







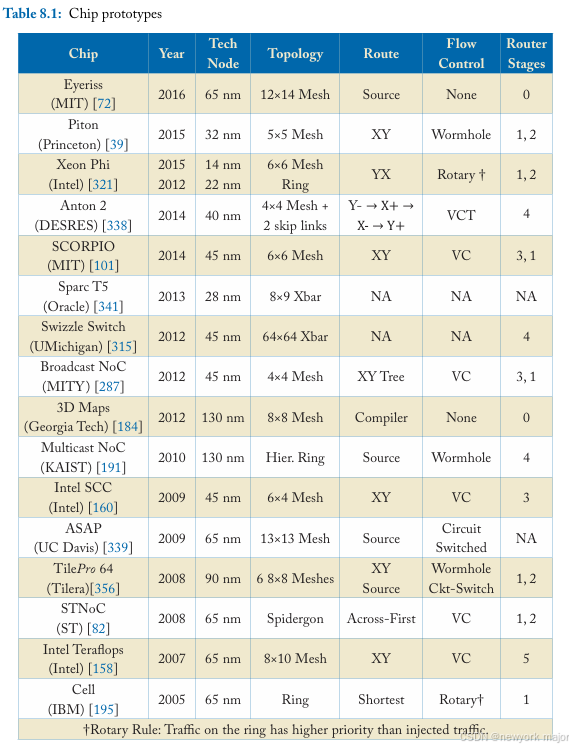
在过去十年中,片上网络一直在推动商业产品和研究原型中真正的多核芯片的发展。我们在这里讨论其中的一些案例研究,重点关注它们互连的系统和设计规范。我们重点介绍拓扑、路由算法、流量控制和 路由器微架构,并将这些设计与前面章节中介绍的基本概念联系起来;但是,在某些情况下,关于这些芯片的公开信息有限,因此对它们的处理可能不完整。表8.1总结了本章讨论的所有芯片的功能。案例研究 按时间顺序排列,从最新的开始。
MIT EYERISS(2016)
麻省理工学院的Eyeriss ASIC是深度卷积神经网络(deep convolutional neural networks)的加速器,通过多个片上网络连接168个处理单元。卷积神经网络(cnn)在基于视觉的机器学习任务(如目标识别和检测)中表现出前所未有的准确性。
Eyeriss is part of an emerging trend of accelerator IPs,与通用内核相比,它可以提供数量级的performance and energy benefits。推动这一趋势的部分原因是
- 由于Dennard’s scaling的限制而导致性能扩展的结束
- the dark silicon problem,即芯片的晶体管数量超过系统在任何时间点的完全供电能力,以及
- 新类别的应用的出现,如深度学习,需要大量并行大数据处理。例如,CNN的计算复杂度来自高维卷积操作(即乘法累加),占运算的90%以上。
Eyeriss由168个pe构成,它们之间直接通信,而不是通过内存,自然需要片上网络。然而,由于CNN每一层的通信模式都是已知的apriori,因此使用了具有configurable switche的轻量级NoC,而不是本书迄今为止描述的general-purpose NoC。The NoC and PEs are configured before the start of each layer.
- The diephoto of Eyeriss is shown in Figure 8.1a。Eyeriss有一个全局SRAM缓冲区(GB),它对input feature maps(ifmap)进行multicats,并filter weights to a set of PEs。
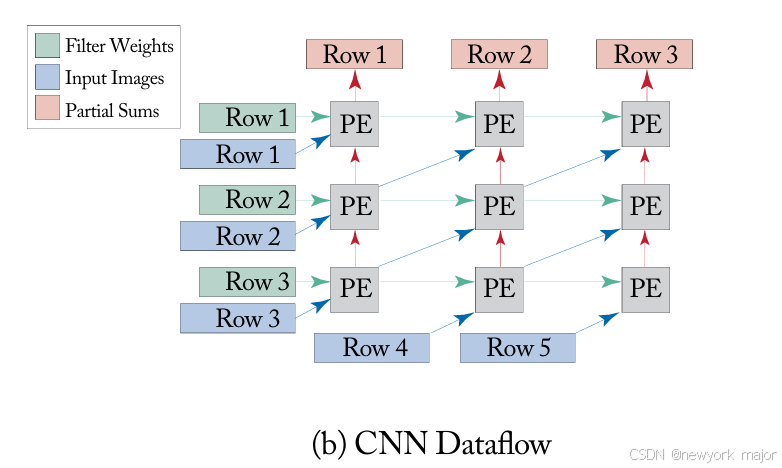
- logical dataflow如图8 - 1b所示:filter weights are multicast along the row,ifmaps are multicast along the diagonal。每个PE产生的部分和(psum)被发送到immediate neighbor above.
