




 本文全面探讨Redis的六种数据结构,包括SDS、quicklist、intset、hasttable、ziplist和skiplist。此外,详细介绍了Redis的五种数据类型及其用途,如String、List、Set、Sorted Set和Hash。讨论了Redis的速度优势、过期删除策略、淘汰策略、持久化方式(RDB和AOF)以及如何应对缓存问题。最后,涉及了Redis的高可用方案、发布与订阅、事务和位数组以及HyperLogLong等高级特性。
本文全面探讨Redis的六种数据结构,包括SDS、quicklist、intset、hasttable、ziplist和skiplist。此外,详细介绍了Redis的五种数据类型及其用途,如String、List、Set、Sorted Set和Hash。讨论了Redis的速度优势、过期删除策略、淘汰策略、持久化方式(RDB和AOF)以及如何应对缓存问题。最后,涉及了Redis的高可用方案、发布与订阅、事务和位数组以及HyperLogLong等高级特性。
目录
Redis六种数据结构
通过 object encoding key可以查看key的数据结构
127.0.0.1:6379> object encoding test
"quicklist" SDS
Redis中创建了一种名为简单动态字符串(Simple Dynamic String,SDS) 作为字符串的默认数据结构。

SDS特点
- 获取字符串长度的时间复杂度为O(1)
- 杜绝缓冲区溢出
- 减少因修改字符串长度时所需的内存分配次数
- 二进制安全
quicklist

链表特点
链表被广泛用于实现Redis各种功能,比如发布与订阅等;他的主要特点有:
- 每个链表节点有一个ListNode结构表示,每个节点都有一个指向前置节点和后置节点的指针,所以Redis的链表是双端链表
- 每个链表使用一个list结构表示,这个结构有表头指针、表尾指针以及长度信息等
- 链表头节点的前置节点为null链表的尾节点的后置节点都指向NULL,所有Redis链表是无环链表
intset

hasttable

ziplist

skiplist

Redis五种数据类型
Redis是一种高级的key-value非关系内存数据库,支持五种数据类型:
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | 缓存 |
| Hash(字典) | 键值对集合,即编程语言中的Map类型 | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List(列表) | 链表(双向链表) | 增删快,提供了操作某一段元素的API | 1,最新消息排行等功能(比如朋友圈的时间线) 2,消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 1、添加、删除,查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 | 1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合) | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经进行天然排序 | 1、排行榜 2、带权重的消息队列 |
String
String是Redis常用的数据类型,典型使用场景有 缓存对象、常规计数以及分布式锁
常见命令
| 命令 | 作用 | 示例 |
| set | 用于给指定的key 设置指定值 | 127.0.0.1:6379> set message "hello word" ex 1000 OK |
| get | 获取指定key的值 | 127.0.0.1:6379> get message "hello word" |
| incr | 自增 | 127.0.0.1:6379> incr number (integer) 2 |
| incrby | 按照指定步长进行自增 | 127.0.0.1:6379> incrby number 3 (integer) 5 |
| decr | 自减 | 127.0.0.1:6379> decr number (integer) 4 |
| decrby | 按照指定步长自减 | 127.0.0.1:6379> decrby number 3 (integer) 1 |
| strlen | 获取指定key的值的长度 | 127.0.0.1:6379> strlen message (integer) 10 |
| append | 向指定key的值追加数据 | 127.0.0.1:6379> append message " redis" (integer) 16 127.0.0.1:6379> get message "hello word redis" 127.0.0.1:6379> |
| getrange | 按照指定范围从指定key中获取数据 | 127.0.0.1:6379> GETRANGE message 0 5 "hello " |
| setrange | 将字符串特定索引上的值设置为指定的数据 | 127.0.0.1:6379> set message "hello word" OK 127.0.0.1:6379> setrange message 6 "redis" (integer) 11 127.0.0.1:6379> get message "hello redis" |
List
列表在Redis中实现上不是使用数据而是使用链表。典型使用场景是消息队列

常见命令
| 命令 | 含义 | 示例 |
| lpush | 将一个或多个值插入到列表头 | 127.0.0.1:6379> lpush mylist "hello" (integer) 3 |
| rpush | 将一个或多个值插入到列表尾部 | 127.0.0.1:6379> rpush mylist "hello" "word" "hello" "redis" (integer) 4 |
| lpop | 移除并返回列表的第一个元素 | 127.0.0.1:6379> lpop mylist "hello" |
