




 本文提出一种基于二值词袋模型的快速视觉位置识别方法,利用FAST+BRIEF特征进行实时回环检测。通过词汇树加速对应关系的几何验证,实现在大规模图像序列中无假阳性的竞争性结果。与传统方法相比,计算效率提高一个数量级。
本文提出一种基于二值词袋模型的快速视觉位置识别方法,利用FAST+BRIEF特征进行实时回环检测。通过词汇树加速对应关系的几何验证,实现在大规模图像序列中无假阳性的竞争性结果。与传统方法相比,计算效率提高一个数量级。
Bags of Binary Words for Fast Place Recognition in Image Sequences
摘要
一种新的方法用于基于FAST+BRIEF特征词袋的视觉位置识别。
首先,建立了一个离散二值描述符空间的词汇树,并使用该树来加速几何验证的对应关系。
使用完全一样的词汇和设置,在不同的数据集中呈现没有假阳性的竞争性结果。
包含特征提取在内,在拥有26300张图片的序列中需要每帧22ms,比之前的方法快一个数量级。
简介
鲁棒的位置识别是视觉SLAM最重要的需求之一。对于小环境,map-to-image方法 [1] 表现出不错的性能,但是对于较大环境,image-to-image(或者appearance-based)方法,例如FAB-MAP [2] ,尺度更好。其基本技术是根据机器人在线采集的图像建立一个数据库,以便在获取新图像时能够检索到最相似的图像。 如果它们足够相似,则检测到一个循环闭包。(回环检测的概念)
由于感知混乱,词袋对于闭环不是完美的方案。基于此,稍后通过检查匹配图像的几何一致性来执行验证步骤,所述几何一致性要求特征对应。回环检测算法的关键是特征提取,特征提取的计算时间是其他步骤的10倍以上。这可能导致SLAM算法在两个解耦线程中运行:一个执行主要SLAM函数,另一个探测回环检测。 [5]
提出的算法的优势以及算法如何实现
本篇文章提出一种新颖的算法利用传统的CPU和单摄像机实时检测回环和建立图像之间点的对应关系。此方法建立在词袋和几何检查的基础上,几种重要创新点使得此方法比当前方法计算速度更快。其主要的速度改善来源在于对带FAST关键点的BRIEF描述子的简单修改 第三部分详细解释 。BRIEF描述子是二进制向量,每个bit都是围绕关键点给定的一对像素的强度对比结果。尽管BRIEF描述子很难满足尺度不变和旋转不变特性,试验表明在平面相机运动中此方法对于回环检测具有很好的鲁棒性,在移动机器人领域很常见的情况,此方法在计算时间和区分度之间做了一个很好的折衷。
提出算法的实现方法
引入词袋离散化二进制空间,利用正索引扩充词袋,派出通常的逆索引。这在第四部分详细介绍据我们所知,这是第一次利用二进制词汇表进行回环检测。逆索引被用于潜在的与给定图像相似的图像的快速检索。我们提出了一种新的直接索引方法来有效地获取图像之间的点对应关系,加快了循环验证过程中的几何检查。
完整的回环检测算法在第五部分被详细介绍第五部分。和我们之前的工作相似,为了确定一个循环已经被关闭,我们验证了所获得的图像匹配的时间一致性。本文的创新点之一是提出了一种在查询数据库时防止在同一位置采集的图像相互竞争的技术。我们通过将那些在匹配期间描绘相同位置的图像分组来实现这一点。
第六部分包含我们工作的实验评估,包括对算法中不同部分的相对优点的详细分析。我们比较了BRIEF和两个版本的SURF特性的有效性,这个描述符最常用于回环闭环。我们还分析了用于循环验证的时间一致性测试和几何一致性测试的性能。
相关工作
基于外观的位置识别由于取得了良好的识别效果而受到机器人界的广泛关注。FAB-MAP已经成为回环检测的黄金标准,但是当图像长时间地描绘非常相似的结构时,其鲁棒性降低,在使用正面照相机时出现这种现象。两个视觉词汇表(外观和颜色)是以增量方式在线创建的。这两个词袋表示一起用作贝叶斯滤波器的输入,贝叶斯滤波器估计两幅图像之间的匹配概率,同时考虑先前情况的匹配概率。与这些概率方法不同,我们依赖于时间一致性检查来考虑先前的匹配并提高检测的可靠性。我们的工作与上述工作的不同之处在于,我们首次使用了一个二进制单词包,并且提出了一种技术来防止在匹配过程中收集到在时间上接近并且描绘了相同的位置的图像发生竞争,从而使我们能够以更高的频率工作。
描述以前的相关算法,并给出算法相应的缺点。
提出的算法,相比于其他的算法的优点
