



 本文深入解析MapReduce分布式计算框架的核心概念,包括数据分布式存储、作业调度与容错机制。阐述分而治之思想在大规模数据处理中的应用,详细介绍MapReduce计算流程,包括Map与Reduce阶段的工作机制。同时,探讨JobTracker与TaskTracker两大关键进程的作用。
本文深入解析MapReduce分布式计算框架的核心概念,包括数据分布式存储、作业调度与容错机制。阐述分而治之思想在大规模数据处理中的应用,详细介绍MapReduce计算流程,包括Map与Reduce阶段的工作机制。同时,探讨JobTracker与TaskTracker两大关键进程的作用。
1、简介
MapReduce是一个用于处理海量数据的分布式计算框架。这个框架解决了:
1.数据分布式存储
上一篇文章提到MapReduce自身是不存储数据的,数据都存取在HDFS上,计算的目标数据就是来自于HDFS。
2.作业调度
一个Hadoop集群上可以跑很多个MapReduce,不可能某一个MapReduce占了所有资源,资源是共享的。
3.容错
非个人因素导致的问题比如网络堵塞、机器间通信等复杂问题,会自动切换到其他节点上。
2、MapReduce分而治之思想
1、数钱实例:一堆钞票,各种面值分别多少
-单点策略
- 一个人数所有的钞票,数出各种面值有多少张
-分治策略
- 每个人分得一堆钞票,数出各种面值有多少种
- 汇总,每个人负责统计一种面值
2、解决数据可以切割进行计算的应用
- 分治思想
-分解
-求解
-合并
- MapReduce映射
-分:map
把复杂的问题分解为若干“简单的任务”
-合:reduce
3、MapReduce计算框架·执行流程(重点)
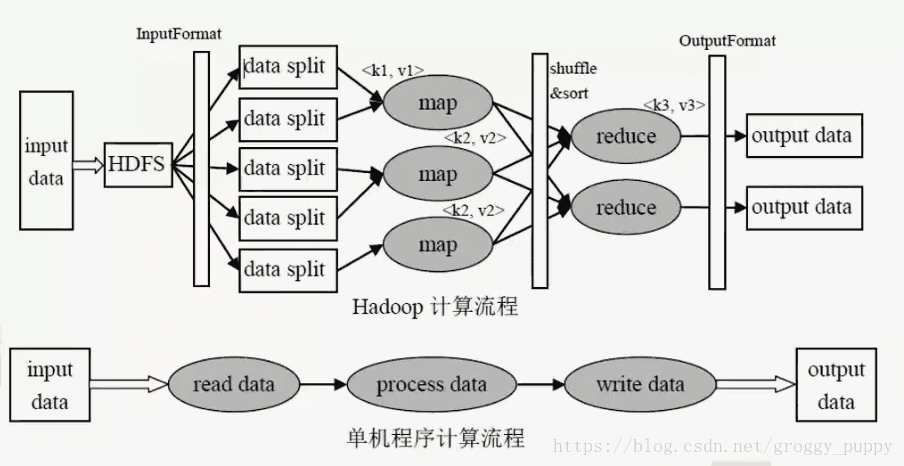
开发人员一般情况下需要关心的是图中灰色的部分。↑
Map和Reduce部分细节化↓:
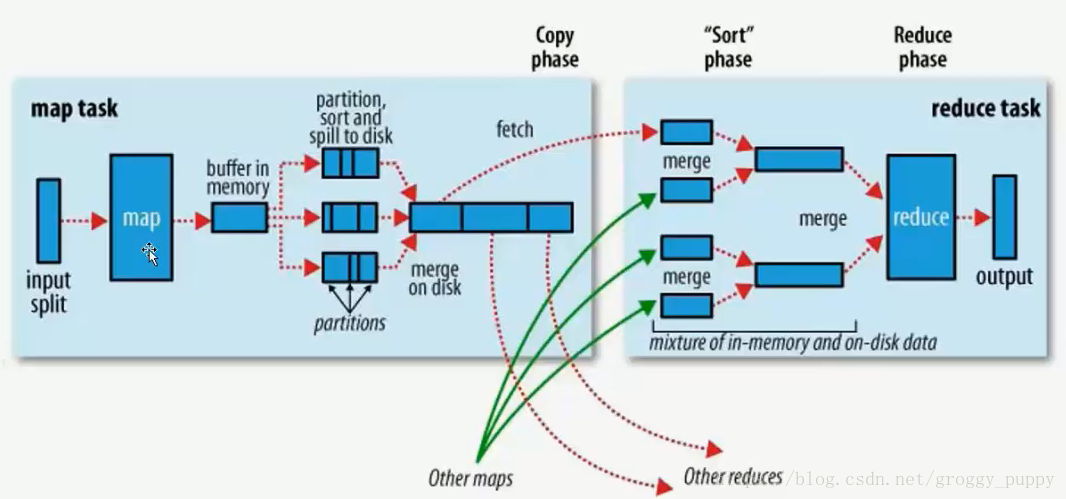
Map部分:
一个map实际上对应一个split分片,首先map读取split,因为map是一个程序,作为系统里面的一个进程,自己维护着一个进程空间。把split数据读进来之后直接存到了自己的内存上(buffer in memory),然后开始往内存写。内存默认大小为100M,但是100M很容易写满,当它写到80M的时候会锁住内存区,然后把这80%的数据转储到磁盘上,然后清理内存。转储的过程中会作排序(sort),图中partitions中三个部分相当于前面数钱的例子中面值的分类。三个小的数据部分再归并排序成大的数据(merge on disk)。途中只展示出一个Map的执行流程,还有other maps。
Reduce部分
还是数钱的例子,假设图中Reduce部分是负责处理一百元面值的,把每个Map上属于一百元区域的数据通过fetch红线全部归纳到Reduce机器上(相当于拷贝)。然后把从每个从Map拷贝过来的数据两两合并,再统一交给Reduce处理,最后输出。
4、两个重要的进程
-JobTracker
- 主进程,负责接收客户作业提交,调度任务到作节点上运行,并提供诸如监控工作节点状态及任务进度等管理功能,一个MapReduce集群有一个JobTracker,一般运行在可靠的硬件上。
- TaskTracker是通过周期性的心跳来通知JobTracker其当前的健康状态,每一次心跳包含了可用的Map和Reduce任务数目、占用的数目以及运行中的任务详细信息。JobTracker利用一个线程池来同时处理心跳和客户请求。
-TaskTracker
- 由JobTracker指派任务,实例化用户程序,在本地执行任务并周期性地向JobTracker汇报状态。在每一个工作节点上永远只会有一个TaskTracker。
-JobTracker一直在等待用户提交作业
-TaskTracker每隔3秒向JobTracker发送心跳询问有没有任务可做,如果有,让其派发任务给它执行
-Slave主动向Master拉生意

















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









