







 本文深入探讨InnoDB存储引擎的表类型、逻辑与物理存储结构、数据库索引原理,对比聚簇与非聚簇索引,阐述InnoDB主键与非主键索引特性。
本文深入探讨InnoDB存储引擎的表类型、逻辑与物理存储结构、数据库索引原理,对比聚簇与非聚簇索引,阐述InnoDB主键与非主键索引特性。
一. 表类型
在InnoDB存储引擎表中,每张表都有个主键,如果在创建表时没有显式地定义主键(Primary Key),则InnoDB存储引擎会按如下方式选择或创建主键:
- 首先表中是否有非空的唯一索引(Unique NOT NULL),如果有,则该列即为主键。
- 不符合上述条件,InnoDB存储引擎自动创建一个6个字节大小的自动增长指针。
- 设置默认主键的作用:设立主键后,对主键建立主键索引,所有数据有序排在主键索引的叶子节点,虽然在查询的时候没用到默认创建的主键,但还是大大提高了效率。
二. 逻辑存储结构
-
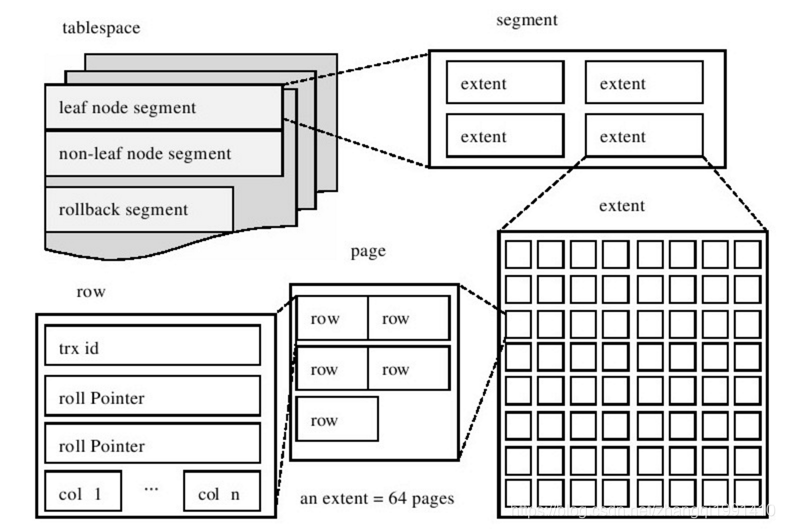
InnoDB存储引擎的逻辑存储结构和Oracle大致相同,所有数据都被逻辑地存放在一个空间中,我们称之为表空间(tablespace)。表空间又由段(segment)、区(extent)、页(page)组成。页在一些文档中有时也称为块(block),1 extent = 64 pages,InnoDB存储引擎的逻辑存储结构大致如图所示:
-
表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都是存放在表空间中。默认情况下InnoDB存储引擎有一个共享表空间ibdata1,即所有数据都放在这个表空间内。如果我们启用了参数innodb_file_per_table,则每张表内的数据可以单独放到一个表空间内。对于启用了innodb_file_per_table的参数选项,需要注意的是,每张表的表空间内存放的只是数据、索引和插入缓冲,其他类的数据,如撤销(Undo)信息、系统事务信息、二次写缓冲(double write buffer)等还是存放在原来的共享表空间内。这也就说明了另一个问题:即使在启用了参数innodb_file_per_table之后,共享表空间还是会不断地增加其大小。
-
上图中显示了表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等。InnoDB存储引擎表是索引组织的(index organized),因此数据即索引,索引即数据。那么数据段即为B+树的叶节点(上图的leaf node segment),索引段即为B+树的非叶节点(上图的non-leaf node segment)。
索引段和数据段通过指针联系起来,回滚段主要是用来存放日志信息. -
区是由64个连续的页组成的,每个页大小为16KB,即每个区的大小为1MB。对于大的数据段,InnoDB存储引擎最多每次可以申请4个区,以此来保证数据的顺序性能。
