






 本文详细介绍MapReduce环境搭建、编程步骤,包括Mapper、Reducer编写及Driver设置,并探讨结果分析与优化策略,如combiner预聚合、数据倾斜解决方案。
本文详细介绍MapReduce环境搭建、编程步骤,包括Mapper、Reducer编写及Driver设置,并探讨结果分析与优化策略,如combiner预聚合、数据倾斜解决方案。
MapReduce学习笔记
图解MR(WC)
-
input
文件 -
split 分片
blocksize 默认128M在linux上
比如300M的一个文件,blocksize默认是128M
那么分成3个块
如果128.1MB,128M有buffer,缓冲大概为10%,其实是一个块 -
map
word => (word,1) key-value键值对 -
shuffle
洗牌(把牌归整到一块)
默认按照key的hash值进行分发
partitonerphone count
133xxxxxx
135xxxxxx
185xxxxxx
137xxxxxx
相同的key肯定要分发到同一个reduce任务上去,做最后的汇总操作 -
reduce
做归约汇总 这里对value做加法 -
result
输出成文件
对应的为output
最后为2个文件
_SUCCESS
part-0-0000

环境布置
如果想在windows系统下进行Hadoop MapReduce的编写以及调试运行需要对环境进行以下配置
-
IDEA下载
-
maven 推荐3.6.3
高版本的可能会出现安全问题,比如只能使用https
2.1 对本地maven的settings.xml文件进行配置
并改成阿里云镜像
配置环境变量MAVEN_HOME -
Windows需要本地配置hadoop,mac不需要
3.1 重新解压一份hadoop 然后将bin和etc目录copy下来,到自己新建Windows的hadoop文件夹下
修改etc/hadoop中的hadoop-env.cmd且JAVA_HOME需要改为绝对路径
如果你本地JAVA_HOME在C:\Program Files\...,需要改为
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0具体路径依据JAVA_HOME位置
3.2 网上找对应版本的hadoop.dll和winutil.exe,放在bin中,这个我也找了好久,如果像我hadoop版本为3.1.3的话用3.1.0的hadoop.dill和winutil.exe也可以运行
3.3 配置环境变量HADOOP_HOME 和JAVA_HOME,还有PATH
3.4 若还报错,把hadoop.dll放在C:\Windows\System32下
这里指的报错并不是指hadoop version报错,因为我们并不是需要在本地启动完整的hadoop所以只复制了bin和etc所以hadoop version一定是报错的
MR编程
所有的代码都可以在官网找到示例代码
官网
Mapper ==> org.apache.hadoop.mapreduce.Mapper
通过包内的Mapper可以了解到基本顺序
run
setup
循环调用map
cleanup
通过包内的Reudcer可以了解到基本顺序
Reducer ==> org.apache,hadoop.Reducer
run
setup
循环调用map
cleanup
Driver ==> 连接Mappeer 和 Reducer,提交为job
总体步骤大概分为四步
- input
- map=> Mapper
- reduce=>Reducer
- output
编写Mapper
package MR_wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Locale;
public class MRMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