在大部分回环闭环过程中,被使用的特征是SIFT(尺度不变特征变换)和SURF(加速鲁棒特征)。它们之所以受欢迎,是因为它们不受光照、缩放和旋转变化的影响,并且在轻微的透视变化时表现出良好的行为。但是计算时间通常需要100和700ms。除GPU应用外,其他类似特征试图减少计算时间,通过近似SIFT描述子或减少维度的方法。Konolige提出一种质变的方法,因为其使用紧凑的随机树签名 [19] 。该方法计算图像片与之前离线阶段训练的图像片之间的相似性。通过将这些相似度值级联,计算出贴片的描述符向量,最后用随机正交投影对贴片的维数进行降维。这产生一种适用于实时应用的快速描述子。我们的工作和其相似之处在于仍然是通过使用有效特征减少执行时间。BRIEF描述子和其他BRISK或ORB描述子一样,是二进制,并需要较少计算时间。作为一个优点,它们的信息非常紧凑,因此它们占用的内存更少,比较速度更快。 这允许更快地转换到词袋空间。
BINARY FEATURES 二进制特征
当比较图像时,提取本地特征(关键点和描述子向量)通常非常消耗计算时间。利用FAST关键点和最新的BRIEF描述子 减少计算时间。FAST关键点是通过比较半径为3的Bresenham圆中的一些像素的灰度来检测的角点。因为只检查了几个像素,所以这些点非常快,可以成功地用于实时应用。
对于每个快速关键点,我们在它们周围绘制一个正方形片并计算一个简短的描述符。图像片的BRIEF描述子是二进制向量,每个bit是这个图像片的两个像素之间强度比较的结果。为了降低噪声,预先使用高斯核对图像片进行平滑。预先给定图像片大小
S
b
S_b
Sb ,离线阶段随机选择要测试的像素对。除了
S
b
S_b
Sb 外,必须设定参数
L
b
L_b
Lb : 执行测试的数量,即描述子的长度。对在图像中点
P
P
P ,其BRIEF描述子向量
B
(
p
)
B(p)
B(p) 由公式给定:
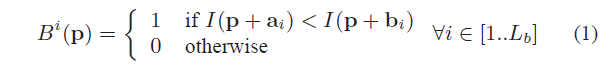
B
i
(
p
)
B^i(p)
Bi(p) 是描述子的第
i
i
i bit,
I
(
∗
)
I(*)
I(∗) 是被平滑后的图像的像素强度,
a
i
a^i
ai 和
b
i
b^i
bi 是第
i
i
i 个测试点相对图像片中心的2D平面偏移,值的范围是:
[
−
S
b
2
.
.
.
S
b
2
]
×
[
S
b
2
.
.
.
S
b
2
]
[- \frac{S_b}{2} ... \frac{S_b}{2}] \times [\frac{S_b}{2} ... \frac{S_b}{2}]
[−2Sb...2Sb]×[2Sb...2Sb] 。注意,这个描述符不需要训练,只需要离线阶段随机选择,这几乎不消耗时间。Calander等人在 [9] 文献中提出的原始BRIEF描述子根据正态分布
N
(
0
,
1
25
S
b
2
)
N(0, \frac{1}{25} S^2_b )
N(0,251Sb2) 选择点
a
i
a^i
ai 和
b
i
b^i
bi 的坐标。然而,我们发现使用紧密的测试对可以得到更好的结果。 通过抽样分布
a
i
j
∼
N
(
0
,
1
25
S
b
2
)
a^j_i \sim N(0, \frac{1}{25} S^2_b )
aij∼N(0,251Sb2) 和
b
i
j
∼
N
(
a
i
j
,
4
625
S
b
2
)
b^j_i \sim N(a^j_i , \frac{4}{625} S^2_b )
bij∼N(aij,6254Sb2) 选择这些对的每个坐标
j
j
j 。请注意,这一方法也是由[9]提出的,但没有在他们的最终实验中使用。对于描述子长度和图像片大小,选择
L
b
=
256
L_b = 256
Lb=256 和
S
b
=
48
S_b = 48
Sb=48,因为它们在区分性和计算时间之间取得了很好的折衷。
BRIEF描述子的主要优势是具有非常快的计算和比较速度(Calonder报道当
L
b
=
256
L_b=256
Lb=256时17.3us每关键点)。由于这些描述符中的一个只是位向量,所以可以通过计数两个向量之间的不同位的量(汉明距离)来测量两个向量之间的距离,这通过异或运算来实现。在这种情况下,这比计算欧几里得距离更合适,通常使用由浮点值组成的SIFT或SURF描述符来计算欧几里得距离。
