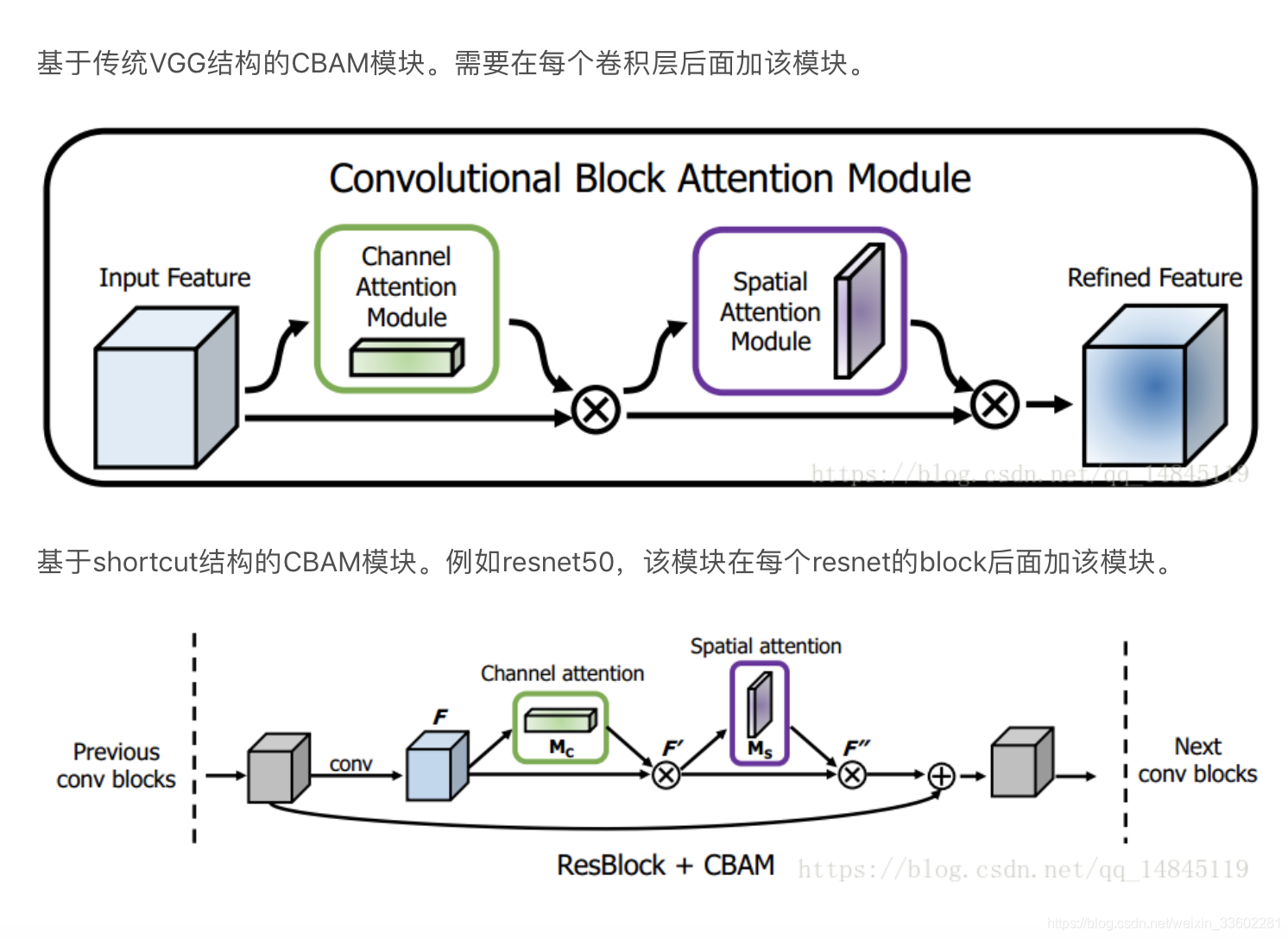
先来看通道上的attension:
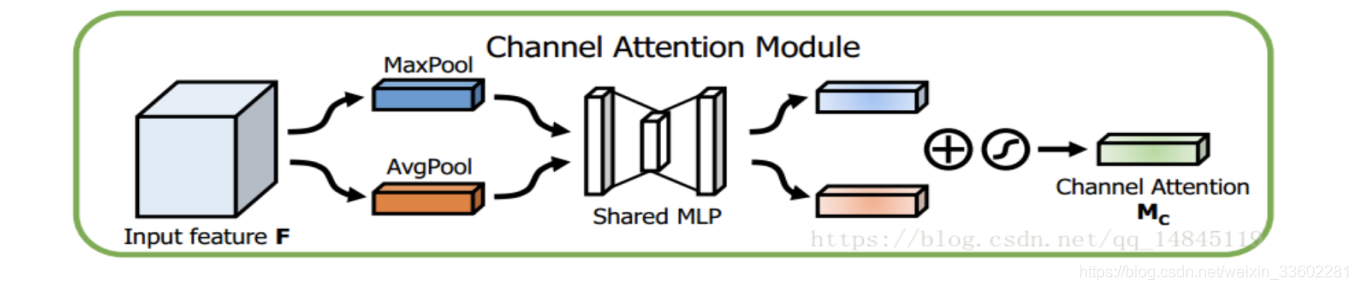
它这里和SE模块有点区别就是,SE只用了一个池化globalpool(一般是maxpool),而它这里用了两个池化maxpool,avgpool(池化本身是提取高层次特征,不同的池化意味着提取的高层次特征更加丰富),既然是两个那么输出肯定也是两个都是1*1c,然后将输出两个相加,再进行sigmod,结果也是1*1c,然后再和原来的feature map相乘。其2个池化之后的处理过程和SE一样,都是先降维再升维,不同的是将2个池化后相加再sigmod和原 feature map相乘输出结果。
然后再来看空间上的attension:

它是原来的feature map先做完通道attension ,然后它在这个基础之上进一步做空间attension的,它先将feature map 进行基于通道的池化,一般的池化都是在长宽的维度,它这个其实就是在列通道的维度池化(取一列通道的最大值,平均值),这就意味着一次池化一列通道变成了一个值就是一个通道了,长宽不变,假如输入feature map是 h * w * c,它这个一次池化后就变成了h * w * 1的feature map了,它进行了两次池化,那就是两个h * w * 1的feature map,然后将它们进行基于通道的拼接,那就变成了 h * w * 2的feature map了,然后对这个feature map用一个7*7的卷积核进行卷积,将通道数压缩成了1(因为只用了一个卷积核),得到一个新的feature map,然后对这个feature map进行sigmod的,得到一个attension feature map,然后将它和最开始的feature map进行相乘,
最终它这个空间attension feature map肯定也是学习出来的,那么具体是学习什么呢?肯定是参数,它这个过程有哪些参数,其实就是再到数第二步,用一个7*7的卷积核对输入的2层feature map卷积,那么它学习的就是这个7*7的卷积核参数
12、参数模型与非参数模型
参数模型通常假设总体(随机变量)服从某一个分布,该分布由一些参数确定(比如正太分布由均值和方差确定),在此基础上构建的模型称为参数模型;
非参数模型对于总体的分布不做任何假设,只是知道总体是一个随机变量,其分布是存在的(分布中也可能存在参数),但是无法知道其分布的形式,更不知道分布的相关参数,只有在给定一些样本的条件下,能够依据非参数统计的方法进行推断。
问题中有没有参数,并不是参数模型和非参数模型的区别。其区别主要在于总体的分布形式是否已知。
参数模型:
- 参数机器学习算法包括:
- 逻辑回归
- 线性成分分析
- 感知机
- 参数机器学习算法有如下优点:
- 简洁:理论容易理解和解释结果
- 快速:参数模型学习和训练的速度都很快
- 数据更少:通常不需要大量的数据,在对数据的拟合不很好时表现也不错
- 参数机器学习算法的局限性:
- 约束:以选定函数形式的方式来学习本身就限制了模型
- 有限的复杂度:通常只能应对简单的问题
- 拟合度小:实际中通常无法和潜在的目标函数吻合
非参数模型:
- 一些非参数机器学习算法的例子包括:
- 决策树,例如CART和C4.5
- 朴素贝叶斯
- 支持向量机