-
页同大多数数据库一样,InnoDB有页(page)的概念(也可以称为块),页是InnoDB磁盘管理的最小单位。
每页最少存两条记录,因为如果只存一条的话,就是以链表的形式存储了。 -
InnoDB存储引擎是面向行的(row-oriented),也就是说数据的存放按行进行存放。
三. 物理存储结构
从物理意义上来看,InnoDB表由共享表空间、日志文件组(更准确地说,应该是Redo文件组)、表结构定义文件组成。若将innodb_file_per_table设置为on,则每个表将独立地产生一个表空间文件,以ibd结尾,数据、索引、表的内部数据字典信息都将保存在这个单独的表空间文件中。表结构定义文件以frm结尾,这个是与存储引擎无关的,任何存储引擎的表结构定义文件都一样,为.frm文件。
四. 数据库索引
- 索引的出现其实就是为了提高数据查询的效率,就像书的目录一样,通过目录你就能很快找到你想要的内容
- 索引的常见模型:实现索引的方式有多种,常用的有三种数据结构:哈希表,有序数组,搜索树
- 哈希表是一种以键值存储数据的结构,输入值通过哈希算法得到输出值,输入值作为key,输出值作为value,哈希表的思路是将value放在数组中,key作为数组的地址。需要注意的是存在多个不同数据通过哈希算法后得到相同的值,这种情况称为哈希冲突,而解决哈希冲突的方式是拉出一个链表来存储那些相同的值.所以,我们可以知道,在做等值查询的时候,哈希表的性能是很优秀的!而从另一方面来说,由于哈希表的无序性,导致在做范围查询的时候性能偏低
- 有序数组,将数据有序存在数组中,这样在等值查询和范围查询的性能都很优秀,但如果要做插入和删除操作的时候,性能就会大幅度下降,因为你在插入或删除的时候,该地址后面的所有数据都得向前或者向后偏移
- 搜索树,两个问题:1为啥不使用二叉树而是使用多叉树? 2为啥使用B+树而不是B树或者B*树?
- 问题1:因为索引不仅存在于内存中,同时也存在于磁盘中,如果使用二叉树作为索引的数据结构,随着数据量的增多,树就会变得越来越高,这样子读取数据需要读写磁盘的次数也会越来越多,显然这是不合适的
- 问题2:B树:一棵m阶B树是一棵平衡的m路搜索树,数据同时存在于叶子节点和非叶子结点中,无法简单完 成按顺序遍历B树中的关键字,必须用中序遍历的方法。
B+树:一棵m阶B树是一棵平衡的m路搜索树,数据节点只存在于叶子节点中,且叶子节点间增加了横向的指针,这样顺序遍历所有数据将变得非常容易。
B*树:一棵m阶B树是一棵平衡的m路搜索树,非叶节点间添加了横向指针。
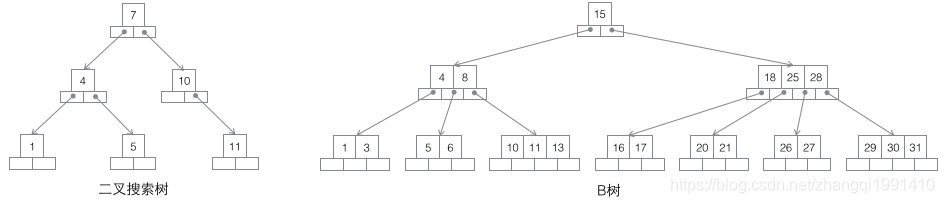
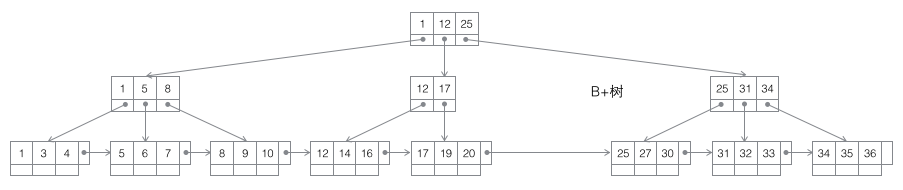
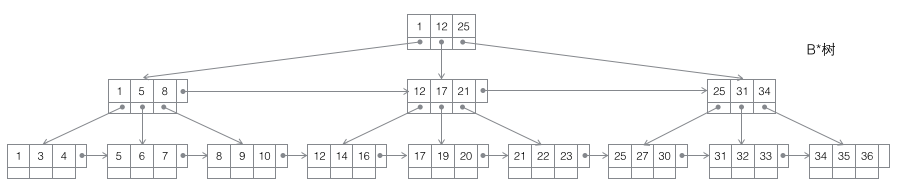