Image DataBase图像数据集
为了检测重新访问的位置,我们使用一个图像数据库,该图像数据库由一个层次化的单词包和正向和反向索引组成,如图。
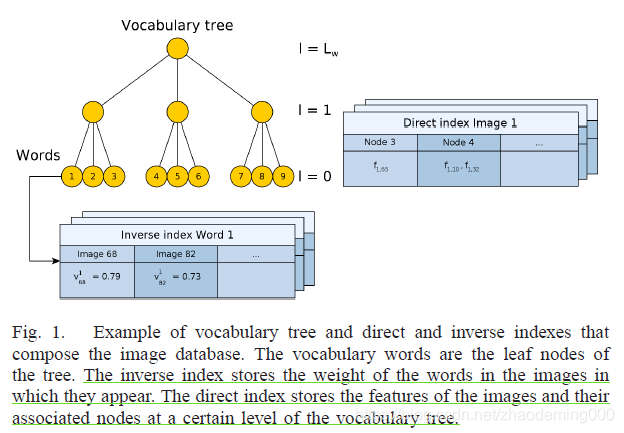
词汇袋是一种使用视觉词汇表将图像转换为稀疏数字向量的技术,允许管理大量图像集。通过将描述符空间离散为W个可视单词,离线创建可视词汇表。与SIFT或SURF等其他特性不同,我们将二进制描述符空间离散化,从而创建更紧凑的词汇表。在词的层次包的情况下,词汇表被构造为树。为了构建它,我们从一些训练图像中提取一组丰富的特征值,而不依赖于那些稍后在线处理的图像。被提取的描述子被离散成
k
w
k_w
kw 个二进制簇,通过利用K-means++技术聚类k中值实现。导致非二进制值的中值被截断为0。这些簇构成词汇树中的第一级节点。通过使用与每个节点相关联的描述符重复此操作创建后续级别,最多可达
L
w
L_w
Lw 次。最终获得带有W个分支的树,其是词汇表中的单词。每个单词根据其在训练语料库中的相关性被赋予一个权重,从而减少那些非常频繁并且区分度不高的单词的权重。因此,使用检索词频率——逆文档频率(tf-idf)。然后,为了将在时间t处获取的图像转换成词袋向量
v
t
属
于
R
W
v_t 属于R^W
vt属于RW ,通过在每一层选择一个最小化汉明距离的中间节点使得其特征的二进制描述子覆盖从跟到枝叶整个树。
为了测量两个词袋向量
v
1
v_1
v1 和
v
2
v_2
v2 的相似性,计算
L
1
−
s
c
o
r
e
L_1-score
L1−score
s
(
v
1
,
v
2
)
s(v_1, v_2)
s(v1,v2) ,其值的范围在
[
0
,
.
.
.
,
1
]
[0, ... ,1]
[0,...,1] :
s
(
v
1
,
v
2
)
=
1
−
1
2
∣
v
1
∣
v
1
∣
−
v
2
∣
v
2
∣
∣
s(v_1, v_2) = 1- \frac{1}{2} \left | \frac{v_1}{\left | v_1\right |} - \frac{v_2}{\left |v_2\right |} \right |
s(v1,v2)=1−21∣∣∣∣v1∣v1−∣v2∣v2∣∣∣
除词袋外,逆序索引被提到。这个结构将词汇表中的每个单词
w
i
w_i
wi 存储到其所在的图像
I
t
I_t
It 列表中。 这在查询数据库时非常有用,因为它只允许对那些与查询图像具有某些单词共同点的图像执行比较。我们增加了反向索引来存储对
<
I
t
,
v
t
i
>
<I_t, v^i_t>
<It,vti> ,以快速访问图像中单词的权重。反向索引在新图像添加到数据库时更新,并在数据库搜索某个图像时访问。
这两种结构(词袋和倒排索引)在词袋方法中最常被使用的。然而,作为这种通用方法中的一个新颖之处,我们还使用了一个直接索引来方便地存储每个图像的特征。根据词汇表在树中的级别
l
l
l 区分节点,从枝叶开始,级别
l
=
0
l = 0
l=0, 在根部结束,级别为
l
=
L
w
l = L_w
l=Lw。对于每幅图像
I
t
I_t
It,利用直接索引存储级别为
l
l
l 的节点,以及和每个节点相关的本地特征
f
t
j
f_{tj}
ftj。利用直接索引和词袋树在BRIEF描述空间中近似最近邻。直接索引允许通过仅计算属于相同单词的那些特征之间的对应关系,或者计算属于级别
l
l
l 上具有共同祖先的单词的那些特征之间的对应关系,来加速几何验证。直接索引在向数据库中添加新图像时更新,在获得候选匹配并需要几何检查时访问。
LOOP DETECTION ALGORITHM 回环检测算法
为了检测循环闭包,我们使用了一种基于我们先前工作的方法,该方法遵循下面详细描述的四个阶段。
A Database query
我们使用图像数据库来存储和检索与任何给定图像相似的图像。当最新的图像
I
t
I_t
It 被获取时,被转换进词袋向量
v
t
v_t
vt 中。在数据库中搜索
v
t
v_t
vt ,产生与其分数
s
(
v
t
,
v
t
j
)
s(v_t, v_{t_j})
s(vt,vtj) 相关的匹配候选列表
<
v
t
,
v
t
1
>
,
<
v
t
,
v
t
2
>
,
.