- 神经网络
- 非参数机器学习算法的优势:
- 可变性:可以拟合许多不同的函数形式。
- 模型强大:对于目标函数不作假设或者作微小的假设
- 表现良好:对于预测表现可以非常好。
- 非参数机器学习算法局限性:
- 需要更多数据:对于拟合目标函数需要更多的训练数据
- 速度慢:因为需要训练更多的参数,训练过程通常比较慢。
- 过拟合:有更高的风险发生过拟合,对于预测也比较难以解释。
13、KNN和Kmeans
| KNN | K-Means |
|---|---|
| 1.KNN是分类算法 | 1.K-Means是聚类算法 |
| 2.监督学习 | 2.非监督学习 |
| 3.喂给它的数据集是带label的数据,已经是完全正确的数据 | 3.喂给它的数据集是无label的数据,是杂乱无章的,经过聚类后才变得有点顺序,先无序,后有序 |
| 没有明显的前期训练过程,属于memory-based learning | 有明显的前期训练过程 |
| K的含义:来了一个样本x,要给它分类,即求出它的y,就从数据集中,在x附近找离它最近的K个数据点,这K个数据点,类别c占的个数最多,就把x的label设为c | K的含义:K是人工固定好的数字,假设数据集合可以分为K个簇,由于是依靠人工定好,需要一点先验知识 |
相似点:都包含这样的过程,给定一个点,在数据集中找离它最近的点。即二者都用到了NN(Nears Neighbor)算法,一般用KD树来实现NN。
Kmeans
K-Means算法的思想很简单,对于给定的样本集,按照样本与类中心距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
传统K-Means算法流程:
- 对于K-Means算法,首先要注意的是k值的选择,一般来说,我们会根据对数据的先验经验选择一个合适的k值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的k值。
- 在确定了k的个数后,我们需要选择k个初始化的质心,就像上图b中的随机质心。由于我们是启发式方法,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心,最好这些质心不能太近。
传统的K-Means算法流程。
- 输入是样本集D={x1,x2,…xm},聚类的簇树k,最大迭代次数N
- 输出是簇划分C={C1,C2,…Ck}
- 从数据集D中随机选择k个样本作为初始的k个质心向量: {μ1,μ2,…,μk}
- 对于n=1,2,…,N(迭代次数)
- 将簇划分C初始化为C_{t}= ϕ \phi ϕ,t=1,2,…k
- 对于i=1,2…m,计算样本xi和各个质心向量μj(j=1,2,…k)的距离: d i j = ∣ ∣ x i − u j ∣ ∣ 2 2 d_{ij}=||x_{i}-u_{j}||_{2}^{2} dij=∣∣xi−uj∣∣22,将xi标记最小的为dij所对应的 类别λi。此时更新 C λ i = C λ i ∪ x i C_{\lambda _{i}}=C_{\lambda _{i}}\cup {x_{i}} Cλi=Cλi∪xi
- 对于j=1,2,…,k,对Cj中所有的样本点重新计算新的质心:
u j = 1 ∣ C j ∣ ∑ x ϵ C j x u_{j}=\frac{1}{|C_{j}|}\sum_{x\epsilon C_{j}}x uj=∣Cj∣1xϵCj∑x - 如果所有的k个质心向量都没有发生变化,则转到步骤3)