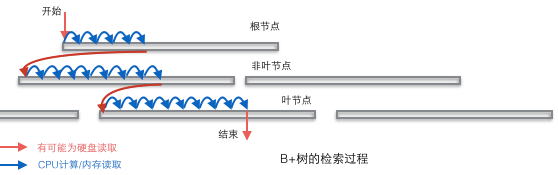
- B+树适合作为数据库的基础结构,完全是因为计算机的内存-机械硬盘两层存储结构。内存可以完成快速的随机访问(随机访问即给出任意一个地址,要求返回这个地址存储的数据)但是容量较小。而硬盘的随机访问要经过机械动作(1磁头移动 2盘片转动),访问效率比内存低几个数量级,但是硬盘容量较大。典型的数据库容量大大超过可用内存大小,这就决定了在B+树中检索一条数据很可能要借助几次磁盘IO操作来完成。如下图所示:通常向下读取一个节点的动作可能会是一次磁盘IO操作,不过非叶节点通常会在初始阶段载入内存以加快访问速度。同时为提高在节点间横向遍历速度,真实数据库中可能会将图中蓝色的CPU计算/内存读取优化成二叉搜索树(InnoDB中的page directory机制)。
五. 聚簇索引和非聚簇索引
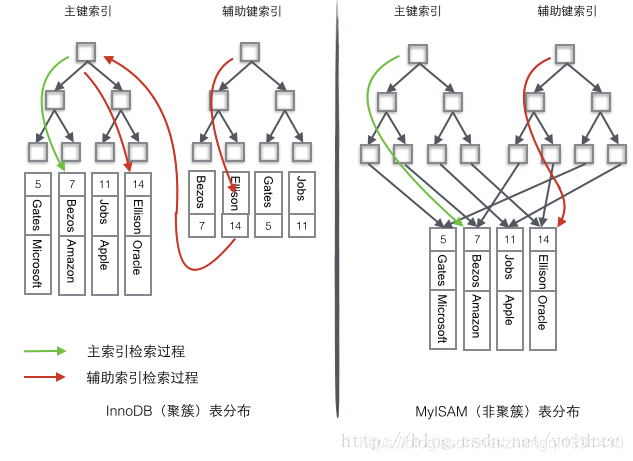
- InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
- MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
为了更形象说明这两种索引的区别,我们假想一个表如下图存储了4行数据。其中Id作为主索引,Name作为辅助索引。图示清晰的显示了聚簇索引和非聚簇索引的差异。
六. innodb引擎的主键索引和非主键索引
- 主键索引:主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引
- 非主键索引:非主键索引的叶子节点存的是主键值,在 InnoDB 里,非主键索引也被称为二级索引
- 在查询数据的时候,如果使用的是主键索引,则搜索一次主键索引树后直接返回数据;如果使用的是非主键索引,则需要先搜索二级索引树得到主键值后再搜索主键索引树返回数据,这个过程称之为回表
- 查询尽量使用主键索引,避免回表
- 主键索引越小,树的高度越低,同时二级索引的叶节点就越小,占有的内存空间也就越小
- B+树的插入可能会引起数据页的分裂,删除可能会引起数据页的合并,二者都是比较重的IO消耗,所以比较好的方式是顺序插入数据,这也是我们一般使用自增主键的原因之一
- 由于索引中存储的是主键的key值,那么重建主键时,不但会重建主键,所有的普通索引也会重新构建,所以 通常不建议重建索引,无普通索引的除外。
上述内容部分引用下方两篇博客及mysql实战45讲:
https://www.cnblogs.com/wade-luffy/p/6288656.html
https://www.cnblogs.com/shijingxiang/articles/4743324.html

















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