.
.
,
<v_t, v_{t_1}>,<v_t, v_{t_2}>, ... ,
<vt,vt1>,<vt,vt2>,...,。这些分数的变化范围很大程度上取决于查询图像及其包含的单词的分布。然后,我们用我们期望在该序列中获得的向量
v
t
v_t
vt 的最佳分数来归一化这些分数,获得归一化的相似性分数
η
\eta
η :
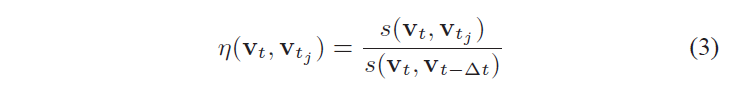
利用
s
(
v
t
,
v
t
−
Δ
t
)
s(v_t, v_{t-\Delta t})
s(vt,vt−Δt) 近似
v
t
v_t
vt 的期望分数,其中
v
t
−
Δ
t
v_{t-\Delta t}
vt−Δt 是上一副图像的词袋向量。当机器人转向时,
s
(
v
t
,
v
t
−
Δ
t
)
s(v_t, v_{t-\Delta t})
s(vt,vt−Δt) 值变小,这种情况将引起错误的高分数。因而,跳过未达到最小分数
s
(
v
t
,
v
t
−
Δ
t
)
s(v_t, v_{t-\Delta t})
s(vt,vt−Δt) 或需求特征数量的图像。这个最小分数在可用于回环检测的图片数量和得分
η
\eta
η 正确性之间取了折衷。使用小值阻止有效图像被丢弃。拒绝那些分数
η
(
v
t
,
v
t
j
)
\eta (v_t, v_{t_j})
η(vt,vtj) 未达到最小阈值的匹配,表示为
α
\alpha
α 。
B Match grouping匹配组
为了防止在查询数据库时时间接近的图像之间竞争,我们将它们单独分组,并将它们仅视为一个匹配项。使用符号
T
i
T_i
Ti 代表时间间隔
t
n
i
,
.
.
.
,
t
m
i
t_{n_i}, ... , t_{m_i}
tni,...,tmi ,
V
T
i
V_{T_i}
VTi 表示将带条目
v
t
n
i
,
.
.
.
,
v
t
m
i
v_{t_{n_i}}, ... ,v_{t_{m_i}}
vtni,...,vtmi 匹配项。因而,如果连续时间戳
t
n
i
,
.
.
.
,
t
m
i
t_{n_i}, ... , t_{m_i}
tni,...,tmi之间差异较小,几个匹配项
<
v
t
,
v
t
n
i
>
,
.
.
.
,
<
v
t
,
v
t
m
i
>
<v_t, v_{t_{n_i}}>, ... ,<v_t, v_{t_{m_i}}>
<vt,vtni>,...,<vt,vtmi> 被转换成单个匹配项
<
v
t
,
V
T
i
>
<v_t, V_{T_i}>
<vt,VTi> 。这些单独分组按照得分
H
H
H 划分等级:
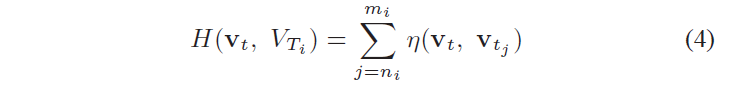
选择得分最高的独立分组作为匹配组,并继续到时间一致性步骤。除了避免连续图像之间的冲突外,这些独立分组还可以帮助建立正确的匹配。如果
I
t
I_t
It 和
T
t
′
T_{t'}
Tt′ 代表回环闭合,
I
t
I_t
It 也很可能类似于
I
t
′
±
Δ
t
,
I
t
′
±
2
Δ
t
,
.