- 输出簇划分C={C1,C2,…Ck}
Kmeans算法缺陷:
- 聚类中心的个数需要事先给定
- 需人为的确定初始中心(可以使用kmeans++解决),容易陷入最优
- 对噪声点异常敏感
- 对不是凸的数据集较难收敛
kmeans++
K-Means++算法就是对K-Means随机初始化质心的方法的优化。
- 从输入的数据点集合中随机选择一个点作为第一个聚类中心μ1
- 对于数据集中的每一个点xi,计算它与已选择的聚类中心中最近聚类中心的距离: D ( x i ) = a r g m i n ∣ ∣ x i − u r ∣ ∣ 2 2 , r = 1 , 2 , . . . k s e l e c t e d D(x_{i})=argmin||x_{i}-u_{r}||_{2}^{2},r=1,2,...k_{selected} D(xi)=argmin∣∣xi−ur∣∣22,r=1,2,...kselected
- 选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
- 重复b和c直到选择出k个聚类质心
- 利用这k个质心来作为初始化质心去运行标准的K-Means算法
距离计算优化elkan K-Means
- 在传统的K-Means算法中,我们在每轮迭代时,要计算所有的样本点到所有的质心的距离,这样会比较的耗时。
- 它的目标是减少不必要的距离的计算。
- elkan K-Means利用了两边之和大于等于第三边,以及两边之差小于第三边的三角形性质,来减少距离的计算
- 第一种规律是对于一个样本点x和两个质心μj1,μj2。如果我们预先计算出了这两个质心之间的距离D(j1,j2),则如果计算发现2D(x,j1)≤D(j1,j2)我们立即就可以知道D(x,j1)≤D(x,j2)。此时我们不需要再计算D(x,j2),也就是说省了一步距离计算。
- 第二种规律是对于一个样本点x和两个质心μj1,μj2。我们可以得到D(x,j2)≥max{0,D(x,j1)−D(j1,j2)}。这个从三角形的性质也很容易得到。
- 利用上边的两个规律,elkan K-Means比起传统的K-Means迭代速度有很大的提高。但是如果我们的样本的特征是稀疏的,有缺失值的话,这个方法就不使用了,此时某些距离无法计算,则不能使用该算法。
大样本优化Mini Batch K-Means
- Mini Batch,也就是用样本集中的一部分的样本来做传统的K-Means,这样可以避免样本量太大时的计算难题,算法收敛速度大大加快。当然此时的代价就是我们的聚类的精确度也会有一些降低。一般来说这个降低的幅度在可以接受的范围之内。
- 在Mini Batch K-Means中,我们会选择一个合适的批样本大小batch size,我们仅仅用batch size个样本来做K-Means聚类。那么这batch size个样本怎么来的?一般是通过无放回的随机采样得到的。
- 为了增加算法的准确性,我们一般会多跑几次Mini Batch K-Means算法,用得到不同的随机采样集来得到聚类簇,选择其中最优的聚类簇。
14、SVM
超喜欢的一个up主的视频,截图,侵删,抱歉









SVM 想要的就是找到各类样本点到超平面的距离最远,也就是找到最大间隔超平面。
