






1 Kafka基本概念
Producer(生产者):生产消息
Consumer(消费者):消费消息
Broker(节点):集群节点
Topic(主题):消息的分类
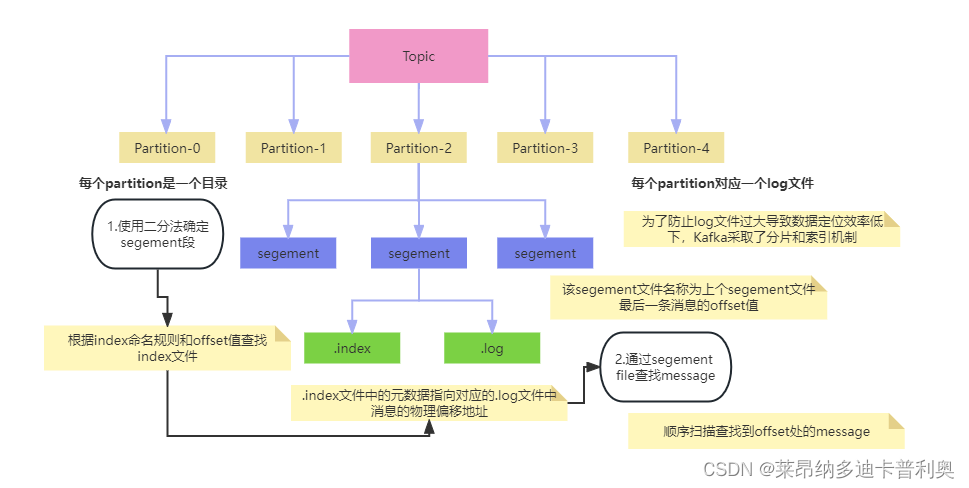
Partion(分区):每个topic有多个分区
Replication(副本):每个分区有多个副本,Leader副本和Follower副本,Leader副本负责数据的读写,Follower副本负责数据备份和故障转移
Segment(日志文件):每个副本对应一个Log日志,一个Log存储在不同的Segment中,每个Segment包含.log文件,位移索引文件.index和一个时间戳索引文件.timeindex 文件,每个Segment文件的命名规则包含上一个Segment文件最后一条消息的offset值。
Consumer Group(消费者组):每个消费者组对应一个Topic,一个消费者组包含多个消费者,同一个消费者组内的每个消费者消费同一个Topic不同分区的数据;一个消费者对应一个分区,当消费者大于分区数量时,剩下的消费者冗余,无法消费到数据。
Offset(偏移量):数据的索引值
Kafka存储机制
2 常用消息队列比较
(1)吞吐量:Kafka和Rocket大于Rabbit和ActiveMQ;
(2)时效性:Rabbit>Kafka>Rocket、ActiveMQ;
(3)可靠性:都有消息丢失的可能,可以通过参数优化避免;
(4)可用性:ActiveMQ和Rabbit基于主从架构,Kafka和Rocket支持分布式架构;
3 Kafka如何实现高效读写
1)顺序写入磁盘:在日志文件尾部追加,顺序写入且不允许修改。
2)页缓存:每次从磁盘中加载一页的数据到内存中这样可以减少IO次数。
3)零拷贝技术:只用将磁盘中的数据复制到页面缓存中一次,然后将数据从页面缓存中发送到网络中,避免了重复复制操作。
4 如何避免Kafka重复消费
重复消费原因:已经消费了数据但是offset偏移量没有提交;
例如:
a.消费系统宕机、重启,导致消费后的数据,offset没有提交;
b.设置offset为自动提交;此时Kafka 会保证在开始调用poll方法时,提交上次poll返回的所有消息,即poll方法的逻辑是先提交上一批消息的位移,再处理下一批消息,若此时集群发生异常很可能导致本次poll的数据的offset没有提交,下次消费时从此处再次拉取数据,导致重复消费;
解决a,b方法:设置offset自动提交为false
c.(处理数据时间过长,发生了重平衡)消费后的数据,当offset还没有提交时,partition就断开连接,比如,通常会遇到消费的数据,处理很耗时,导致超过了Kafka的session timeout时间(0.10.x版本默认是30秒),那么就会re-blance重平衡,此时有一定几率offset没提交,会导致重平衡后重复消费。
解决c方法:优化业务代码逻辑;适当增大max.poll.interval.ms的值;适当减小max.poll.records的值。
Kafka消费者有两个配置参数:
max.poll.interval.ms——两次poll操作允许的最大时间间隔。单位毫秒。默认值300000(5分钟)。
两次poll超过此时间间隔,Kafka服务端会进行rebalance操作,导致客户端连接失效,无法提交offset信息,从而引发重复消费。
max.poll.records——一次poll操作获取的消息数量。默认值50。 如果每条消息处理时间超过60秒,那么一批消息处理时间将超过5分钟,从而引发poll超时,最终导致重复消费。
5 如何避免Kafka数据丢失
(1)生产者发送消息丢失
解决办法:重试机制;
(2)存储消息时消息丢失
解决办法:保证数据写入主节点的同时至少写入两个副本;Kafka设置acks=all,即需要相应的所有处于ISR的分区都确认收到该消息后,才算发送成功。
具体设置:
给 topic 设置 replication.factor 参数:这个值必须大于 1,要求每个 partition 必须有至少 2 个副本(副本中只有一个leader副本可以提供服务,其他的都是follower)。
在 Kafka 服务端设置 min.insync.replicas 参数:这个值必须大于 1,这个是要求一个 leader 至少感知到有至少一个 follower 还跟自己保持联系,没掉队,这样才能确保 leader 挂了还有一个 follower 吧。
在 producer 端设置 acks=all:这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了。
在 producer 端设置 retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了。
(3)消费者消费时丢失
解决办法:在处理完业务后再给broker发送消费成功。
6 如何解决Kafka数据积压
数据积压原因:消费能力低于生产能力,生产的数据比消费者消费要快
解决办法:
增加消费者,一个分区对应一个消费者(消费者数量小于等于分区数量);
多线程处理数据;
把数据存入redis;
7 如何确保Kafka顺序消费
(1)发送消息时指定分区,将需要顺序消费的消息都存储在这个分区里,消费端从这个分区消费;同一个分区内的数据是有序的。
(2)在kafka里采用按键策略将消息保存到指定分区。在发送消息时指定key和postion,从而可以保证间隔有序。
8 Kafka的多分区多副本机制有什么好处
1)Kafka通过将特定topic指定到多个partition,各个partition分布到不同的Broker上,这样能够提供比较好的并发能力。
2)Partition可以指定对应的replica数,这也极大地提高了消息存储的安全性和容灾能力。
9 Zookeeper在Kafka集群中的作用
kafka通过zookeeper来管理集群,选举leader,zookeeper保存kafka的broker信息,分区信息,监控分区的leader副本等。
Broker注册:在Zookeeper上有个专门记录broker服务器列表的节点,每个broker启动时,都会在/brokers/ids下创建属于自己的节点,每个broker会将自己的IP地址和端口信息记录到节点上去。
Topic注册:同一个topic的消息会被分成多个分区并分布在多个broker上,这些分区和broker的对应关系也都是Zookeeper在维护,对应到Zookeeper中可能会创建文件/brokers/topics/my-topic/partitions/0,/brokers/topics/my-topic/partitions/1。
负载均衡:为了提供更好的并发能力,Kafka会尽力将同一个topic的partition分布到不同的broker,当Consumer消费的时候,Zookeeper可以根据当前的partition数量和Consumer数量进行动态负载均衡。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