.
.
.
.
I_{t'\pm \Delta t}, I_{t'\pm 2\Delta t}, .....
It′±Δt,It′±2Δt,..... 产生长的独立分组。定义
H
H
H 作为得分
η
\eta
η 的和,这个得分
H
H
H 也很好匹配长的独立分组。
C Temporal consistency时间一致性
在获得最佳匹配独立分组 V T ′ V_{T'} VT′ 之后,检查它与先前查询的时间一致性。本文将在文献 [5] 时间约束支持独立分组。匹配 < v t , V T ′ > <v_t, V_{T'}> <vt,VT′> 必须与之前 k k k 个匹配 < v t − Δ t , V T 1 > , . . . . , < v t − k Δ t , V T k > <v_{t-\Delta t}, V_{T_1}>, .... , <v_{t-k\Delta t}, V_{T_k}> <vt−Δt,VT1>,....,<vt−kΔt,VTk> 一致,使得间隔 T j T_j Tj 和 T j + 1 T_{j+1} Tj+1接近重叠。如果独立分组超出时间约束,仅仅保留匹配 < v t , V t ′ > <v_t, V_{t'}> <vt,Vt′>,使得 t ′ 属 于 T ′ t' 属于 T' t′属于T′时最小化得分 η \eta η , 将其视为回环闭合候选项,这必须最终被几何验证阶段所接受。
D Efficient geometrical consistency 有效的几何一致性
在回环闭合候选项的图片对之间应用集合检查。这个检测在于在被至少12个对应项支持的
I
t
I_t
It 和
I
t
‘
I_{t‘}
It‘之间发现RANSAC基础矩阵。为了计算这些对应关系,我们必须将查询图像的局部特征与匹配图像的局部特征进行比较。执行此比较有几种方法。
1、最容易、最慢的一个是穷举搜索,包括测量
I
t
I_t
It的每个特征到描述子空间中
I
t
′
I_{t'}
It′ 的特征的距离,根据最邻近距离比策略选择最佳对应关系。每幅图像特征数量的计算复杂度为
Θ
(
n
2
)
\Theta (n^2)
Θ(n2) .
2、计算近似最邻近,通过在k-d树中安排描述子向量
遵循后一种想法,我们利用词袋词汇表,并重用它来近似最邻近。因此,在将图像添加到数据库时,以直接索引的方式存储节点和特征对列表。为了获得在
I
t
I_t
It 和
I
t
′
I_{t'}
It′ 之间的一致性,以直接索引查询
T
t
′
T_{t'}
Tt′ ,仅仅和在词汇树中统一级别
l
l
l 的相同的节点的特征之间执行比较。这种情况加速一致性计算。参数
l
l
l 预先设定,并需要在
I
t
I_t
It 和
I
t
′
I_{t'}
It′ 之间获得相关数量和为此目的花费的时间之间做一个权衡。当
l
=
0
l = 0
l=0 时,仅仅属于相同单词的特征才被比较, 因此快速计算被实现,但是更少的相关性被获取。这使得由于缺少对应的点而拒绝了一些正确的循环,从而使得整个回环检测过程的回调被减少。当
l
=
L
w
l = L_w
