







在过去15年中,单核处理器计算机芯片已让位于多核芯片。这些多核和众核系统已成为计算机系统的主要组成 部分,标志着我们设计和构建这些系统的方式发生了重大转变。
未来性能的提升将依赖于消除处理器与内存组件之间的通信瓶颈,这些内存组件为这些高带宽的多核设计提供数据。execution units或cores之间的高效通信将日益成为提高多核芯片性能的关键因素。
此处我们主要讨论如下三种主要的architecture。
- shared-memory chip multiprocessors (CMPs) in high end servers and embedded products
- message passing systems
- multiprocessor SoCs (MPSoCs) in the mobile consumer market.
CMPS
- SMP 英文为Symmetric Multi-Processing ,是对称多处理结构的简称,是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构,一个服务器系统可以同时运行多个处理器,并共享内存和其他的主机资源。
- CMP 英文为Chip multiprocessors,指的是单芯片多处理器,也指多核心。其思想是将大规模并行处理器中的SMP集成到同一芯片内,各个处理器并行执行不同的进程。
- 有点类似于:
- SMP是板上多插槽安装了多个芯片,每个芯片中只封装了一个CPU核心;
- CMP则是在一块芯片上封装两个或者多个CPU核心。
- 原文链接:https://blog.youkuaiyun.com/GarlanLouis/article/details/117448111
Parallel programming极其困难,但已变得越来越重要。随着多核架构的出现,并行硬件现已广泛用于各种commodity systems。并行系统的日益普及需要越来越多的并行应用程序。
维护globally shared address space可减轻程序员编写高性能并行代码的一 些负担。这是因为推断全局地址空间比推断分区地址空间更容易。partitioned global address multiprocessor space (PGAS) 在现代SMP 设计中很常见,其中高位地址位选择内存地址与哪个socket相关联。
相比之下,message passing paradigm明确地在node和address space之间移动数据,因此程序员必须明确管理communications。在具有分区地址空间的不同共享内存节点之间利用消息传递(例如 MPI)的混合方法在大规模并行处理架构中很常见。 我们将讨论的重点放在共享内存CMP上,因为人们普遍认为它们是未来几年主要的多核架构;
与SMP一样,CMP通常具有共享的全局地址空间;但与SMP不同的是,CMP可能表现出非均匀的内存访问延迟;
使用共享内存模型,communication通过load和store of data以及访问指令隐式地发生。因此,共享内存模型是实现这种共享的直观方法。
- 从逻辑上讲,所有处理器都访问相同的共享内存,从而使每个处理器都可以看到最新的数据。
- 实际上,内存层次结构使用缓存来提高共享内存系统的性能。这些缓存层次结构减少了访问数据的延迟,但使共享内存范例中保存的逻辑统一内存视图变得复杂。
- 因此,缓存一致性协议旨在在存在多个缓存数据副本的情况下为所有处理器维护内存的一致性视图。
- 缓存被设计为对程序员透明。它们通过将经常访问的数据保存在靠近处理器的位置来提高性能,但程序员不承担管理它们的责任。
- 这种透明度在多处理器系统中也是可取的;但是,如果同一地址的不同版本可以同时驻留在多个位置,则多个缓存的存在可能会导致正确性问题。
- 缓存一致性协议旨在解决这一挑战,而不会增加程序员的负担。缓存一致性协议维护single-writer, multiple-reader invariant。缓存一致性协议管理对共享数据的访问,使得一次只有一个处理器可以写入缓存 行。多个处理器可以同时读取缓存行而不会出现任何问题。
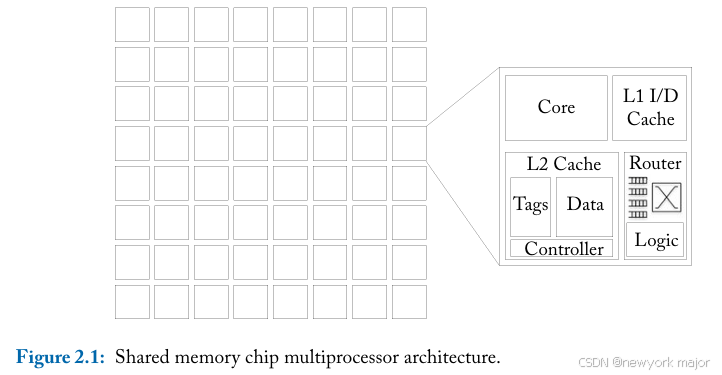
图2.1描绘了一个由 64 个节点组成的典型共享内存多处理器。一个节点包含a processor, private level 1 instruction and data caches and a second level cache。除了二级缓存之外,芯片上还可以集成第三级缓存。 第三级缓存通常由芯片上的所有处理器共享。
处理器到network interface和router充当本地块和其他片上组件之间的gateway。 共享内存多处理器的两个关键特性决定了它对互连的要求:
- the cache coherence protocol(确保节点接收到缓存行的正确最新副本);
- 和cache hierarchy;
一致性协议对网络性能的影响
Cache coherence protocols typically enforce a single-writer, multiple-reader invariant.
