




VIVADO HLS循环语句的优化
参考文献
[1]、lauren的FPGA(微信公众号)
[2]、Xilinx暑期学校
项目描述
有软件基础的同学应该知道程序的两个衡量指标是时间复杂度与空间复杂度,与我们FPGA中的最大时钟频率与资源相对应。时间复杂度的体现形式是循环的结构,这也是主要时间消耗的地方。那么,对于使用VIVADO HLS工具进行进一步的编译,程序的时间延迟也会主要体现在循环语句中。所以,我们只要使用HLS对软件的循环语句添加一定的约束,便很可能取到我们要求的指标。这篇博客主要介绍各种循环语句的优化,进而减少FPGA侧的资源与始终延迟。
循环的主要优化措施有Pipeline、Unrolling。
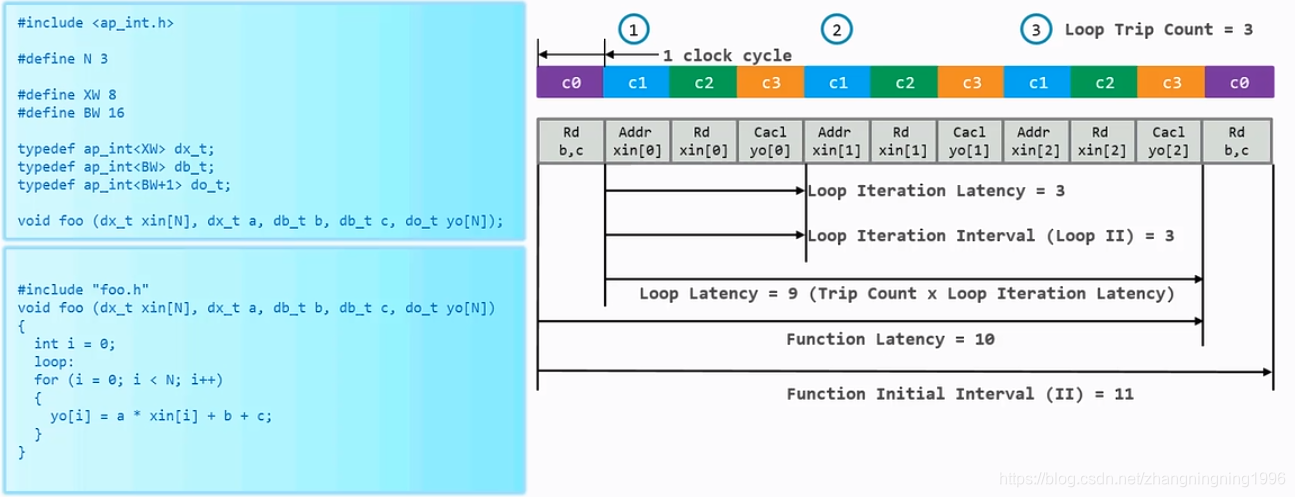
for循环的衡量指标
衡量一个for循环的指标有:
1、Loop Iteration Latency :C函数中的for循环每迭代一次需要多少时钟周期。
2、Loop Iteration Interval(Loop II):本次循环开始到下一次循环开始所需要的周期数。
3、Loop Latency :完成整个循环需要多少个时钟周期。
4、Loop Trip Count : for循环的循环迭代的次数。
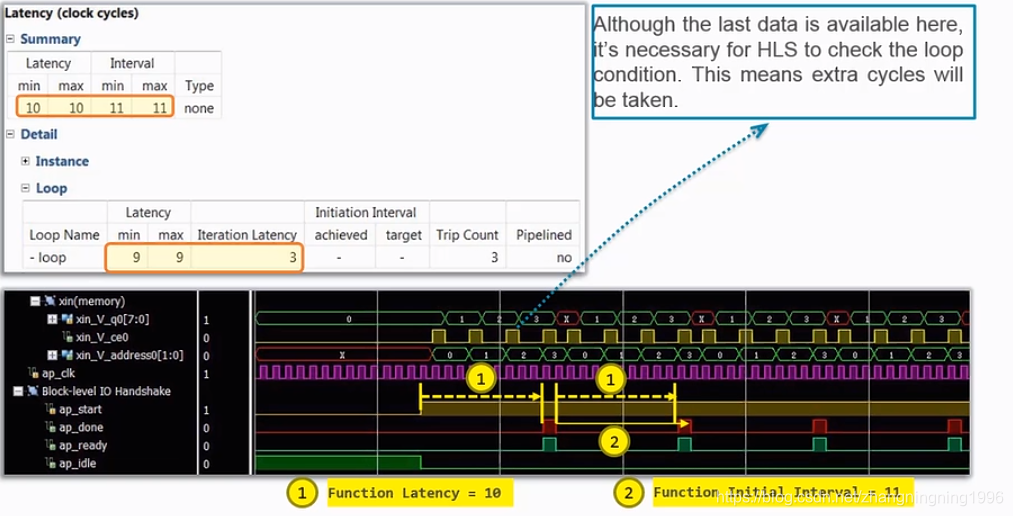
举一个例子如下:
对for循环设置Pipeline操作
还是以上面的例子添加了Pipeline的约束,如下:
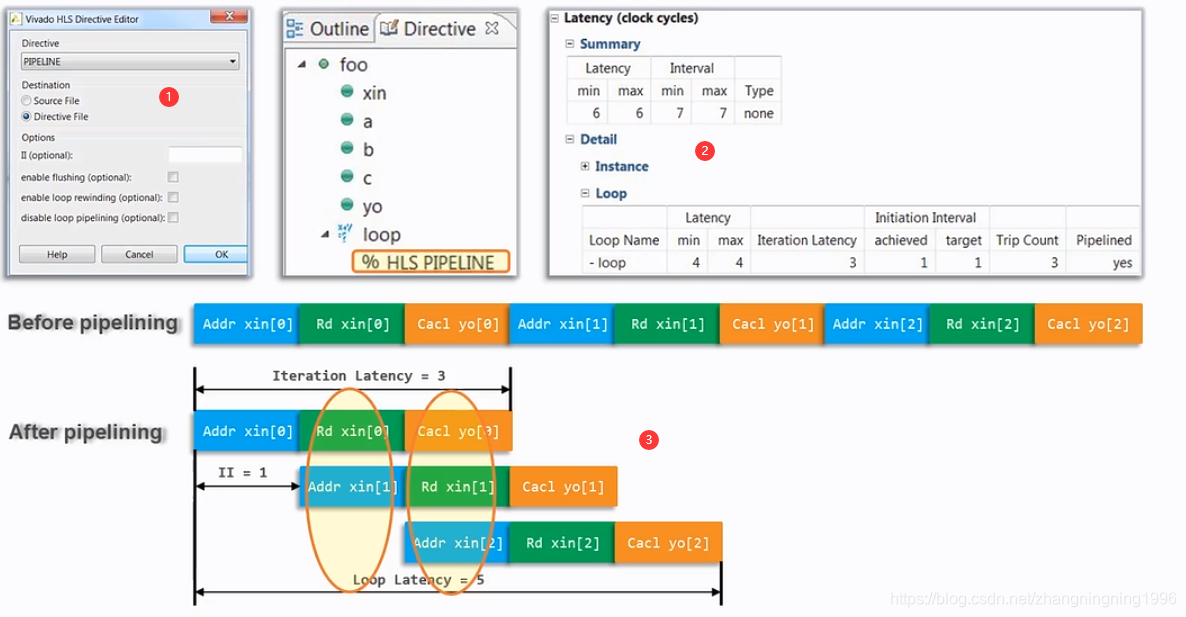
1、添加Pipeline约束的方法。
2、添加Pipeline约束进行性能优化之后的性能指标。
3、为什么添加Pipeline可以减少for循环的指标。