| rpop | 移除并返回列表最后一个元素 | 127.0.0.1:6379> rpop mylist "redis" |
| lindex | 通过索引获取元素 | 127.0.0.1:6379> lindex mylist 0 "hello" |
| Llen | 返回列表长度 | 127.0.0.1:6379> llen mylist (integer) 3 |
| linsert | 在列表的元素前后插入新元素,如果指定元素不存在则不执行任何操作,如果列表不存在时候视为空列表不执行任何操作 | 127.0.0.1:6379> lrange mylist 0 -1 1) "hello" 2) "word" 3) "hello" 127.0.0.1:6379> Linsert mylist after "hello" "redis" (integer) 4 127.0.0.1:6379> lrange mylist 0 -1 1) "hello" 2) "redis" 3) "word" 4) "hello" |
| lrange | 返回列表中指定区间的元素 | 127.0.0.1:6379> lrange mylist 0 -1 1) "hello" 2) "word" 3) "hello" |
| lrem | 根据参数count值移除列表中于参数value个数相等的元素 | 127.0.0.1:6379> lrange mylist 0 -1 1) "hello" 2) "redis" 3) "word" 4) "hello" 127.0.0.1:6379> lrem mylist -2 "hello" (integer) 2 127.0.0.1:6379> lrange mylist 0 -1 1) "redis" 2) "word" 127.0.0.1:6379> |
数据结构
列表的数据结构为quicklist.
127.0.0.1:6379> rpush test "hello" "word" "test"
(integer) 3
127.0.0.1:6379> object encoding test
"quicklist" Set
适合用于集合的交集、并集等操作,典型使用场景是朋友关系
常见命令
| 命令 | 说明 | 示例 |
| sadd | 向集合中添加一个或多个元素 | 127.0.0.1:6379> sadd numbers 1 3 5 (integer) 3 |
| scard | 查询集合中元素的数量 | 127.0.0.1:6379> scard numbers (integer) 4 |
| sismember | 判断指定值是否是在集合中 | 127.0.0.1:6379> sismember numbers unkown (integer) 1 |
| srandmember | 随机返回一个或多个元素 | 127.0.0.1:6379> srandmember numbers 2 1) "unkown" 2) "5" |
| spop | 移除并返回集合中的一个或多个随机元素 | 127.0.0.1:6379> spop numbers 1 1) "5" |
| srem | 从集合中删除指定元素 | 127.0.0.1:6379> SREM numbers 1 (integer) 1 |
| smemebers | 返回集合中所有元素 | 127.0.0.1:6379> SMEMBERS numbers 1) "unkown" 2) "3" |
数据结构
集合对象的编码可以是intset或者是hashtable.
127.0.0.1:6379> sadd numbers 1 3 5
(integer) 3
127.0.0.1:6379> object encoding numbers
"intset"
127.0.0.1:6379> sadd numbers "unkown"
(integer) 1
127.0.0.1:6379> object encoding numbers
"hashtable"
127.0.0.1:6379> 什么时候使用intset
当集合对象同时满足以下两个条件时使用intset
- 集合中保存的所有元素都是整数值
- 集合中保存的整数元素个数不超过512个
Sorted Set
典型shi yong
常见命令
| 命令 | 说明 | 示例 |
| zadd | 将一个或多个元素及其分数值天价到有序集合中 | 127.0.0.1:6379> zadd testSet 1 "hello" 2 "world" (integer) 2 |
| zcard | 返回有序集合中元素个数 | 127.0.0.1:6379> zcard testSet (integer) 2 |
| zcount | 统计有序集合中指定分数区间的元素个数 | 127.0.0.1:6379> zcount testSet 1 2 (integer) 2 |
| zrange | 返回有序集合中指定区间的成员 | 127.0.0.1:6379> zrange testSet 1 2 1) "world" 2) "bar" |
| zrevrange | 倒叙返回有序集合中指定区间的成员 | 127.0.0.1:6379> ZREVRANGE testSet 1 2 1) "world" 2) "hello" |
| zrank | 返回有序集合中元素的排名 | 127.0.0.1:6379> zrank testSet "world" (integer) 1 |
| zincrby | 对有序集合中元素的分数自增指定步长 | 127.0.0.1:6379> ZINCRBY testSet 2 "world" "4" |
| zrem | 删除有序集合中一个活多个元素 | 127.0.0.1:6379> zrem testSet "world" (integer) 1 |
| zscore | 查询有序集合成员元素的分值 | 127.0.0.1:6379> ZSCORE testSet "hello" "1" |
数据结构
有序集合编码可以是ziplist 或 skiplist.