任意数量的节点都可以缓存内存副本以供读取;如果某个节点希望写入该内存地址,则必须确保没有其他节点缓存该地址;共享内存多处理器的通信要求包括数据请求、数据响应和一致性权限。节点必须先获得一致性权限,然后才能读取或写入缓存块。根据缓存一致性协议,其他节点可能需要响应权限请求。
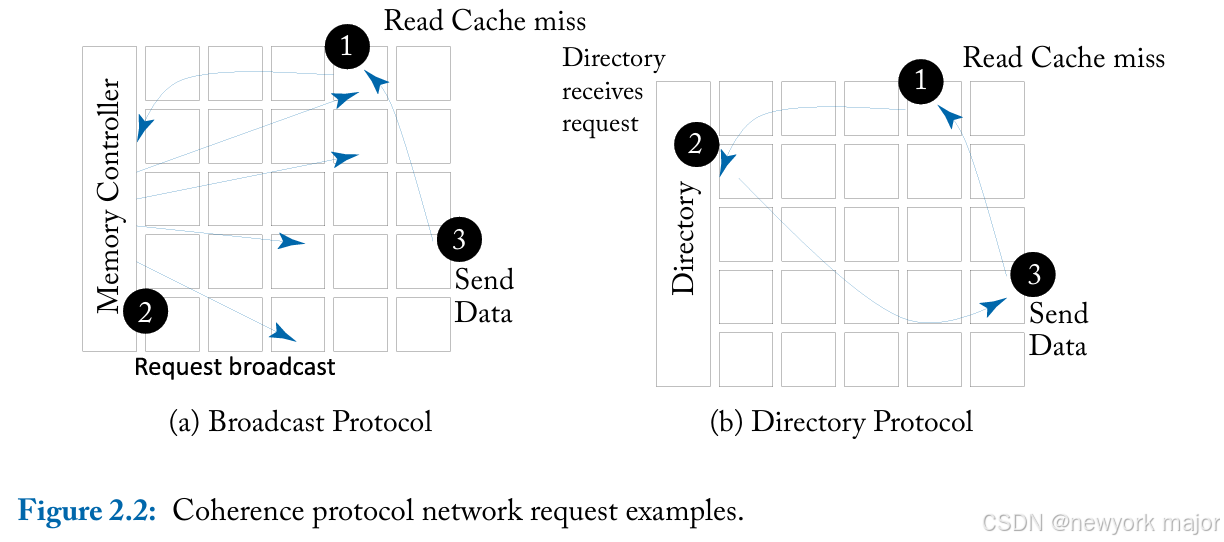
多处理器系统通常依赖于两种不同类型的一致性协议之一:broadcast or directory,如图2.2 所示。每种类型的 协议都会产生不同的网络流量特征。这里我们重点介绍这些一致性协议的基础知识,讨论它们如何影响网络要求。有关一致性的更深入讨论,我们请读者参阅其他文本;
- 使用广播协议,一致性请求会发送到芯片上的所有节点,从而对带宽要求较高。数据响应具有点对点性质,不需要协议进行任何ordering;广播系统可以依赖两个物理网络:
- one interconnect for ordering and a higher bandwidth;
- unorderedinterconnectfordatatransfers;
- 或者:
- 可以使用多个虚拟通道来确保 ordering among coherence traffic;
- requests and responses can flow through independent virtual channels;
- 图2.2a显示了导致缓存未命中的读取请求,该请求 (1) 发送到排序点,(2) 广播到所有核心,然后 (3) 接收数据。
- directory protocol;
- Directory protocols do not rely on any implicit network ordering and can be mapped to an arbitrary topology;
- 目录协议依赖于点对点消息而不是广播;一致性消息的减少使此类协议能够提供更大的可扩展性。目录不是向所有核心广播,而是包含有关哪些核心具有缓存块的信息。单个核心从图2.2b中的目录接收读取请求,从而降低带宽要求。
- 目录维护系统中缓存行的当前共享者信息和一致性状态信息。通过维护共享列表,目录协议无需向整个系统广播无效请求。Addresses are interleaved across directory nodes;每个地址都分配有一个home node,该节点负责对该地址的所有一致性请求进行排序和处理。目录一致性状态在内存中维护;为了使目录适用于片上多核架构,directory caches are used.。
- 将所有一致性请求都转移到片外内存中是不切实际的。通过在片上目录缓存中维护最近访问的目录信 息,可以减少延迟。
片上网络的一致性协议要求
