






 在探讨梯度算法及其变种时,我们常遇到步长参数α_t的选择难题。即使α_t发散,也不能直接推导出梯度范数的收敛。本文通过一个反例说明,直接从步长发散推断梯度收敛的逻辑并不成立。
在探讨梯度算法及其变种时,我们常遇到步长参数α_t的选择难题。即使α_t发散,也不能直接推导出梯度范数的收敛。本文通过一个反例说明,直接从步长发散推断梯度收敛的逻辑并不成立。
在证明关于梯度算法等一系列算法的时候,我们总会得到类似如下情形的结果
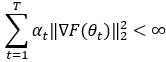
对于α_t,我们通常设置为1/t或1/√t,有时也会这设置α_t使其满足
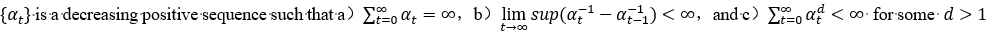
但我们并不能直接通过α_t发散来得到梯度范数收敛
下面我们给出反例:
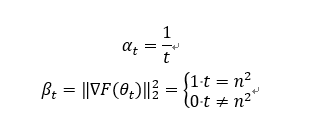
故我们无法直接得到梯度收敛的结论

















03-16
 6122
6122
6122
07-25
1534
1534
02-08
3220
3220
04-07
4830
4830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