l=Lw 时,回调没有影响,但是执行时间没有得到改善。
我们只需要基本矩阵进行验证,但注意,在计算它之后,我们可以提供与下面运行的任何SLAM算法匹配的图像之间的数据关联,而不需要额外的成本。
Experimental Evaluation 试验评估
先介绍方法论用于评估算法的方法。介绍BRIEF和SURF在此系统中的可靠性。分析我们的算法的时间一致性的影响。基于直接索引检查几何一致性的有效性。我们的完整的系统的执行时间和性能。
A 方法论
评估环路检测结果的方面通常被假定为一般知识。 然而,文献中很少给出细节。 在这里,我们解释了我们评估系统所遵循的方法。
1、数据集Datasets 在五个开源数据集中测试我们的系统。
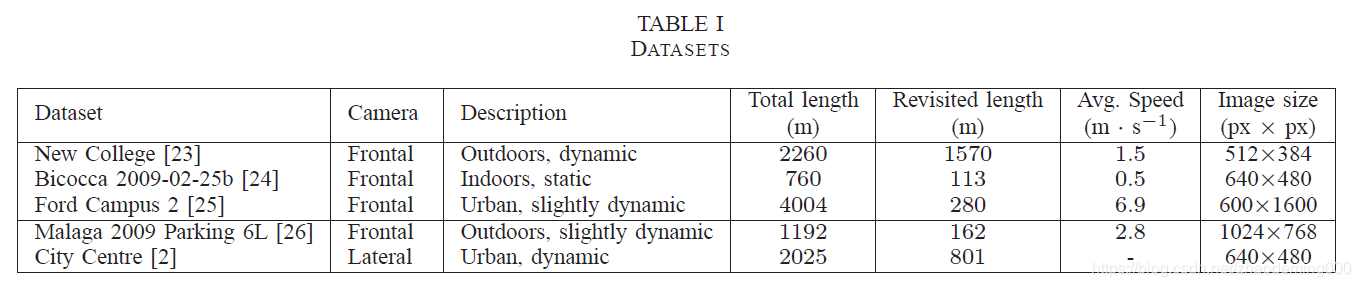
基本原理Ground truth 手动创建一个真实的回环闭环列表。这个列表由时间间隔组成,在列表中每个条目编码和匹配间隔相关的查询间隔。
Correctness measure正确性测量 我们用回调和查准率来衡量循环检测结果的正确性。查准率是正确探测的数量与被激发的所有探测之间的比,回调是正确探测与在基础原理中所有回环事件的比。被回环探测激发的匹配是一对查询和匹配时间戳。为了检查其是否是正向积极的,基本原理将搜索包含这些时间戳的间隔。在基础原理中回环事件数量被计算作为基础原理中查询间隔的长度乘以被处理图像数据集的频率。 当查询时间戳由于多次遍历导致与基本原理中不止一个时间戳相关联时,仅将他们中的一个视为计算回环事件的数量。
Selection of system parameters系统参数选择 通过评估数据调整系统参数是一种常见的方法,但是我们认识 使用不同的数据 去选择我们算法的配置和去评估它 才能展现我们算法的鲁棒性。将上表分为两组,前三个作为训练集找到最好的算法参数。另外两个作为评估数据集验证最终配置的有效性。在这些情况下,仅仅将我们的算法作为具备预定义配置的黑盒子。
Settings设置 算法针对所有的测试采用同样的设置。相同的词袋树被用于处理所有的数据集。建立
k
w
=
10
k_w = 10
kw=10 分支和
L
w
=
6
L_w = 6
Lw=6 深度层数,生成100万个单词,使用从独立数据集的10K图像获取的9M特征进行训练。我们在FAST的响应函数中使用了10个单位的阈值,在SURF的Hessian响应中使用了500个单位的阈值。对于每个处理过的图像,我们只保留响应最快的300个特征。
B Descriptor effectiveness 描述子有效性
BRIEF描述子比SURF描述子编码更少的信息,因为BRIEF不具有尺度和旋转不变性。
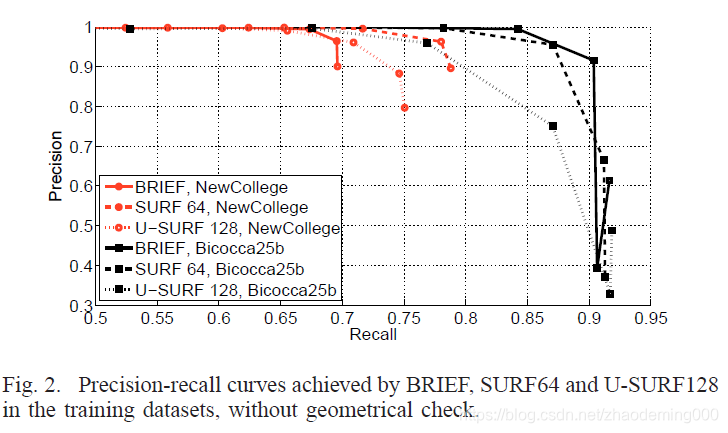

带有BRIEF描述子的FAST特征在平面相机运动中针对回环探测问题具有和SURF一样的可信赖度。其优点,其不仅速度更快(每幅图像13ms取代100-400ms),而且占用更少的内存(取代256MB,32MB去存储1M词汇表),更快的进行比较,加速分层词汇表的使用。