Cache coherence protocols require several types of messages: unicast, multicast and broadcast.
- unicast
单播(一对一)流量是从单个源到单个目标(例如,从 L2 缓存到内存控制器)
- multicast
多播(一对多)流量是 从单个源到芯片上的多个目标(例如,从目录主节点到多个共享者的缓存行失效消息)
- broadcast
广播流量 (一对多)将消息从单个源发送到芯片上的所有网络目标。
使用directory protocol,大多数请求将是unicast(或点对点)。 因此,这对网络带宽的要求较低。基于目录的协议由于点对点通信的特性,通常在可扩展设计中使用;然而,它们不能免受multicast通信的影响。例如,send out multiple invalidations from a single directory to nodes sharing a cache block.
广播协议对互连提出了更高的带宽要求,因为所有一致性请求具有一对多性质。可能需要广播协议来收集来自所有节点的确认消息,以确保请求的正确排序。数据响应消息是点对点(unicast)的并且不需要排序;
Cache coherent shared memory chip multiprocessors generally require two message sizes.
- The first message size is for coherence requests and responses without data;
- 由访问地址和一致性命令这些域段组成,通常size较小;
- A data message consists of the entire cache block (typically 64 bytes) and the memory address;
协议级网络死锁
除了消息类型和大小之外,共享内存系统还要求网络避免协议级死锁;
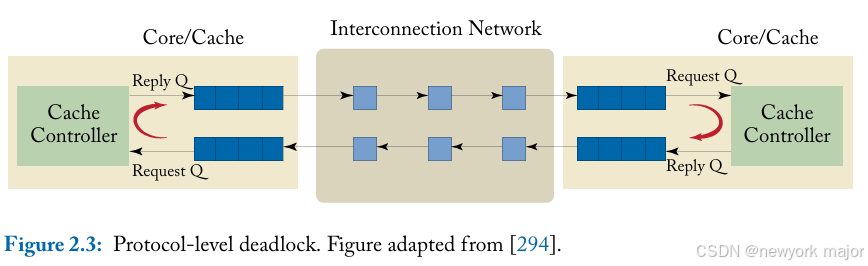
如果网络中充斥着无法被处理的请求,直到network interface开始回复时才能被处理,就会出现循环依赖的情况。
在这个例子中:
- 如果两个处理器同时发出一批请求,填满了网络资源;
- 那么两个处理器在消耗完尚未完成的请求之前,都需要等待远程响应。
- 如果响应也占用了与请求相同的网络资源,那么这些响应将无法继续前进,从而导致死锁。