支持向量就是两个样本集距离最近的几个样本点,他们到超平面的距离为d,SVM就是找到使得这个d最大的超平面。
对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
所以得到的最优化问题是:
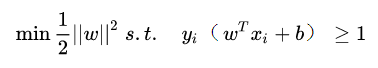
- 该问题是不等式约束优化问题。
- 其主要思想是将不等式约束条件转变为等式约束条件,引入松弛变量,将松弛变量也是为优化变量。
- 等式约束优化问题采用拉格朗日程数法。
- 带等式约束的优化问题就通过拉格朗日乘子法完美的解决了。更高一层的,带有不等式的约束问题怎么办?那么就需要用更一般化的拉格朗日乘子法,即KKT条件,来解决这种问题了。
求解线性可分的 SVM 的步骤为:
- 构造拉格朗日函数:
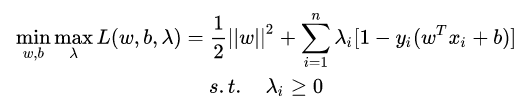
- 利用强对偶性转化:
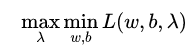
现对参数 w 和 b 求偏导数:

得到:

我们将这个结果带回到函数中可得:
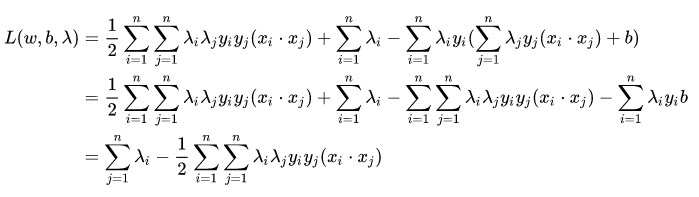
也就是说:
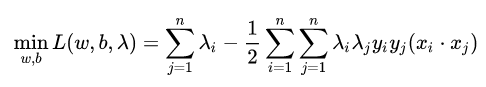
- 问题变成:

我们可以看出来这是一个二次规划问题,问题规模正比于训练样本数,我们常用 SMO(Sequential Minimal Optimization) 算法求解。
SMO(Sequential Minimal Optimization),序列最小优化算法,其核心思想非常简单:每次只优化一个参数,其他参数先固定住,仅求当前这个优化参数的极值。
这样可以求出 λ \lambda λ - 然后求出
ω
\omega
ω和b

这样就得出了超平面
软间隔:
当数据不是完全可分的时候,采用软间隔,允许一部分数据不满足设定的约束条件。
所以加入一个松弛变量,允许数据满足松弛变量的范围。

其求解步骤和上述类似,就是公式中加入了软间隔变量。
优化目标如下图所示:

同时要注意在间隔内的点也会对我们的支持平面造成影响,所以也是支持向量。
核函数
我们刚刚讨论的硬间隔和软间隔都是在说样本的完全线性可分或者大部分样本点的线性可分。
但我们可能会碰到的一种情况是样本点不是线性可分的
这种情况的解决方法就是:将二维线性不可分样本映射到高维空间中,让样本点在高维空间线性可分
核函数的引入一方面减少了我们计算量,另一方面也减少了我们存储数据的内存使用量。
优缺点
优点
- 有严格的数学理论支持,可解释性强,不依靠统计方法,从而简化了通常的分类和回归问题;
- 能找出对任务至关重要的关键样本(即:支持向量);
- 采用核技巧之后,可以处理非线性分类/回归任务;
- 最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
缺点
- 训练时间长。当采用 SMO 算法时,由于每次都需要挑选一对参数,因此时间复杂度为O(N2) ,其中 N 为训练样本的数量;
- 当采用核技巧时,如果需要存储核矩阵,则空间复杂度为 O(N2) ;
- 模型预测时,预测时间与支持向量的个数成正比。当支持向量的数量较大时,预测计算复杂度较高。
因此支持向量机目前只适合小批量样本的任务,无法适应百万甚至上亿样本的任务。
15、逻辑回归
这个是B乎上的一个详细讲解
