



摘自林轩田机器学习技法
(1)计算一个样本点到一个平面的距离,样本x到超平面的距离就可以表示为
WT∥W∥(x−x′)=1∥W∥(WTx+b)
\frac{W^T}{\lVert W \lVert}(x-x')=\frac{1}{\lVert W \lVert}(W^Tx+b)
∥W∥WT(x−x′)=∥W∥1(WTx+b)
(2)本来只需要
WTx+b≥0或者WTx+b≤0
W^Tx+b\geq0或者W^Tx+b\leq0
WTx+b≥0或者WTx+b≤0
现在变成了
WTx+b≥1或者WTx+b≤−1
W^Tx+b\geq1或者W^Tx+b\leq-1
WTx+b≥1或者WTx+b≤−1
(3)SVM和正则化的关系
| xx | 最小化 | 限制 |
|---|---|---|
| 正则化 | EinE_{in}Ein | WTW≤CW^TW\leq CWTW≤C |
| SVM | WTWW^TWWTW | Ein=0E_{in}=0Ein=0 |
(4)SVM表现结果好的原因
特征转换可以得到复杂的平面,使得模型有更强的分类能力,但是会使VC维变大
SVM通过限制胖胖的边界使得VC维减小
dvc(Aρ)≤min(R2ρ2,d)+1≤d+1d_{vc}(A_{\rho}) \leq min(\frac{R^2}{\rho^2},d)+1 \leq d+1dvc(Aρ)≤min(ρ2R2,d)+1≤d+1
附上matlab程序
clc;
clear all;
close all;
%QP求解支持向量机
addpath(genpath(pwd));
[data,label,K] = NewDataSet(1);%读取数据集
[Data] = data_standard(data);%数据集各维度属性归一化
data=data(1:100,:);
label=label(1:100);
label(51:100)=label(51:100)-3;
Y=label;
X=data;
[m,n] = size(X);
H = eye(n);
H = [zeros(1,n);H];
H = [zeros(n+1,1) H];
p = zeros(n+1,1);
%不等式约束
A = - repmat(Y,1,n+1).*[ones(m,1) X];
b = -ones(m,1);
%优化起始点
u0=rand(5,1);
%求解支持向量机
[w,val] = quadprog(H,p,A,b,[],[]);
%预测
predict=[ones(m,1) X]*w;
(5)为什么要讲SVM的对偶问题?
我们通过特征转换将样本转换到高维空间,需要解的变量会比较多,是否可以使得变量的个数固定
| 原始SVM | 对偶SVM |
|---|---|
| d+1个变量 | N个变量 |
| N个变量 | N+1个变量 |
对偶svm的思路,是先将上面的有限制性的QP问题转换成没有限制的QP问题
minb,w(maxαL(b,w,α))
\mathop{min}\limits_{b,w}(\mathop{max}\limits_{\alpha} L(b,w,\alpha))
b,wmin(αmaxL(b,w,α))
然后将最小最大化转换成最大最小化
minb,w(maxαL(b,w,α))≥maxα(minb,wL(b,w,α))
\mathop{min}\limits_{b,w}(\mathop{max}\limits_{\alpha} L(b,w,\alpha)) \geq \mathop{max}\limits_{\alpha}(\mathop{min}\limits_{b,w} L(b,w,\alpha))
b,wmin(αmaxL(b,w,α))≥αmax(b,wminL(b,w,α))
最终把b和w都消掉,变成了关于aplha的优化问题,优化变成了N*N,这只与样本的个数有关,但是注意对偶问题的Q矩阵很大,所以才有了SMO解法。
(6)SVM和PLA的关系