- 根据映射到array上的logical dataflow的cut or folded方式,以及filters的大小,multicast pattern可能不是统一的。然而,它在每个CNN层运行期间都是静态的。
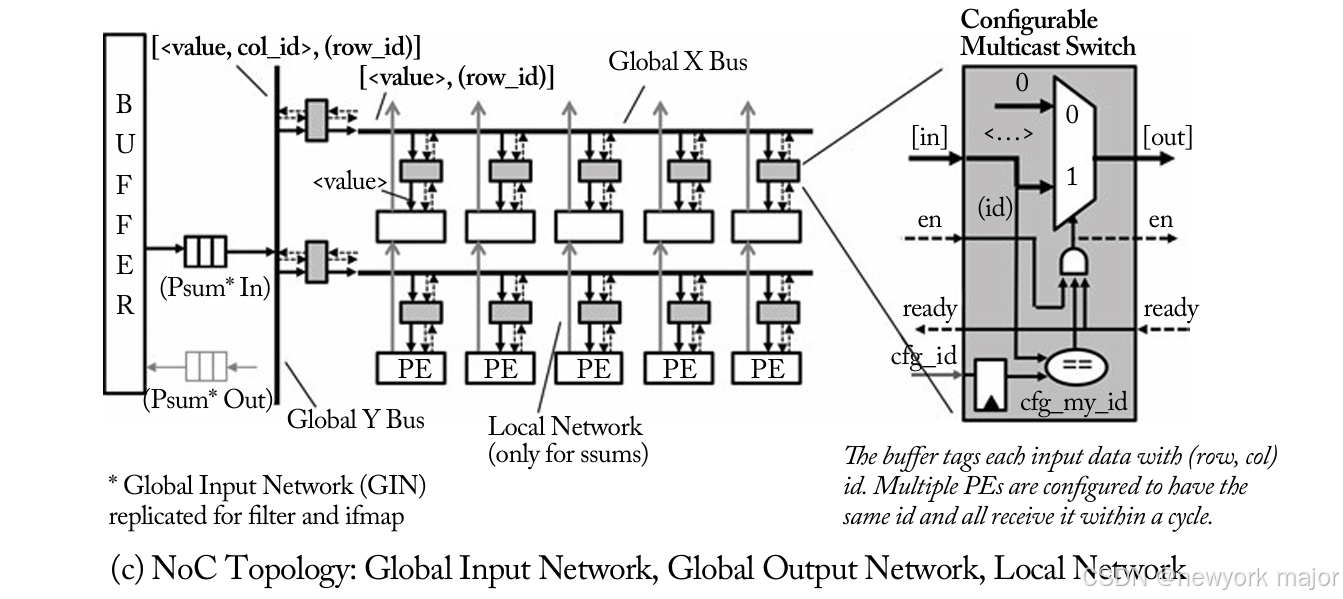
- The Eyeriss NoC comprises three separate networks, shown in Figure 8.1c.
a. Global Input Network (GIN)
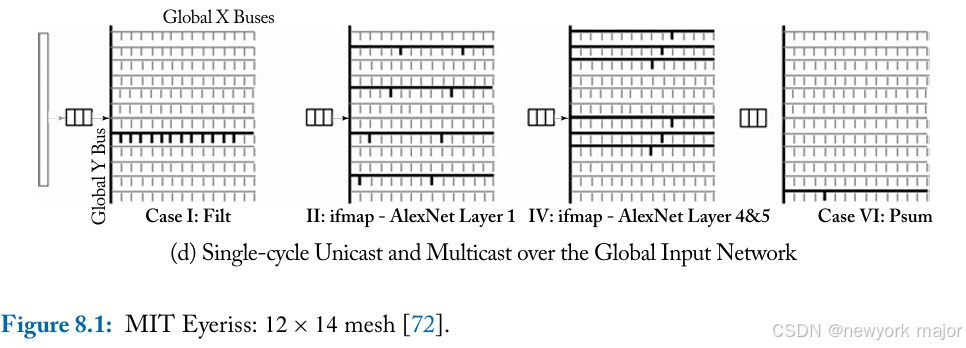
- The GIN is optimized for a single-cycle multicast from the GB to a group of PEs that receive the same filter, ifmap, or psum.
- The GIN is built using one Y bus and 12 X buses, one per row.
- A separate GIN is implemented for each of the three data types (filter, ifmap and psum) in order to provide sufficient bandwidth from the GB to the PE array.
- The filter and psum GIN have a bus width of 64 b to deliver 4 contiguous words to a PE in a cycle.
- The ifmap GIN has the data bus width of 16 b
b. Global Output Network (GON)
- The GON has the same architecture as the GIN, except that it is used for reading psums from PEs and sending them to the GB
c. Local Network (LN)
- The LN is a set of point-to-point Y-directional links between the PEs for transfer of psums.
这些networks在逻辑上构成了一个14× 12的mesh topology。mesh中的x-link用于将数据从global buffer发送到pe, Y-link用于pe之间的本地通信。除了数据之外,GIN和GON还有一个5位的tag字段。PE可以从psum GIN或LN得到它的输入psum。the selection在一层内是静态的,由scan chain configuration bits控制,only depends on the dataflow mapping of the CNN shape。
在Eyeriss中,任意两个通信实体(GB到PE、PE到GB、PE到PE)之间都有一条路由。来自GB的multicasts使用从root(即Y总线)到leaf pe的树。pe使用local Y link 向neighbor发送psum,或者使用GON上的X总线与GB通信。这是静态配置的。
在multicast过程中,所有需要接收相同数据(filter或ifmap)的pe在配置阶段都配置了相同的ID。GB用接收pe的ID标记(tags)每条multicast message。GIN上的所有switches/ controllers 将数据multicast到那些id与标签匹配的PEs。multicast takes a single-cycle. 如图8 - 1所示。
On-off flow-control is used。只有当所有pe都有可用的缓冲区时,GIN才会发出multicast。Delivery to a subset of PEs is not allowed。在GON上,GB设置它想从tag字段中接收的PE的id。只有这个PE才允许发送psum。与接收filter和ifmap的pe不同,生成sum输出的pe有唯一的id,因此不会发生冲突。因此,网络中的任何全局总线都不需要仲裁,因为在任何时间点都只有一个发送者。
NoC中的switch是可配置且无缓冲的。它们的作用只是在标签匹配时将数据传递出去。图8 - 1c展示了微架构。

















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