Protocols can require several different message classes,每一种类型的message, 都是彼此独立的,包含一组相关的一致性操作;也就是说,一个request message不会导致产生一个其他类型的request message,但是可以触发一个其他类型的mesage; 当不同类型的消息之间有resource dependences时,就有可能产生死锁,上面的场景就是这个问题;
这里我们分成3种类型的message;
- request, like loads,stores,upgrades, writeback;
- intervention, messages sent from the directory to request modified data be transferred to a new node;
- response, like invalidation acknowledgments, negative acknowledgments (indicating a request has failed) and data messages
可以使用多个虚拟通道来防止协议级死锁。Alpha 21364 为每个消息类分配一个虚拟通道,以防止协议级死锁。 通过要求不同的消息类别使用不同的虚拟通道,网络中请求和响应之间的循环依赖关系被打破;
cache hierarchy implemention对网络性能的影响
Node design会对片上网络的带宽要求产生重大影响。在本节中,我们将研究the impact of the cache hierarchy,并研究有多少不同的entities will share the injection/ejection port to the network。这些entities可以包括多级缓存、directory coherence caches和内存控制器。 此外,这些entities在整个芯片中的分布方式会对整体网络性能产生重大影响;
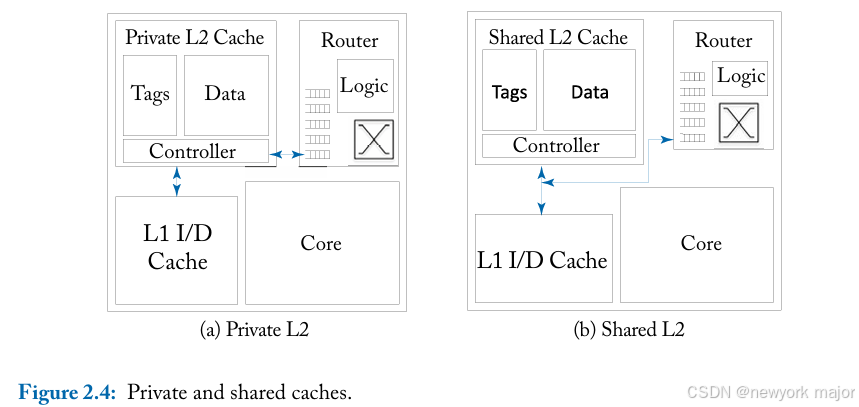
使用缓存是为了reduce the memory latency of requests。它们还充当需要发送到互连的流量的过滤器。为了便于讨论, 我们假设缓存层次结构为两级。一级 (L1) 缓存分为指令缓存和数据缓存,二级 (L2) 缓存是最后一级缓存, 是统一的。这里讨论的权衡可以推广到包含更多缓存级别的缓存层次结构。当前的芯片多处理器研究采用 私有 L2 缓存、共享 L2 缓存或混合私有/共享缓存机制;
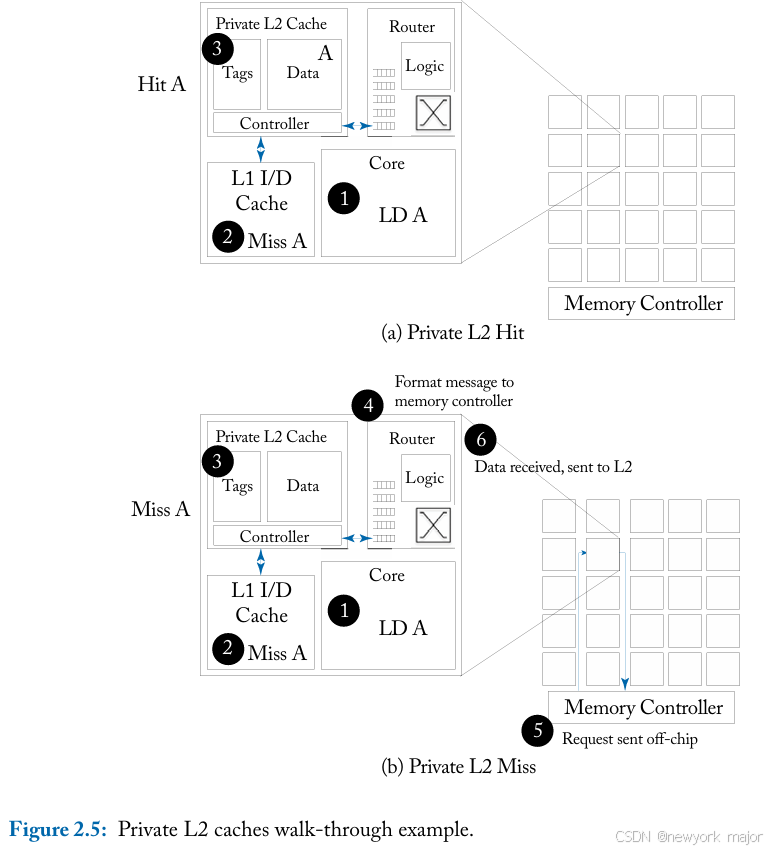
- 对于private L2 cache,L1 未命 中首先被发送到该处理器的本地私有 L2 缓存;在 L2 缓存中,请求可能会命中,然后转发到保存其目录的 远程 L2 缓存,或者访问片外内存。