下面图片来自上个UP主,侵删

Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。
逻辑回归就是用回归的办法来做分类
使用线性的函数来拟合规律后取阈值的办法是行不通的,行不通的原因在于拟合的函数太直,离群值(也叫异常值)对结果的影响过大,但是我们的整体思路是没有错的,错的是用了太"直"的拟合函数,如果我们用来拟合的函数是非线性的,不这么直,是不是就好一些呢?
所以我们下面来做两件事:
1-找到一个办法解决掉回归的函数严重受离群值影响的办法.
2-选定一个阈值
我们利用线性回归的办法来拟合然后设置阈值的办法容易受到离群值的影响,sigmod函数可以有效的帮助我们解决这一个问题,所以我们只要在拟合的时候把 y = w 0 x 0 + w 1 x 1 + . . . + w n x n y = w_{0}x_{0} + w_{1}x_{1} + ... +w_{n}x_{n} y=w0x0+w1x1+...+wnxn即 y = W T X y = W^{T}X y=WTX换成 g ( z ) = 1 1 + e − z g(z) = \frac{1}{1+e^{-z}} g(z)=1+e−z1即可,其中 z = W T X z=W^{T}X z=WTX,也就是说 g ( z ) = 1 1 + e w T x g(z) = \frac{1}{1 + e^{w^{T}x}} g(z)=1+ewTx1. 同时,因为 g ( z ) g(z) g(z)函数的特性,它输出的结果也不再是预测结果,而是一个值预测为正例的概率,预测为负例的概率就是 1 − g ( z ) 1-g(z) 1−g(z).
函数形式表达:
P ( y = 0 ∣ w , x ) = 1 – g ( z ) P(y=0|w,x) = 1 – g(z) P(y=0∣w,x)=1–g(z)
P ( y = 1 ∣ w , x ) = g ( z ) P(y=1|w,x) = g(z) P(y=1∣w,x)=g(z)
P ( 正 确 ) = ( g ( w , x i ) ) y i ∗ ( 1 − g ( w , x i ) ) 1 − y i P(正确) =(g(w,xi))^{y^{i}} * (1-g(w,xi))^{1-y^{i}} P(正确)=(g(w,xi))yi∗(1−g(w,xi))1−yi y i y^{i} yi为某一条样本的预测值,取值范围为0或者1
逻辑回归的判别函数就是
g
(
z
)
=
1
1
+
e
−
z
,
z
=
W
T
X
g(z) = \frac{1}{1+e^{-z}},z=W^{T}X
g(z)=1+e−z1,z=WTX
如何求解逻辑回归,也就是如何找到一组可以让
g
(
z
)
=
1
1
+
e
−
z
g(z) = \frac{1}{1+e^{-z}}
g(z)=1+e−z1全都预测正确的概率最大的W.
每个单条样本预测正确概率的公式:
P
(
正
确
)
=
(
g
(
w
,
x
i
)
)
y
i
∗
(
1
−
g
(
w
,
x
i
)
)
1
−
y
i
P(正确) =(g(w,xi))^{y^{i}} * (1-g(w,xi))^{1-y^{i}}
P(正确)=(g(w,xi))yi∗(1−g(w,xi))1−yi
若想让预测出的结果全部正确的概率最大,根据最大似然估计就是所有样本预测正确的概率相乘得到的P(总体正确)最大.