Wsvm=∑nαnynzn
W_{svm}=\sum _ n \alpha_{n}y_{n}z_{n}
Wsvm=n∑αnynzn
Wpla=∑nβnynzn W_{pla}=\sum _ n \beta_{n}y_{n}z_{n} Wpla=n∑βnynzn
这说明模型参数都可以用资料表示出来,SVM用支撑向量SV来表示模型参数
PLA用当前已分错误样本表示模型参数
(7)注意边界上的点,不一定都是支持向量,只有alpha大于0的样本才是支持向量。
(8)核技巧
g(x)=sign(wTϕ(x)+b)=sign(∑n=1NαnynK⋅n+b)
g(x)=sign(w^T \phi(x)+b)=sign(\sum_{n=1}^N \alpha_{n}y_{n}K_{ \cdot n} +b)
g(x)=sign(wTϕ(x)+b)=sign(n=1∑NαnynK⋅n+b)
b=ys−wTzs=ys−∑n=1NαnynK(xn,xs)
b=y_{s}-w^T z_{s}=y_{s}-\sum_{n=1}^N \alpha_{n}y_{n}K(x_{n},x_{s})
b=ys−wTzs=ys−n=1∑NαnynK(xn,xs)
多项式核
KQ(x,x′)=(ξ+γxTx)Q
K_{Q}(x,x_{'})=( \xi + \gamma x^Tx)^Q
KQ(x,x′)=(ξ+γxTx)Q
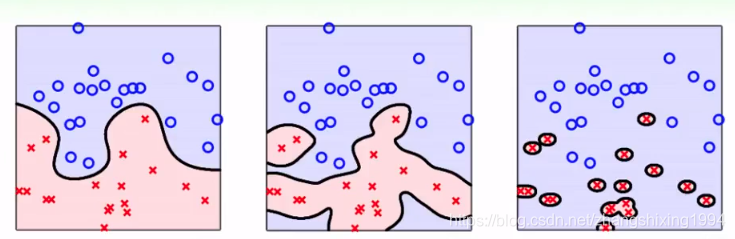
gamma不能取太大
clc;
clear all;
close all;
%自定义核函数
%1 在单位圆内生成一组随机点。将第一和第三象限中的点标记为属于正类,将第二和第四象限中的点标记为属于负类。
rng(1); % For reproducibility
n = 100; % Number of points per quadrant
r1 = sqrt(rand(2*n,1)); % Random radii
t1 = [pi/2*rand(n,1); (pi/2*rand(n,1)+pi)]; % Random angles for Q1 and Q3
X1 = [r1.*cos(t1) r1.*sin(t1)]; % Polar-to-Cartesian conversion
r2 = sqrt(rand(2*n,1));
t2 = [pi/2*rand(n,1)+pi/2; (pi/2*rand(n,1)-pi/2)]; % Random angles for Q2 and Q4
X2 = [r2.*cos(t2) r2.*sin(t2)];
X = [X1; X2]; % Predictors
Y = ones(4*n,1);
Y(2*n + 1:end) = -1; % Labels
figure;
gscatter(X(:,1),X(:,2),Y);
title('Scatter Diagram of Simulated Data')
%2 训练数据时,进行了标准化
Mdl1 = fitcsvm(X,Y,'KernelFunction','mysigmoid1','Standardize',true);
%3 绘制边界
% Compute the scores over a grid
d = 0.02; % Step size of the grid
[x1Grid,x2Grid] = meshgrid(min(X(:,1)):d:max(X(:,1)),...
min(X(:,2)):d:max(X(:,2)));
xGrid = [x1Grid(:),x2Grid(:)]; % The grid
[~,scores1] = predict(Mdl1,xGrid); % The scores
figure;
h(1:2) = gscatter(X(:,1),X(:,2),Y);
hold on
h(3) = plot(X(Mdl1.IsSupportVector,1),...