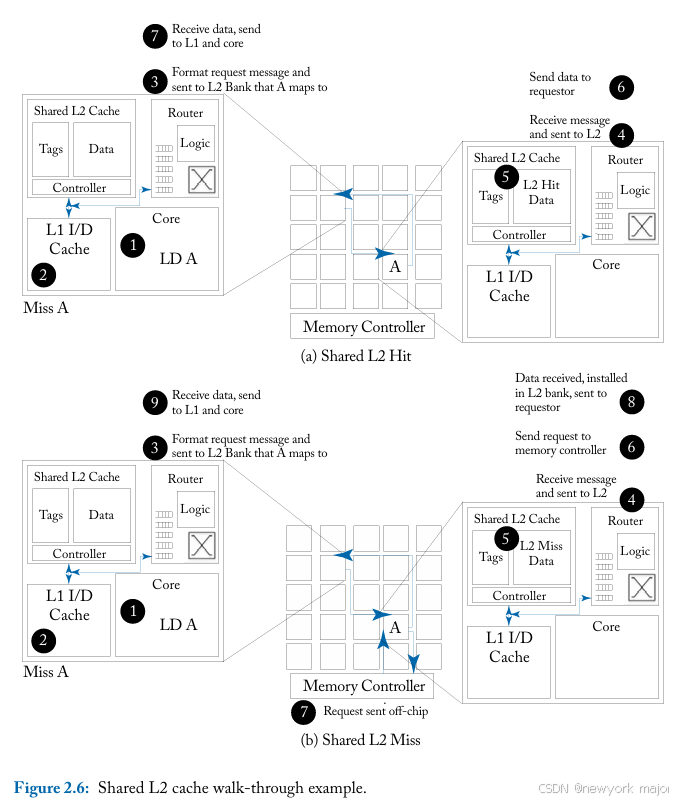
- shared L2 cache, ,L1 未命中将被发送到由未命中地址确定的L2 bank(不一定是local L2 bank),在那里它可能在l2 bank中命中,也可能未命中并被发送到片外以访问主内存。
私有缓存减少了片上 L2 缓存命中的延迟,并将经常访问的数据保存在靠近处理器的位置。私有缓存的一 个缺点是共享数据在片上的几个缓存中复制。这种复制导致片上存储的利用效率降低。
由于每个核心都有 一个小型的私有 L2 缓存,因此缓存之间的互连流量将减少,因为只有 L2 缓存未命中会进入网络;然而,芯片外的互连流量可能会增加(as data that do not fit in the private L2 cache will have to be evicted off chip)。有了私有二级缓存,片上网络将只与每个节点的二级缓存交互,the injection and ejection ports of the router are only connected to one component within the tile and do not need to be shared;
对于private L2 cache和shared L2 cache,其具体的工作原理,可以参考如下两张图;
共享缓存代表了更有效的存储使用,因为没有缓存行的复制。但是,L2 缓 存命中会导致从不同块请求数据的额外延迟。共享缓存对互连网络施加了更大的压力,因为 L1 未命中也会进入网络,但更有效 地使用存储可能会减少对内存的片外带宽的压力。使用共享缓存,更多请求将传输到远程节点以获取数据。如图2.4b 所示,当 L2共享时,片上网络必须连接到 L1 和 L2;两个级别的缓存共享路由器的注入和弹出带宽。
home node和mem controller的设计
使用directory protocol,每个地址都会静态映射到一个home node。directory information驻留在home node,home node负责对映射到此节点的所有地址的请求进行排序。目录要么从芯片外(从内存或另一个插槽)提供数据,要么向芯片上的其他节点发送干预消息以获取一致性请求的数据和/或权限。
对于共享的 L2 缓存,具有目录信息 的home node是地址映射到的cache bank(也就是通过地址来索引)。从图 2.6 中的示例来看,目录位于node A处;If remote L1 cache copies need to be invalidated (for a write request to A), the directory will send those requests through the network.