IntWritable ONE = new IntWritable(1);
@Override
protected void setup(Context context) throws IOException, InterruptedException {
System.out.println("-------Mapper.setup-------");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.println("-------Mapper.map-------");
//将内容转化为小写
final String line = value.toString().toLowerCase();
//按照分隔符进行拆分
final String[] splits = line.split(" ");
//输出
for(String word : splits)
{
context.write(new Text(word),ONE);
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
System.out.println("-------Mapper.cleanup-------");
}
}
编写Reducer
package MR_wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MRReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
System.out.println("-------Reduce.setup-------");
}
/**
* mapper的输出= reducer的输入
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
System.out.println("-------Reduce.reduce-------");
int count = 0;
//对每个key进行聚合操作
for(IntWritable value:values)
{
count +=value.get(); //IntWriterable 转int ,用get方法
}
//输出
context.write(key,new IntWritable(count));
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
System.out.println("-------Reduce.cleanup-------");
}
}
编写driver
package MR_wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MRDriver {
public static void main(String[] args) throws Exception {
String input = "data/wc.txt";
String output = "out_MR_WC";
final Configuration configuration = new Configuration();
//获取job对象
final Job job= Job.getInstance(configuration);
//设置class
job.setJarByClass(MRDriver.class);
//设置Mapper和reducer
job.setMapperClass(MRMapper.class);
job.setReducerClass(MRReducer.class);
//设置Mapper阶段输出数据的key value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reducer阶段输出的key value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入输出路径