此时我们让 ,
h
θ
(
x
)
=
1
1
+
e
−
z
\mathrm{h}_{\theta}(\mathrm{x})=\frac{1}{1+\mathrm{e}^{-\mathrm{z}}}
hθ(x)=1+e−z1数学表达形式如下:
L
(
θ
)
=
∏
i
=
1
m
(
h
θ
(
x
(
i
)
)
)
y
(
i
)
(
1
−
h
θ
(
x
(
i
)
)
)
1
−
y
(
i
)
L(\theta)=\prod_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)\right)^{y^{(i)}}\left(1-h_{\theta}\left(x^{(i)}\right)\right)^{1-y^{(i)}}
L(θ)=i=1∏m(hθ(x(i)))y(i)(1−hθ(x(i)))1−y(i)
上述公式最大时公式中W的值就是我们要的最好的W.
一个连乘的函数是不好计算的,我们可以通过两边同事取log的形式让其变成连加.形如:
l
(
θ
)
=
log
L
(
θ
)
=
∑
i
=
1
m
(
y
(
i
)
log
h
θ
(
x
(
i
)
)
+
(
1
−
y
(
i
)
)
log
(
1
−
h
θ
(
x
(
i
)
)
)
)
\begin{aligned} l(\theta) &=\log L(\theta) \\ &=\sum_{i=1}^{m}\left(y^{(i)} \log h_{\theta}\left(x^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)\right) \end{aligned}
l(θ)=logL(θ)=i=1∑m(y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i))))
得到的这个函数越大,证明我们得到的W就越好.因为在函数最优化的时候习惯让一个函数越小越好,所以我们在前边加一个负号.得到公式如下:
J
log
(
w
)
=
∑
i
=
1
m
−
y
i
log
(
p
(
x
i
;
w
)
)
−
(
1
−
y
i
)
log
(
1
−
p
(
x
i
;
w
)
)
J_{\log }(w)=\sum_{i=1}^{m}-y_{i} \log \left(p\left(x_{i} ; w\right)\right)-\left(1-y_{i}\right) \log \left(1-p\left(x_{i} ; w\right)\right)
Jlog(w)=i=1∑m−yilog(p(xi;w))−(1−yi)log(1−p(xi;w))
这个函数就是我们逻辑回归(logistics regression)的损失函数,我们叫它交叉熵损失函数.
求解交叉熵损失函数
δ
δ
θ
j
J
(
θ
)
=
−
1
m
∑
i
=
1
m
(
y
i
1
h
θ
(
x
i
)
δ
δ
θ
j
h
θ
(
x
i
)
−
(
1
−
y
i
)
1
1
−
h
θ
(
x
i
)
δ
δ
θ
j
h
θ
(
x
i
)
)
=
−
1
m
∑
i
=
1
m
(
y
i
1
g
(
θ
T
x
i
)
−
(
1
−
y
i
)
1
1
−
g
(
θ
T
x
i
)
)
δ
δ
θ
j
g
(
θ
T
x
i
)
=
−
1
m
∑
i
=
1
m
(
y
i
1
g
(
θ
T
x
i
)
−
(
1
−
y
i
)
1
1
−
g
(
θ
T
x
i
)
)
g
(
θ
T
x
i
)
(
1
−
g
(
θ
T
x
i
)
)
δ
δ
θ
j
θ
T
x
i
=
−
1
m
∑
i
=
1
m
(
y
i
(
1
−
g
(
θ
T
x
i
)
)
−
(
1
−
y
i
)
g
(
θ
T
x
i
)
)
x
i
j
=
−
1
m
∑
i
=
1
m
(
y
i
−
g
(
θ
T
x
i
)
)
x
i
j
=
1
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
)
x
i
j
\begin{aligned} \frac{\delta}{\delta_{\theta_{j}}} J(\theta) &=-\frac{1}{m} \sum_{i=1}^{m}\left(y_{i} \frac{1}{h_{\theta}\left(x_{i}\right)} \frac{\delta}{\delta_{\theta_{j}}} h_{\theta}\left(x_{i}\right)-\left(1-y_{i}\right) \frac{1}{1-h_{\theta}\left(x_{i}\right)} \frac{\delta}{\delta_{\theta_{j}}} h_{\theta}\left(x_{i}\right)\right) \\ &=-\frac{1}{m} \sum_{i=1}^{m}\left(y_{i} \frac{1}{g\left(\theta^{T} x_{i}\right)}-\left(1-y_{i}\right) \frac{1}{1-g\left(\theta^{T} x_{i}\right)}\right) \frac{\delta}{\delta_{\theta_{j}}} g\left(\theta^{T} x_{i}\right) \\ &=-\frac{1}{m} \sum_{i=1}^{m}\left(y_{i} \frac{1}{g\left(\theta^{T} x_{i}\right)}-\left(1-y_{i}\right) \frac{1}{1-g\left(\theta^{T} x_{i}\right)}\right) g\left(\theta^{T} x_{i}\right)\left(1-g\left(\theta^{T} x_{i}\right)\right) \frac{\delta}{\delta_{\theta_{j}}} \theta^{T} x_{i} \\ &=-\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}\left(1-g\left(\theta^{T} x_{i}\right)\right)-\left(1-y_{i}\right) g\left(\theta^{T} x_{i}\right)\right) x_{i}^{j} \\ &=-\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}-g\left(\theta^{T} x_{i}\right)\right) x_{i}^{j} \\ &\left.=\frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x_{i}\right)-y_{i}\right)\right) x_{i}^{j} \end{aligned}
δθjδJ(θ)=−m1i=1∑m(yihθ(xi)1δθjδhθ(xi)−(1−yi)1−hθ(xi)1δθjδhθ(xi))=−m1i=1∑m(yig(θTxi)1−(1−yi)1−g(θTxi)1)δθjδg(θTxi)=−m1i=1∑m(yig(θTxi)1−(1−yi)1−g(θTxi)1)g(θTxi)(1−g(θTxi))δθjδθTxi=−m1i=1∑m(yi(1−g(θTxi))−(1−yi)g(θTxi))xij=−m1i=1∑m(yi−g(θTxi))xij=m1i=1∑m(hθ(xi)−yi))xij
16、卷积加速
直接计算傅里叶根本不能加速。加速的原理是有种东西叫快速傅里叶变换,能把傅里叶变换的过程从N方变NlogN,所以就加速了。
17、如何理解卷积、池化等、全连接层等操作
- 卷积的作用:捕获图像相邻像素的依赖性;起到类似滤波器的作用,得到不同形态的feature map
- 激活函数的作用:引入非线性因素
- 池化的作用:减少特征维度大小,使特征更加可控;减少参数个数,从而控制过拟合程度;增加网络对略微变换后的图像的鲁棒性;达到一种尺度不变性,即无论物体在图像中哪个方位均可以被检测到
18、输入图片经卷积池化后的大小
- 卷积向下取整,池化向上取整
- 无论是卷积层还是pooling层,公式都是这样的:
( input_size + 2*padding - kernel_size ) / stride+1 = output_size
19、图像分类任务的各种tricks
- Warmup
- Linear scaling learning rate
- Label-smoothing
- Random image cropping and patching
- Knowledge Distillation
- Cutout
- Random erasing
- Cosine learning rate decay
- Mixup training
- AdaBoud
- AutoAugment
- 其他经典的tricks
Warmup:
- Warm up是在ResNet论文中提到的一种学习率预热的方法。
- 学习率预热就是在刚开始训练的时候先使用一个较小的学习率,训练一些epoches或iterations,等模型稳定时再修改为预先设置的学习率进行训练。
- 上述的方法是constant warmup,18年Facebook又针对上面的warmup进行了改进,因为从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。提出了gradual warmup来解决这个问题,即从最开始的小学习率开始,每个iteration增大一点,直到最初设置的比较大的学习率。
Linear scaling learning rate:
- 随着batch size的增大,处理相同数据量的速度会越来越快,但是达到相同精度所需要的epoch数量越来越多。也就是说,使用相同的epoch时,大batch size训练的模型与小batch size训练的模型相比,验证准确率会减小。