Hash
常见命令
| 命令 | 说明 | 示例 |
| hset | 为哈希表中的字段赋值 | 127.0.0.1:6379> hset book name "Think in Java" (integer) 1 |
| hget | 获取哈希表中指定字段的值 | 127.0.0.1:6379> hget book name "Think in Java" |
| hmset | 同时保存多个key-value键值对 | 127.0.0.1:6379> hmset book "author" "unkown" "date" "2020" OK |
| hmget | 通过获取多个指定字段的值 | 127.0.0.1:6379> hmget book "name" "author" 1) "Think in Java" 2) "unkown" |
| hexists | 用户查询哈希表的指定字段是否存在 | 127.0.0.1:6379> HEXISTS book "dora" (integer) 0 127.0.0.1:6379> HEXISTS book name (integer) 1 |
| hdel | 用于删除哈希表中一个或多个指定字段 | 127.0.0.1:6379> hdel book "date" (integer) 1 127.0.0.1:6379> hdel book "date" (integer) 0 |
| hlen | 获取哈希表中键值对的个数 | 127.0.0.1:6379> hlen book (integer) 4 |
数据结构
哈希对象的编码可以是ziplist或hashtable
什么时候使用ziplist
当哈希同时满足以下两个条件时使用ziplist
- 哈希对象保存的所有键和值的字符串长度都小于64个字节
- 哈希对象保存的键值对数量小于512
不满足上述两个条件的都是用hashtable.
为什么Redis这么快
- 基本上是纯内存操作
- 查询以及操作时间复杂度多是O(1)
- 数据结构简单
- 单线程操作,避免上下文切换以及竞争条件(多核CPU可以部署多实例充分利用CPU资源)
Redis过期删除策略
- 惰性删除策略- 惰性删除策略是指当我们查下key的时候,对key进行检查,如果key已经过期则删除;这个策略存在一个明显的问题就是如果这个 key一直不被访问就永远不会被删定期删除策略
- 定期删除是指redis每隔一段时间随机选择一部分key进行一次检查,删除过期的key
Redis淘汰策略
如果缓存没有设置过期时间或其他场景没有被过期策略删除,导致redis缓存使用达到一定阈值会触发redis淘汰策略。
1.volatile-lru 从设置过期时间的key中,移除最近最少使用的key
2.volatile-ttl 从设置过期时间的key中,移除最近将要过期的key
3.volatile-random 从设置过期时间的key中,随机选择key进行移除