使用私有 L2 缓存配置,home node和各个RN之间无需一一对应。每个RN可以容纳目录的一部分(n个home node),可以有一个集中式目录,也可以有1到n之间的多个home node;
在两级缓存层次结构中,L2 缓存未命中必须由主内存满足。这些请求通过片上网络传输到memory controllers。Memory-intensive workloads会对内存控制器提出很高的要求,从而使内存控制器成为网络流量的hot-spots。
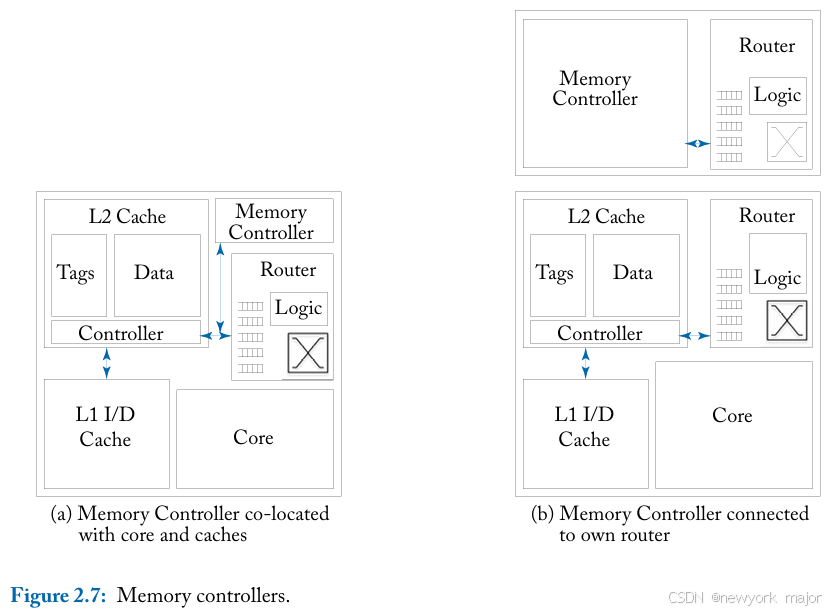
内存控制器可以与处理器和缓存块共置。通过这种安排,内存控制器将与缓存共享网络injection/ejection端口,如图2.7a 所示。此设计需要在内存控制器和本地缓存之间增加一个arbiter, 用来仲裁controller和cache的traffic。
或者,内存控制器可以作为互连网络上的单独节点放置;通过这种设计,内存控制器不必与缓存流量共享往返网络的injection/ejection带宽(如图2.7b 所示)。在这种情况下,流量更加孤立;the memory controller has access to the full amount of injection bandwidth。
在当前设计中,内存控制器通常放置在芯片的外围,以便可以近距离访问 I/O PAD。
Miss And Transaction Status Holding Registers
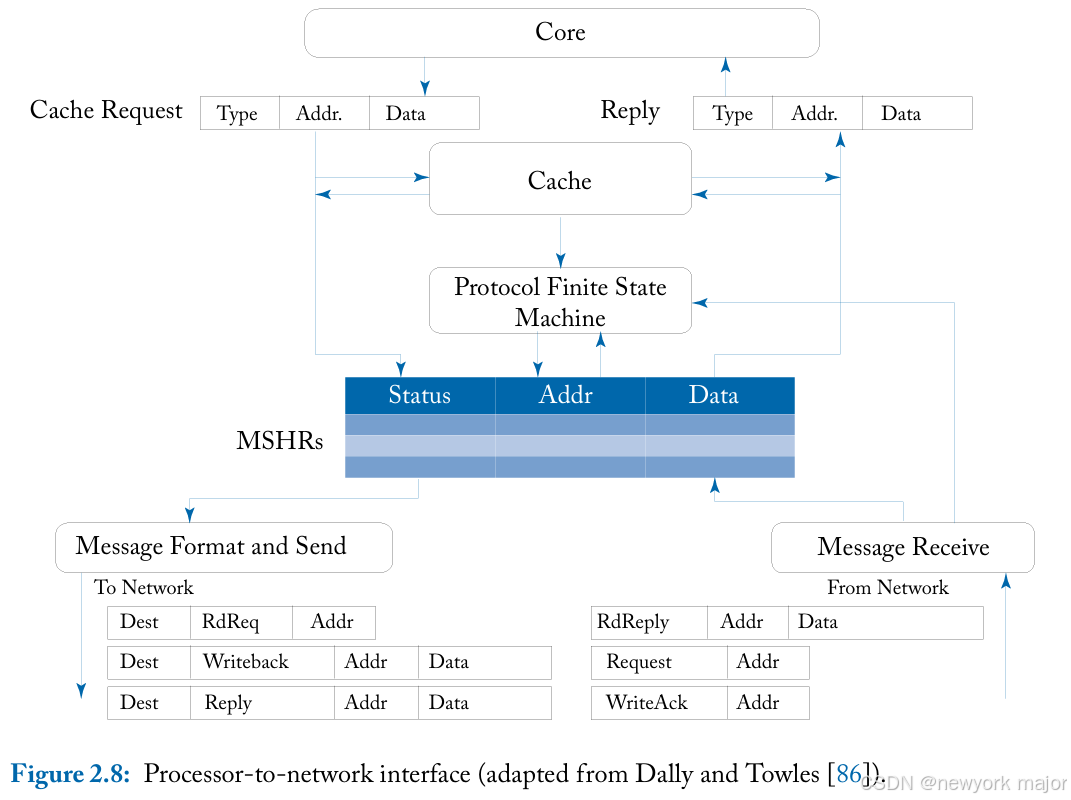
A processor-to-network interface is responsible for:
- formatting network messages to handle cache misses (due to a load or store)
- cache line permission upgrades
- and cache line evictions.
- 当发生缓存未命中时,将分配并初始化未命中状态处理寄存器 (MSHR)。
- 例如,在读取请求时,MSHR 被初始化为读取待处理状态,并且message format block将创建网络消息。