对for循环设置Unrolling操作
在默认的情况下for循环是被折叠的,可以理解for循环每次迭代都使用了同一套电路,所谓展开就是电路被复制了n份。
举例如下:
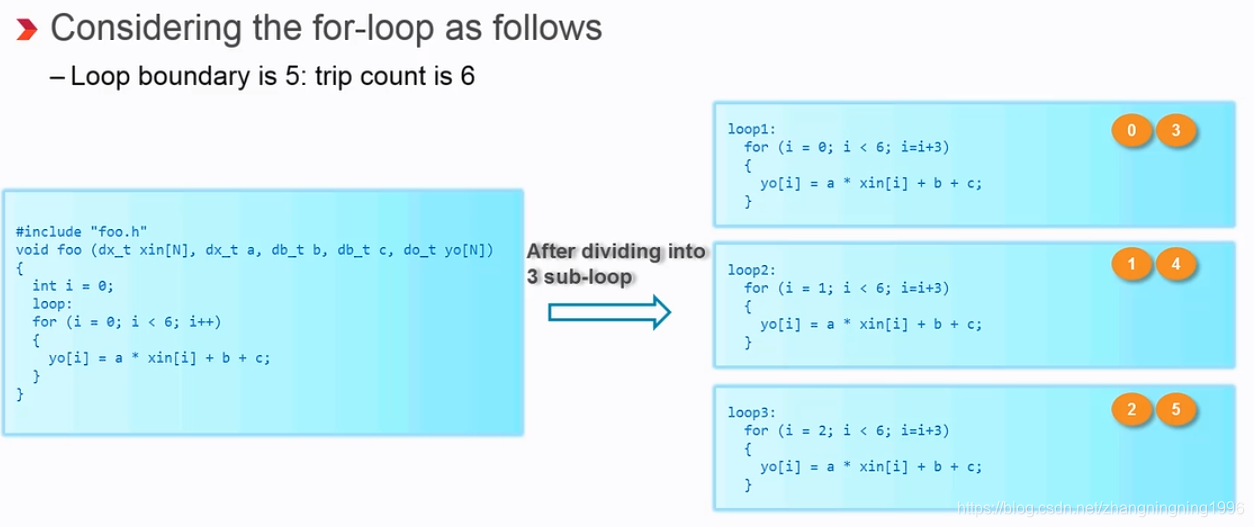
由上图可知,for循环的迭代被复制了三份,消耗的资源量如下:
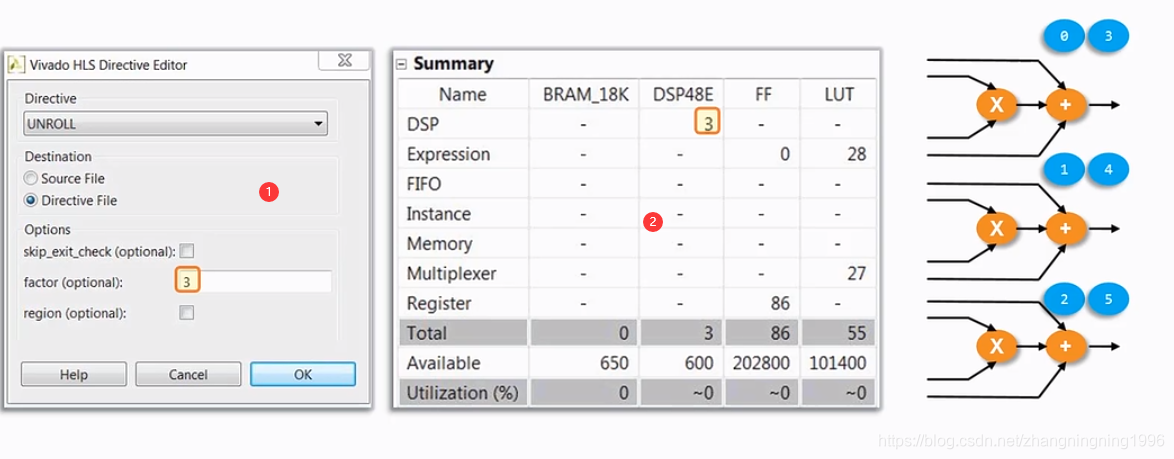
1、Unroll的设置方法。
2、消耗的资源量。
for循环的合并
对于两个完全并列的for循环约束方法——合并for循环
举一个例子如下:

for循环综合后的结果是:
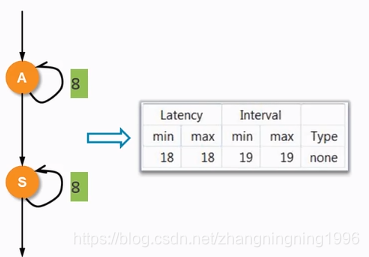

然而我们想要的综
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