FileInputFormat.setInputPaths(job,new Path(input));
FileOutputFormat.setOutputPath(job,new Path(output));
//提交job
final boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
结果分析及优化
结果分析
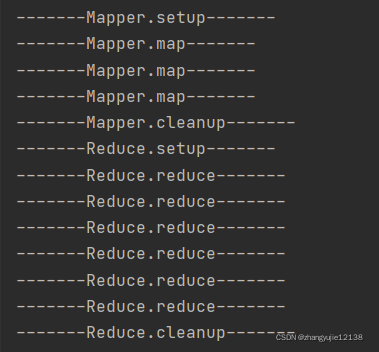
通过结果也可以得知其运行逻辑:
Mapper和Reducer中的setup和cleanup都只调用了一次
而对于map而言wc.txt里面有一行就是一个map(粗浅的认为)
对于reduce来说有几个结果就有几个reduce
简单优化
- 与在hdfs中运行后相同,如果想要再次运行这个程序会报错。
所以在我们编写一个程序使其能够在运行前将已经存在的output文件夹进行删除
package MR_wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileUtils {
public static void deleteTarget (Configuration configuration,String output) throws Exception
{
final FileSystem fileSystem = FileSystem.get(configuration);
final Path path = new Path(output);
if(fileSystem.exists(path))
{
fileSystem.delete(path,true);
}
}
}
将其加入Driver程序,这样就可以做到多次重复运行就可以了
但是我们还是能在日志中看到一些报错信息,但是最终输出的信息是exit 0那说明最终是运行成功的,我们去看那些报错信息可以发现是文件夹已存在一类的,我们就先不去管他了。
- 在进行结果查看的时候发现,日志仅为我们在Mapper和Reduce中输出的那几条,与阿里云上输出的详细的日志信息不同。
对此我们对log4j进行配置
log4j.rootLogger=DEBUG,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %5-p %c %x - %m%n
配置后在运行就能看到与阿里云上一样的日志信息了
打包到阿里云上运行
通过idea的打包功能将程序打包为jar包
-
File => project Structure
-
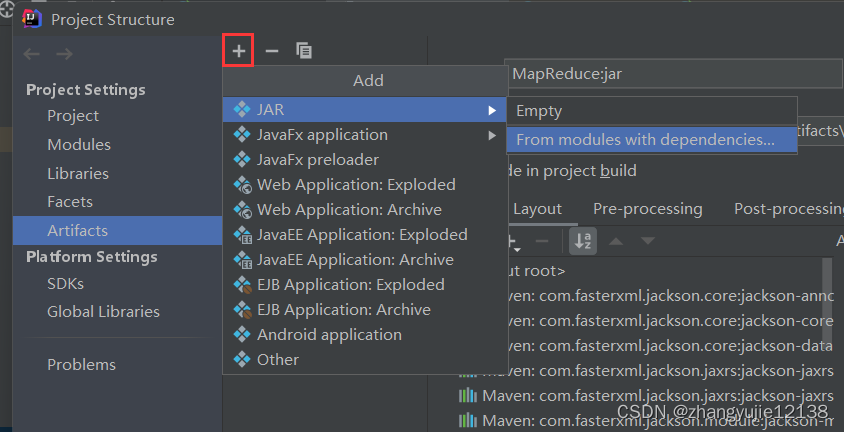
点击Artifacts,点击加号选择jar选择From modules with dependencies
-
选择Main Class以及META-INF的路径jar files选择下面一个
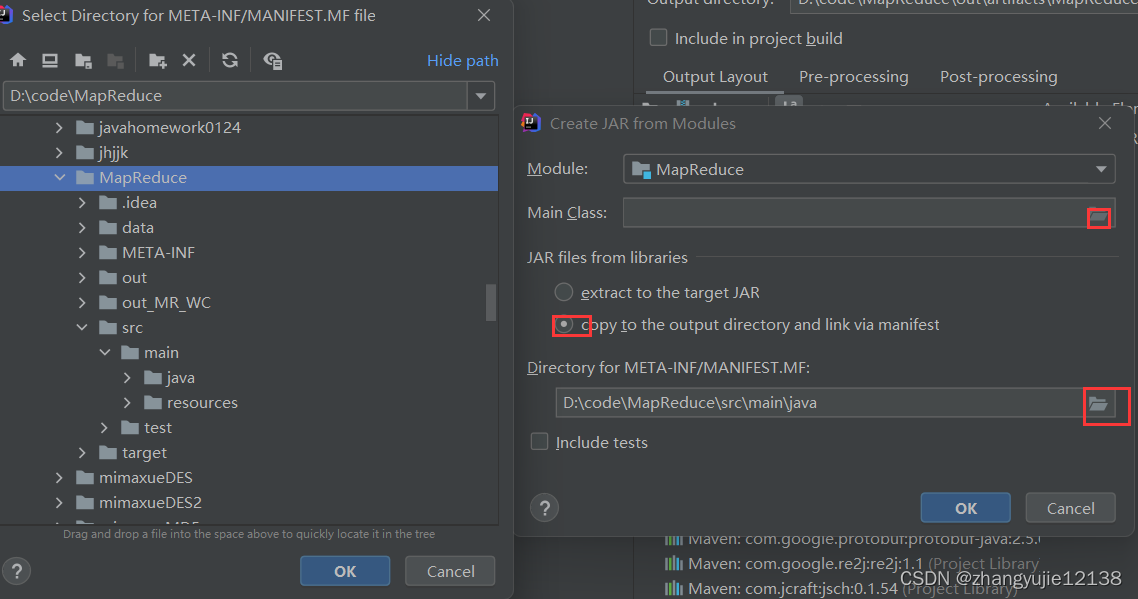
这里要注意,我的图上面为idea自动生成的路径,我尝试了很多次发现,并不能成功运行jar包
在查阅资料后发现,有些版本的idea使用默认路径是无法正常运行jar包的(也可能是我的运行问题),所以我把META-INF的路径放到根目录下,即与src同级。这样在我的版本上就可以成功运行jar包 -
之后点击build选择build Artifacts进行打包
-
连接阿里云将jar包上传到阿里云
这里我使用rz命令

-
使用
hadoop jar MapReduce.jar命令运行jar包
通过9527端口可以看到运行完成

查看9870端口也发现运行完成,文件出现

但是这里要注意,由于我写的代码中输入和输出路径是写死的,那么我们就需要保证在hdfs里面有相对应的路径。
简单拓展
combiner(预聚合)
介于map和reduce之间的一个reduce操作,但是运行在MapTask
默认是没有combiner的