- 该消息的格式为包含目标地址,对于目录协议,这将是由内存地址、请求的缓存行地址和消息请求类型(例如,读取)确定的主节点位置。
- 在消息格式和发送块下方,我们展示了根据请求类型可能生成的几种可能的消息格式。
- 当 reply message 来自网络时,MSHR 将reply message与其中一个未完成的请求进行匹配并进行缓存未命中操作。
- message receive block还负责接收来自目录或另一个处理器块的请求消息以启动缓存到缓存的传输;the protocol finite state machine takes proper actions and formats a reply message to send back into the net work.。从网络接收的消息也可能有几种不同的格式,必须由消息接收块和协议有限状态机正确处理;
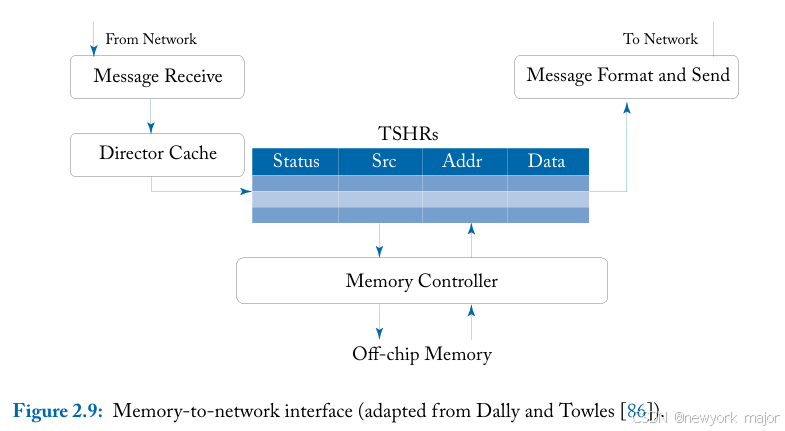
The memory-to-network interface(showninFigure2.9) is responsible for receiving mem ory request messages from processors (caches) and initiating replies;
从网络接收不同类型和大小的消息并将其发送回网络,如上图所示,如消息格式和发送块以及消息 接收块所示。在内存端,事务状态处理寄存器 (TSHR) 处理未完成的内存请求。如果内存控制器保证 按顺序处理请求,则 TSHR 可以简化为 FIFO 队列。
然而,由于内存控制器经常重新排序内存请求以提高利用率,因此需要更复杂的接口。一旦内存请求完成,消息格式和发送块负责格式化要注入网络并发送回原始请求者的消息。
MESSAGE PASSING
The message passing paradigm requires explicit communication between processes.
用户通信通过操作系统和库调用进行。必须使用匹配 的发送和接收调用编写软件,以方便将数据从一个进程传输到另一个进程。通过消息传递,可以实现任意一组协作进程之间的通信和同步。