4.allkeys-lru 从所有的key中,移除最近最少使用的key
5.allkeys-random 从所有的key中,随机选择key移除
6.noevication 不过期处理,直接抛出异常
Redis持久化方式有哪些
redis支持RDB和AOF两种持久化方案
RDB
RDB持久化可以配置为定期执行,她的作用是将某个时间点上的数据库状态保存到RDB文件中,RDB文件是一个压缩到二进制文件,可以通过它恢复到某个时刻到数据库状态。由于RDB文件是保存在磁盘上的,即使Redis服务崩溃或退出,只要有RDB文件,就可以使用它来恢复还原数据。
SAVE命令会阻塞redis进程,直到RDB文件生成完毕,在进程阻塞期间,redis不能处理任何命令请求,着显然在生产环境中是不合适的。
BGSAVE 则是fork出一个子进程负责生产RDB文件,父进程继续处理命令请求不会阻塞进程
AOF
AOF 和 RDB 不同,AOF是通过保存redis服务器所执行的命令来记录数据库状态。AOF通过追加、写入、同步三个步骤来实现持久化
1.当AOF持久化处于激活状态、服务器执行写命令后,写命令会追加到aof_buf缓冲区的末尾
2.服务器每结束一个事件循环之前,会调用flushAppendOnlyFile来决定是否要将aof_buf的内容保存到AOF文件中,通过参数appendfysnc配置,可取三种值:always、everysec和no。
always- aof_buf内容同步写入到AOF文件,always最安全,只会丢失一次事件循环的写命令,但是性能较差
everysec 每隔一秒同步一次,默认是每秒同步一次,
no 同步事件有操作系统决定
RDB与AOF的优缺点
AOF保证数据不会丢失,作为数据恢复的首选项,RDB用来做不同程度的冷备,是Redis默认持久化方式
RDB优点
- 只有一个文件dump.rdb,方便持久化
- 容灾性好,一个文件可以方便保存到安全磁盘
- 性能最大化,fork子进程来持久化写操作,让主进程继续处理命令
RDB缺点
- 数据安全性低,RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障可能会丢失数据
AOF优点
- 数据安全性高,AOF可以配置appendfsync未always;即使中途宕机也可以通过redis-check-aof工具来解决数据一致性问题
AOF 缺点
- AOF文件过大,恢复速度慢,数据集较大时,比Redis启动效率低
Redis缓存可能存在问题
缓存击穿
缓存击穿是指单个key在高并发访问一下,因为缓存过期导致大量请求直接打到DB
解决方案
1.加锁更新,如果缓存过期时候,针对key进行加分布式锁,只有获得锁的线程才能更新缓存,未获取锁的线程延迟读取,如果延迟读取不到直接返回空
2.不过期缓存,
缓存穿透
缓存穿透是指查询的数据不在缓存中,每次请求都会打到DB。比如根据商品ID查询商品信息,如果有用户构造了一个不存在的商品Id去查询,此时发现缓存没有就直接查询DB