没有增加combiner之前运行日志为
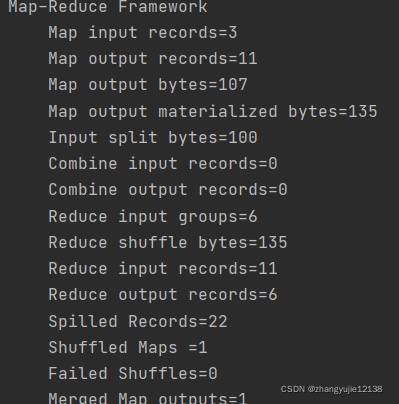
通过job.setCombinerClass方法添加combiner
job.setCombinerClass(MRReducer.class);
添加完后再运行发现shuffle变小了
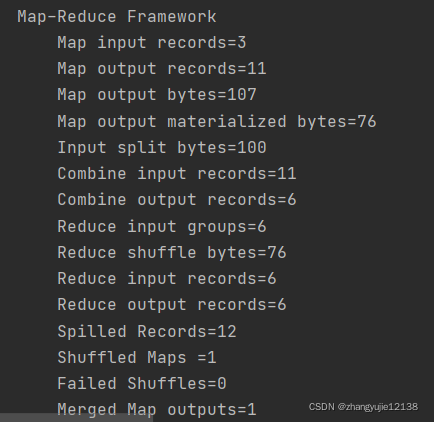
作用: 减少数据的网络传输,是一个非常重要的调优点
但是算平均数的时候不适合这个操作
数据倾斜
-
hadoop解决数据倾斜的方法(优化)
什么是数据倾斜?以及现象
比如一个文件a b c
a 1亿个
b 1个
c 1个
做wordcount
map1 99%
map2 100%
map3 100%
这种基本上就是数据倾斜的现象
1.1 combiner
a 1亿个 (a,1亿)
b 1个 (b,1)
c 1个 (c,1)
减少数据的网络传输
但是avg不适合,如果导致数据倾斜的key分布在很多不同 的文件,不同mapper,这种方式就不适合。
100个mapper 每个mapper里1万个a 优化力度不是很大,所以不是很适合
1.2 导致数据倾斜的key分布在很多不同的文件的时候
1.2.1 局部聚合+全局聚合
第一次map:对于导致数据倾斜的key,加上一个随机 数前缀
1_a 2_a 3_a …10_a
这样的话本来相同的key会被分成多个key类似于串行变成了并行
第二次map:去掉key的随机前缀,进行全局聚合
思想:2次MR,第一次将key随机散列到不同的reduce进行处理,达到负载均衡
第二次再根据去掉key的随机前缀,按照原本的key进行reduce处理
1.2.2 增加reduce数,提高并行度
job.setNumReduceTask(3);
本来就一个输出文件修改后变成3个输出文件
比如本来a,b,c只有三个reduce,现在我将reduce改成30个,也相当于处理a的reduce就到了
job.setNumReduceTasks(int);若int为0即
job.setNumReduceTask(0)会发生什么
设置成0之后redeuce没有输出了,直接将map的结果输出在文件中
设置的数字要合理不能太多
1.2.3 实现自定义分区
partitioner:按照某种规则(可以自定义)对map输出的数据进行分区操作
默认的是HashPartitioner
默认为job.setPartitionerClass(HashParition.class)
顺序:map=> partition =>reduce
根据数据分布情况(在非常熟悉数据的情况下),自定义散列函数,将key均匀分配到不同的reducer
-
shuffle优化 消耗网络资源,内存等
2.1 map端
2.1.1 减少输入的文件个数,对小文件进行合并
2.1.2 预聚合combiner2.2 I/O
数据传输时进行压缩2.3 reduce端
2.3.1 设置map reduce共存,
mapred-site.xml
mapreduce.job.reduce.slowstart.completemaps默认0.05
也就是说map在执行到5%的时候开始为reduce进行资源申请,开始执行reduce操作
2.3.2 尽量少用 reduce
reduce会产生大量的网络消耗,但是该用还是要用
2.3.3 增加reducer 提高并行度2.4 整体
2.4.1 合理的设置map数和reduce数
2.4.2 MR on yarn 可以对yarn进行参数调优
2.4.3 加配置(机器,内存) -
其他
3.1 是否可以只有map 没有reduce
可以
联系到我们sql中,where的实现逻辑就是只有map没有reduce3.2 是否可以只有reduce没有map?
第一印象是不可以
但是其实在hive中

















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