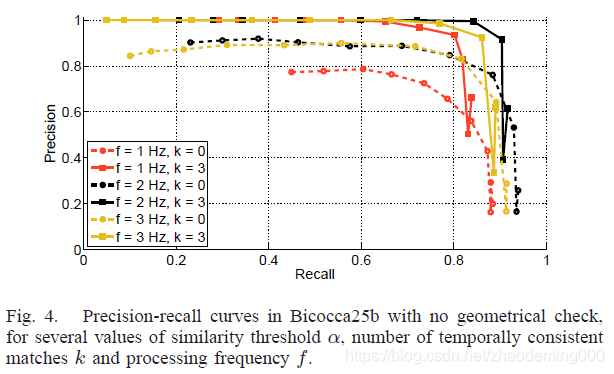
C Temporal consistency时间一致性
选择特征之后,我们测试
k
k
k 个需要接收回环闭环候选项的时间一致性匹配项。
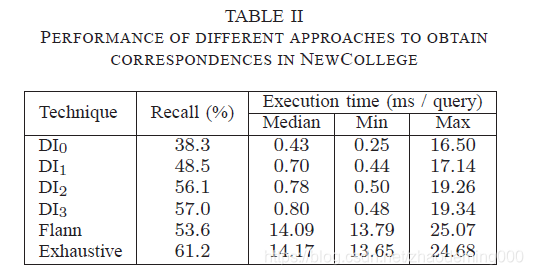
D Geometrical consistency几何一致性
取而代之的是,我们设置一个泛型值,并用一个几何约束来验证匹配,该几何约束包括在两个图像
I
t
I_t
It 和
I
t
′
I_{t'}
It′ 之间找到一个基本矩阵,它和一个循环关闭候选图像的基本矩阵。计算
I
t
I_t
It 和
I
t
′
I_{t'}
It′ 之间对应点是最消耗时间的。我们使用直接索引 和穷尽索引和基于Flann方法,计算对应关系比较我们的提案。词汇树用训练数据被创建,所以邻近搜索是基于独立数据的,kd-tree为每个
I
t
′
I_{t'}
It′ 被定制。
E Execution time 执行时间
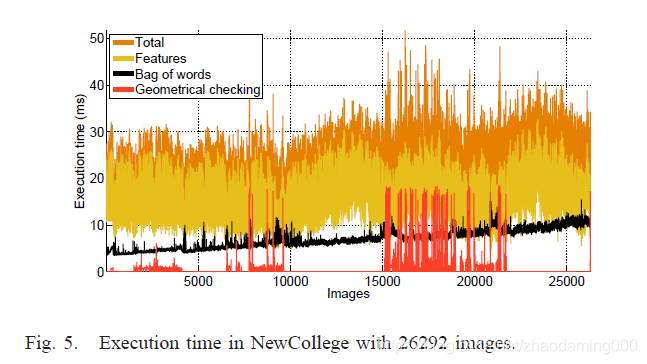
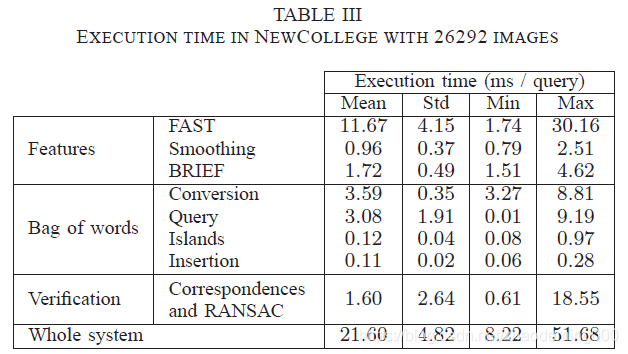
特征时间 包括计算FAST关键点和在有太多响应时去除那些具有轻微拐角响应的关键点,以及使用高斯核平滑图像和计算BRIEF描述符。
词袋时间 被分为四步:
1、图像特征转换为词袋向量;
2、数据库查询取回相似图像;
3、独立分包的创建和匹配;
4、当前图像插入到数据库中,涉及更新直接和逆索引;
确认时间 包括通过直接索引的方法计算匹配图像之间的对应关系和RANSAC循环计算基础矩阵;
当使用大型图像集合时,大词汇量可以提高计算时间。
另外,查询多于26K图像的数据库仅仅需要9ms,这表明这个步骤可以很好地与数万个图像缩放。几何验证在最坏的情况下表现出较长的执行时间,但正如我们在上一节中看到的,这种情况很少发生,而75%的情况所需的时间不到1.6ms。
我们可以在52ms内(平均22ms)可靠的对拥有26K图像的数据库进行回环检测。这相比于在基于SIFT或SURF的算法中需要300ms-700ms提升了一个数量级。此算法大约300ms执行完拥有4K图像的数据库的回环检测。
F Performance of the final system最终系统的性能
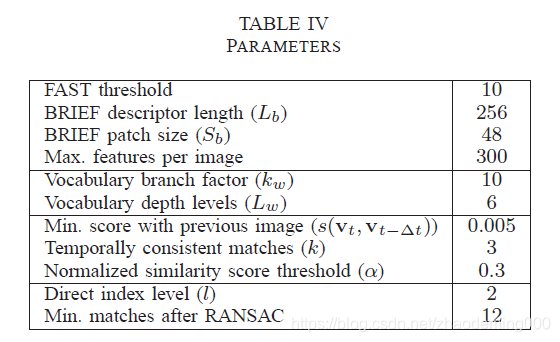
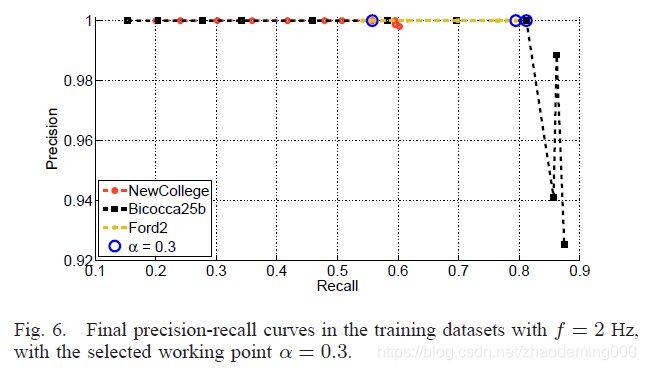
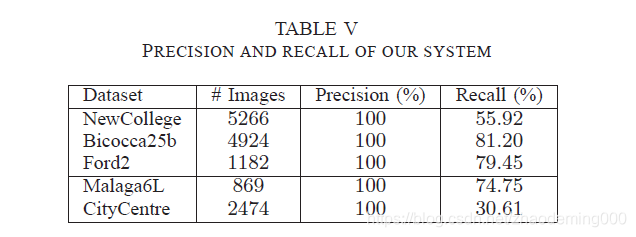
Table V 展示最终配置的曲线
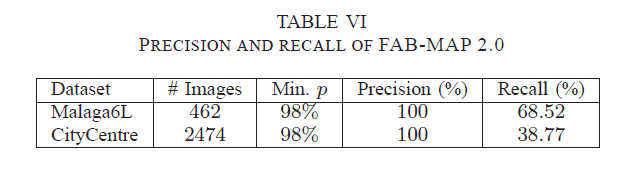
Table VI 展示在估计数据库中的表现。
Conclusions结论
提出一种新的算法在单目序列中进行回环检测。主要结论是二进制特征在词袋方法中是很高效、非常高效的。特别是,FAST+BRIEF特征和SURF(64维或128维无旋转不变性)用于解决平面相机运动中的回环探测问题一样可以信赖,如常用机器人。执行时间和存储器要求小一个数量级,而不需要特殊的硬件。