解决方案
1.针对这个问题可以增加一层布隆过滤器,当请求过来时,只有通过布隆过滤器的才会查下缓存
缓存雪崩
当某一刻发生集中缓存时效导致大量请求打到DB,直接导致DB服务不可用,进而导致整个系统崩溃。
解决方案:
1.限流
2.针对不同的key设置不同的过期时间,避免同时过期
Redis高可用方案
Sentinel
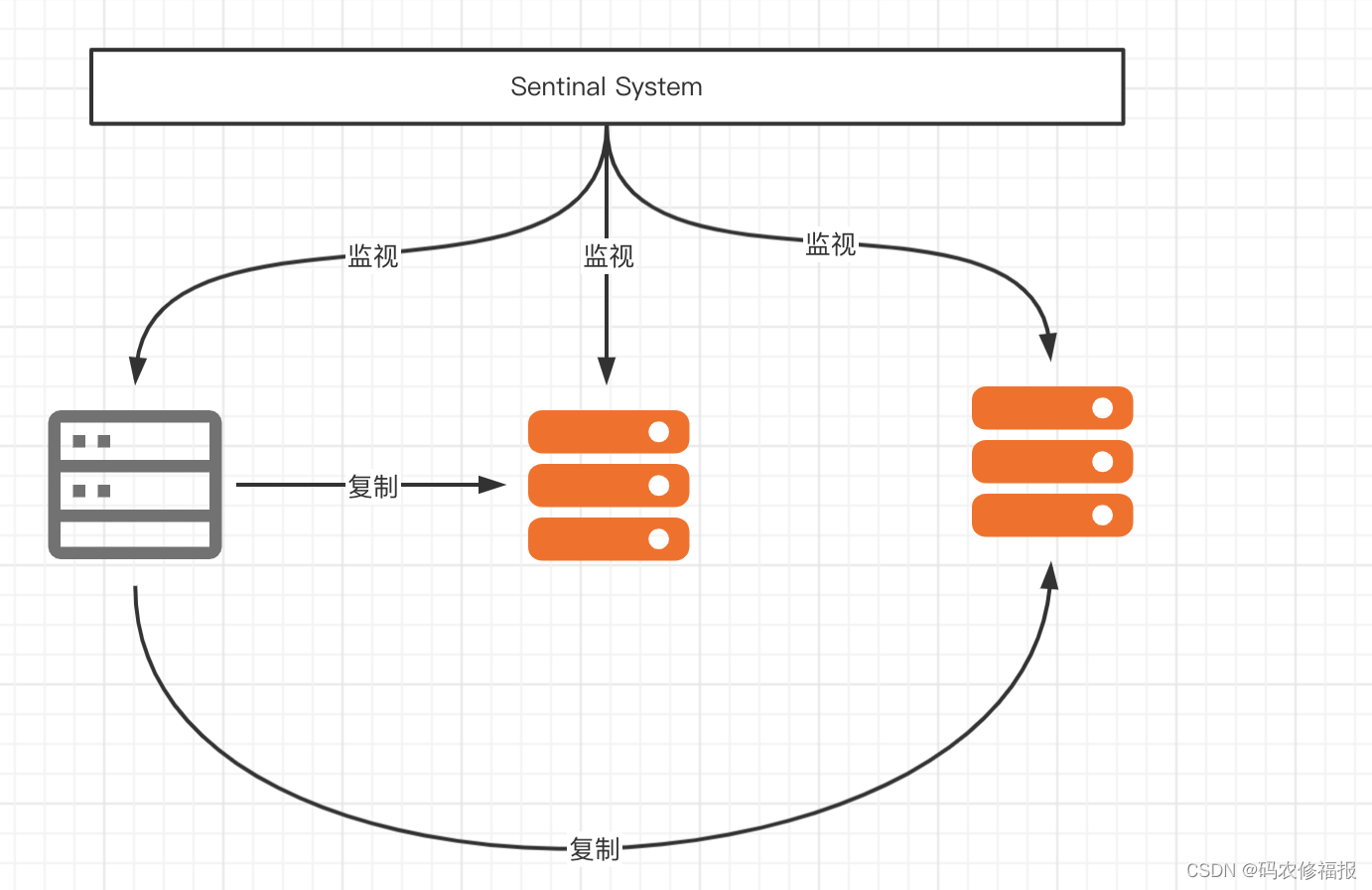
哨兵模式是Redis高可用(HA)的一种解决方案:由一个或多个Sentinal Instance 组成的Sentinal System可以监视任意多个主服务器和它的从服务器;在被监视的主服务器进入下线状态时,自动从slave节点中选择一个作为主服务器
Cluster
集群是Redis提供了分布式数据库方案,通过分片(sharding)来进行数据共享,并提供复制和故障转移功能;一个Redis Cluster 由多个节点(node)组成。
Redis Cluster 被分为16384个slot.数据库中任意一个键都只属于16384个slot中的一个;集群中的一个节点可以处理0到16384个slot.当16384个slot都处于在线状态时集群状才是可用状态,相反任意一个slot不是在线状态,集群就处于下线状态
MOVE
Redis集群中的16384个slot分配给集群中的各个节点,每个节点都会就自己负责处理的slot,哪些slot指派给了其他节点。节点在接受到一个命令请求时,首先检查这个命令要处理的键值对是否在自己负责的slot,如果不是则向客户端返回MOVE信息,并携带可以正确处理命令的节点;客户端收到MOVE信息后,根据引导数据进行重试
ASK
在接收到客户端请求后,如果发现当前源节点正在迁移slot,则客户端返回ASK
发布与订阅
订阅
客户端通过执行subscribe命令,订阅一个或多个频道从而成为这个频道的订阅者;当其他客户端向这个频道发送消息时,订阅者会收到这条消息
127.0.0.1:6379> SUBSCRIBE "topnews"
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "topnews"
3) (integer) 1
退订
客户端通过执行unsubscribe命令对一个或多个频道退订
127.0.0.1:6379> UNSUBSCRIBE "topnews"
1) "unsubscribe"
2) "topnews"
3) (integer) 0发布消息
客户端通过执行publish命令向指定的频道发布消息 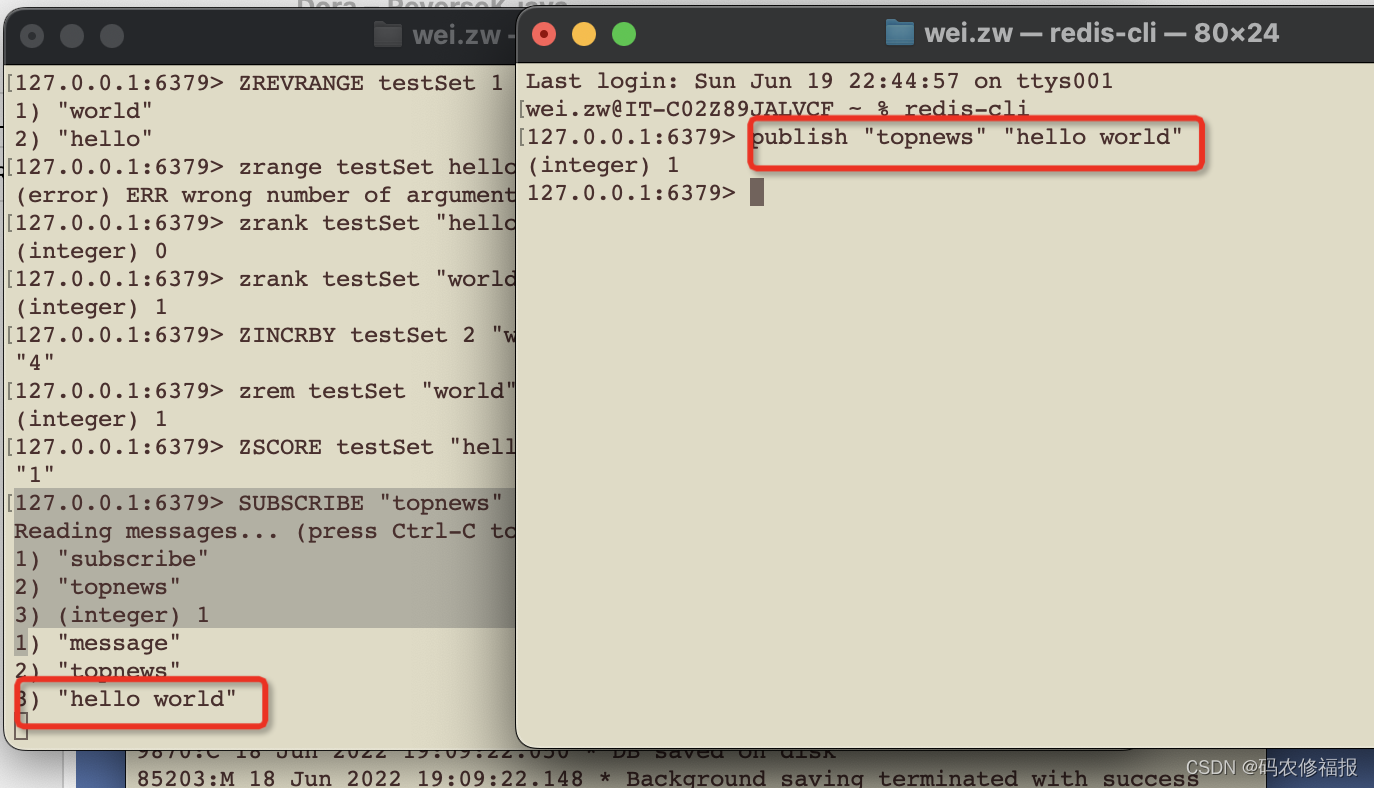
事物
事物就是提供一种一次性,按照顺序执行多个命令的功能;Redis通过multi, exec, watch等命令来实现事物功能。
事务的实现
一个事物从开始到执行结束通常可以分为三个阶段:
- 事物开始