X(Mdl1.IsSupportVector,2),'ko','MarkerSize',10);
% Support vectors
contour(x1Grid,x2Grid,reshape(scores1(:,2),size(x1Grid)),[0 0],'k');
% Decision boundary
title('Scatter Diagram with the Decision Boundary')
legend({'-1','1','Support Vectors'},'Location','Best');
hold off
%计算样本样本外方差
CVMdl1 = crossval(Mdl1);
misclass1 = kfoldLoss(CVMdl1);
misclass1
function G = mysigmoid1(U,V)
% Sigmoid kernel function with slope gamma and intercept c
gamma = 0.5;
c = -1;
G = tanh(gamma*U*V' + c);
end
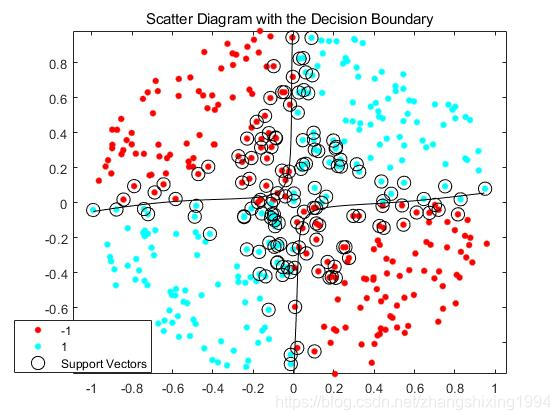
(9)选择核函数的原则
如果想要简单的边界,就选用线性核Linear,缺点选参数比较困难,大Q不是很好用
如果想要复杂的边界,就选用高斯核Gauss,太powerful容易过拟合
其实核函数是一种相似性
K=ZZT=[z1,z2,⋯ ,zN]T[z1,z2,⋯ ,zN]
K=ZZ^T=[z_{1}, z_{2} ,\cdots,z_{N}]^T[z_{1}, z_{2} ,\cdots,z_{N}]
K=ZZT=[z1,z2,⋯,zN]T[z1,z2,⋯,zN]
(10)放松的SVM
这是允许有犯错的的,但是要区分小错和大错,选择把错误记录下来
12wTw+C∑n=1Nξn
\frac{1}{2}w^Tw+C\sum_{n=1}^N \xi_{n}
21wTw+Cn=1∑Nξn
yn(wTzn+b)≥1−ξn
y_{n}(w^Tz_{n}+b) \geq1-\xi_{n}
yn(wTzn+b)≥1−ξn
ξn≥0
\xi_{n} \geq 0
ξn≥0
C大一些说明容许犯错少,C大一些说明允许犯错大。
对于sv一共分为两类
(1)0<αn<C 0<\alpha_{n}<C0<αn<C
这是自由支持向量,没有犯错正好在边界上
(2)αn=C\alpha_{n}=Cαn=C
这是在margin内的支持向量,但是这也分两种情况
(2.1)0<ξn<10<\xi_{n}<10<ξn<1这是没有犯错的
(2.2)1<ξn<21<\xi_{n}<21<ξn<2这是分类错误的
(11)选核函数的参数
应该选支持向量少的模型,因为根据留一法,样本内的误差为Eloocv≤svNE_{loocv} \leq \frac{sv}{N}Eloocv≤Nsv
(12)逻辑回归和svm的关系
损失函数不同,svm的损失函数max(1−ys,0)max(1-ys,0)max(1−ys,0)
逻辑回归的损失函数为max(1+exp(ys)) max(1+exp(ys))max(1+exp(ys))
核svm近似z空间的逻辑回归
(13)svm的软输出
综合svm和逻辑回归的特性,将svm的预测比作新的特征
(A(wsvmϕ(x)+bsvm)+B)(A(w_{svm}\phi(x)+b_{svm})+B)(A(wsvmϕ(x)+bsvm)+B)
(14)什么时候w可以写成资料的线性组合
带有L2正则化的线性模型
(15)SVR这个是回归
min12wTw+C∑n=1N(ξn↓+ξn↑) min \frac{1}{2}w^Tw+C \sum_{n=1}^N(\xi_n^\downarrow+\xi_n^\uparrow) min21wTw+Cn=1∑N(ξn↓+ξn↑)
−ϵ−ξn↓≤yn−wTzn−b≤ϵ+ξ↑,ξn↓≥0,ξn↑≥0
-\epsilon-\xi_n^\downarrow \leq y_{n}-w^Tz_{n}-b \leq \epsilon+\xi^\uparrow,\xi_n^\downarrow \geq0,\xi_n^\uparrow\geq0
−ϵ−ξn↓≤yn−wTzn−b≤ϵ+ξ↑,ξn↓≥0,ξn↑≥0
SVR是稀疏模型,用的
err(y,s)=max(0,∣s−y∣−ϵ)作为误差
err(y,s)=max(0,|s-y|-\epsilon)作为误差
err(y,s)=max(0,∣s−y∣−ϵ)作为误差
最终的解为w=∑n=1Nβnzn,其中β=(λI+K)−1yw=\sum_{n=1}^N \beta_{n}z_{n},其中\beta=(\lambda I+K)^{-1}yw=n=1∑Nβnzn,其中β=(λI+K)−1y这是N∗*∗N的
原始的w=(λI+xTx)−1xTyw=(\lambda I+x^Tx)^{-1}x^Tyw=(λI+xTx)−1xTy这是d∗*∗d的
| LIBLINEAR | LIBSVM |
|---|---|
| SVM | 核SVM |
| 线性ridge回归 | SVR |
| 逻辑回归 | 概率svm |

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