- 增大batch size不会改变梯度的期望,但是会降低它的方差。也就是说,大batch size会降低梯度中的噪声,所以我们可以增大学习率来加快收敛。
- 具体做法很简单,比如batch size为256时选择的学习率是0.1,当我们把batch size变为一个较大的数b时,学习率应该变为 0.1 × b/256。
Label-smoothing:
-
one-hot编码会有一些问题。这种方式会鼓励模型对不同类别的输出分数差异非常大,或者说,模型过分相信它的判断。但是,对于一个由多人标注的数据集,不同人标注的准则可能不同,每个人的标注也可能会有一些错误。模型对标签的过分相信会导致过拟合。
-
标签平滑。具体思想是降低我们对于标签的信任,例如我们可以将损失的目标值从1稍微降到0.9,或者将从0稍微升到0.1。

其中,ε是一个小的常数,K是类别的数目,y是图片的真正的标签,i代表第i个类别,q_i是图片为第i类的概率 -
总的来说,LSR是一种通过在标签y中加入噪声,实现对模型约束,降低模型过拟合程度的一种正则化方法。
Random image cropping and patching:
- 随机裁剪四个图片的中部分,然后把它们拼接为一个图片,同时混合这四个图片的标签。
- 按照裁剪图片的大小可以得到每个图片的权重
- 计算输出对每个标签的损失
- 然后根据权重可以分别乘以损失得到最后的总损失
Knowledge Distillation:
- 提高几乎所有机器学习算法性能的一种非常简单的方法是在相同的数据上训练许多不同的模型,然后对它们的预测进行平均。但是使用所有的模型集成进行预测是比较麻烦的,并且可能计算量太大而无法部署到大量用户。知识蒸馏可以解决这个问题。
- 在知识蒸馏方法中,我们使用一个教师模型来帮助当前的模型(学生模型)训练。教师模型是一个较高准确率的预训练模型,因此学生模型可以在保持模型复杂度不变的情况下提升准确率。
- 在训练过程中,我们会加一个蒸馏损失来惩罚学生模型和教师模型的输出之间的差异。
- 给定输入,假定p是真正的概率分布,z和r分别是学生模型和教师模型最后一个全连接层的输出。之前我们会用交叉熵损失l(p,softmax(z))来度量p和z之间的差异,这里的蒸馏损失同样用交叉熵。所以,使用知识蒸馏方法总的损失函数是
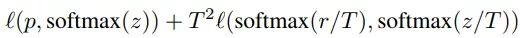
Cutout: - 是一种新的正则化方法
- 原理是在训练时随机把图片的一部分减掉,这样能提高模型的鲁棒性。
- 它的来源是计算机视觉任务中经常遇到的物体遮挡问题。通过cutout生成一些类似被遮挡的物体,不仅可以让模型在遇到遮挡问题时表现更好,还能让模型在做决定时更多地考虑环境(context)。
Random erasing:
- 和cutout非常类似,也是一种模拟物体遮挡情况的数据增强方法。
- 区别在于,cutout是把图片中随机抽中的矩形区域的像素值置为0,相当于裁剪掉,random erasing是用随机数或者数据集中像素的平均值替换原来的像素值。
- 而且,cutout每次裁剪掉的区域大小是固定的,Random erasing替换掉的区域大小是随机的。
Cosine learning rate decay:
- 学习率不断衰减是一个提高精度的好方法。其中有step decay和cosine decay等,前者是随着epoch增大学习率不断减去一个小的数,后者是让学习率随着训练过程曲线下降。
- 对于cosine decay,假设总共有T个batch(不考虑warmup阶段),在第t个batch时,学习率η_t为:
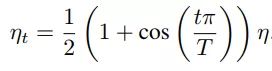
这里,η代表初始设置的学习率。这种学习率递减的方式称之为cosine decay。 - 看出cosine decay比step decay更加平滑一点。
Mixup training:
- 是一种新的数据增强的方法。
- 每次取出2张图片,然后将它们线性组合,得到新的图片,以此来作为新的训练样本,进行网络的训练
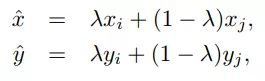
其中,λ是从Beta(α, α)随机采样的数,在[0,1]之间。在训练过程中,仅使用(xhat, yhat)。 - Mixup方法主要增强了训练样本之间的线性表达,增强网络的泛化能力,不过mixup方法需要较长的时间才能收敛得比较好。
AdaBoud
AutoAugment
常用的正则化方法:
- Dropout
- L1/L2正则
- Batch Normalization
- Early stopping
- Random cropping
- Mirroring
- Rotation
- Color shifting
- PCA color augmentation
- …




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