这里我们重点关注消息传递和网络设计之间的关系。在shared memory paradigm,通过一个全局共享的地址空间可以轻松实现共享数据的识别或命名。在消息传递中,必须识别数据的拥有进程才能请求数据。消息传递中的消息类型和大小非常灵活。这会导致大量开销;解码和处理消息的工作由软件完成。灵活的消息长度也会使缓冲区管理复杂化。可能需要中断,以便软件可以临时存储消 息。在共享内存中,整个网络和接收处理器中消息的存储对软件是透明的,并且完全由硬件管理。
消息传递试图通过传递大量数据来分摊与通信相关的开销和延迟。消息传递的硬件成本和设计复 杂性通常被认为低于共享内存;实现和验证缓存一致性协议会给设计过程带来巨大的复杂性。然 而,存在许多权衡,并且消息传递确实会在系统的其他地方引入额外的复杂性。
由于通信是显式发生的,因此消息传递中的通信性能通常更容易建模和推理。程序员有明确的指导方针和对通信成本的 理解;也就是说,消息很昂贵,因此应该不频繁发送。共享内存更具挑战性,因为通信既通过加载和存储隐式发生,也通过缓存冲突 隐式发生,这将需要在软件级别不明显的额外通信;
Blocking vs.non-blocking
阻塞与非阻塞。阻塞或同步消息传递要求发送方暂停,直到接收方确认消息。尽管概念简单, 但阻塞消息传递必须仔细考虑死锁,例如,两个进程发出发送命令并暂停。两个进程都无法继续执 行接收命令,并将无限期等待。
非阻塞或异步消息传递允许发送者在发送消息后立即继续处理。这消除了与死锁相关的复杂性, 但会导致在接收者准备好处理消息之前存储消息的额外复杂性。
Message storage.
可以采用几种不同的策略来发送和存储消息。消息可以直接写入专用寄存器或消 息缓冲区,也可以通过内存映射 I/O 存储在内存中。可以通过中断或轮询内存映射位置来通知接 收处理器有关消息的信息。后续会有详细讨论;
NOC interface standard
Several widely used standards for on-chip communications in SoCs today are :
- ARM’s AMBA
- ST Microelectronics’ STBus
- Sonics’ OCP
- and OpenCores Wishbone
此处不详细讨论;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