- 命令入队
- 事物执行
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set "count" 1
QUEUED
127.0.0.1:6379(TX)> set "amount" 100
QUEUED
127.0.0.1:6379(TX)> DECR store
QUEUED
127.0.0.1:6379(TX)> EXEC
1) OK
2) OK
3) (integer) -1
127.0.0.1:6379> WATCH
watch命令是一个乐观锁,它可以在exec命令执行之前,监视任意数量的数据,在在exec命令执行时,检查被监视数据是否至少有一个被修改过,如果是则服务器拒绝执行事物。
位数组
Redis提供了setbit ,getbit, bitcount,bitop 四个命令用于处理二进制位数组。bitmap非常适合用于二值统计的场景,比如布隆过滤,用户签到等场景
127.0.0.1:6379> setbit a 3 1
(integer) 0
127.0.0.1:6379> setbit a 1 1
(integer) 0
127.0.0.1:6379> setbit b 2 1
(integer) 0
127.0.0.1:6379> setbit b 1 1
(integer) 0
127.0.0.1:6379> getbit a 1
(integer) 1
127.0.0.1:6379> getbit a 2
(integer) 0
127.0.0.1:6379> getbit a 3
(integer) 1
127.0.0.1:6379> getbit b 1
(integer) 1
127.0.0.1:6379> getbit b 2
(integer) 1
127.0.0.1:6379> bitop and and-result a b
(integer) 1
127.0.0.1:6379> bitcount and-result
(integer) 1
127.0.0.1:6379> getbit and-result 1
(integer) 1HyperLogLong
HyperLogLong是Redis2.8.9版本新增的数据类型,是一种用于“统计基数”的数据集合类型,它是基于概率的统计规则,是一种不精确的去重统计。典型的使用场景是统计百万级网页的UV,它只需要12KB内存就可以计算2^64个元素。
127.0.0.1:6379> pfadd www.cathy.com:uv zhansan lisi wangwu
(integer) 1
127.0.0.1:6379> pfcount www.cathy.com:uv
(integer) 3

















 168万+
168万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