主要缺点是特征使用缺乏旋转和尺度不变性。这对于室内和城市机器人的位置识别来说已经足够了,但对于全地形或飞行器、仿人机器人、可穿戴摄像机或物体识别来说肯定还不够。我们对二进制词袋方法有效性的证明为使用新的和有前途的二进制特征铺平了道路,例如ORB[21]或BRISK[20],它们的性能优于SIFT和SURF的计算时间,保持旋转和尺度不变性。
[1] B. Williams, M. Cummins, J. Neira, P. Newman, I. Reid, and J. D. Tard´os, “A comparison of loop closing techniques in monocular SLAM,” Robotics and Autonomous Systems, vol. 57, pp. 1188–1197, December 2009.
[2] M. Cummins and P. Newman, “FAB-MAP: Probabilistic Localization and Mapping in the Space of Appearance,” The International Journal of Robotics Research, vol. 27, no. 6, pp. 647–665, 2008.
[5] P. Pini´es, L. M. Paz, D. G´alvez-L´opez, and J. D. Tard´os, “CI-Graph SLAM for 3D Reconstruction of Large and Complex Environments using a Multicamera System,” International Journal of Field Robotics, vol. 27, no. 5, pp. 561–586, September/October 2010.
[9] M. Calonder, V. Lepetit, C. Strecha, and P. Fua, “BRIEF: Binary Robust Independent Elementary Features,” in European Conference on Computer Vision, vol. 6314, September 2010, pp. 778–792.
[19] M. Calonder, V. Lepetit, P. Fua, K. Konolige, J. Bowman, and P. Mihelich, “Compact signatures for high-speed interest point description and matching,” in IEEE International Conference on Computer Vision,October 2010, pp. 357–364.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









