




 本文详细介绍了如何对Android的SO文件进行反混淆处理,以百度加固免费版的libbaiduprotect.so为例,包括去除垃圾代码、解密字符串和处理动态获取的libc函数。通过使用IDA Pro和Frida等工具,成功还原了混淆后的代码,使得分析过程更为清晰。
本文详细介绍了如何对Android的SO文件进行反混淆处理,以百度加固免费版的libbaiduprotect.so为例,包括去除垃圾代码、解密字符串和处理动态获取的libc函数。通过使用IDA Pro和Frida等工具,成功还原了混淆后的代码,使得分析过程更为清晰。
转:[原创]android so文件攻防实战-百度加固免费版libbaiduprotect.so反混淆-Android安全-看雪论坛-安全社区|安全招聘|bbs.pediy.com
计划是写一个android中so文件反混淆的系列文章,目前只写了这一篇。
样本libbaiduprotect_dump.so来自看雪上的帖子:百度加固免费版分析及VMP修复
原文把整个流程已经分析很清楚了,这里就不分析了,只说怎么处理libbaiduprotect_dump.so里面的混淆。
第一种混淆:加入垃圾代码
很多函数里面都插了垃圾代码,比如JNI_OnLoad:

两个相邻的数相乘肯定是偶数,while条件永远false,if条件永远true。这里我的方法就是直接把ADRP X8, #dword_C0144@PAGE(ADRP X8, 0xC0000)这样的指令改成ADRP X8, 0xA0000,因为0xC0124在bss段没有初始化,0xA0124在eh_frame段已经初始化,所以这样改了以后IDA F5的时候就会把这些垃圾代码自动优化掉。
注意:需要自己去装一个keystone,因为脚本用到了kstool.exe生成机器码。
from idautils import *
from idaapi import *
from idc import *
import subprocess
for segea in Segments():
for funcea in Functions(segea, get_segm_end(segea)):
for (startea, endea) in Chunks(funcea):
for line in Heads(startea, endea):
if idc.GetDisasm(line) in ["ADRP X8, #dword_C0144@PAGE", \
"ADRP X8, #dword_C0140@PAGE", \
"ADRP X8, #dword_C013C@PAGE", \
"ADRP X8, #dword_C0138@PAGE", \
"ADRP X8, #dword_C0134@PAGE", \
"ADRP X8, #dword_C0130@PAGE", \
"ADRP X8, #dword_C012C@PAGE", \
"ADRP X8, #dword_C0128@PAGE", \
"ADRP X8, #dword_C0124@PAGE", \
"ADRP X8, #dword_C0120@PAGE", \
"ADRP X8, #dword_C011C@PAGE", \
"ADRP X8, #dword_C0118@PAGE"]:
pi = subprocess.Popen(['D:\\keystone-0.9.2-win64\\kstool.exe', 'arm64', 'ADRP X8, 0xA0000', hex(line)], shell=True, stdout=subprocess.PIPE)
output = pi.stdout.read()
asmcode = str(output[20:33])[:-1]
asmcode = asmcode.split(" ")
asmcode = "0x" + asmcode[4] + asmcode[3] + asmcode[2] + asmcode[1]
print(asmcode)
patch_dword(line, int(asmcode, 16))
elif idc.GetDisasm(line) in ["ADRP X9, #dword_C0140@PAGE", \
"ADRP X9, #dword_C013C@PAGE", \
"ADRP X9, #dword_C0138@PAGE", \
"ADRP X9, #dword_C0134@PAGE", \
"ADRP X9, #dword_C0130@PAGE", \
"ADRP X9, #dword_C012C@PAGE", \
"ADRP X9, #dword_C0128@PAGE", \
"ADRP X9, #dword_C0124@PAGE", \
"ADRP X9, #dword_C0120@PAGE", \
"ADRP X9, #dword_C011C@PAGE", \
"ADRP X9, #dword_C0118@PAGE"]:
pi = subprocess.Popen(['D:\\keystone-0.9.2-win64\\kstool.exe', 'arm64', 'ADRP X9, 0xA0000', hex(line)], shell=True, stdout=subprocess.PIPE)
output = pi.stdout.read()
asmcode = str(output[20:33])[:-1]
asmcode = asmcode.split(" ")
asmcode = "0x" + asmcode[4] + asmcode[3] + asmcode[2] + asmcode[1]
print(asmcode)
patch_dword(line, int(asmcode, 16))
elif idc.GetDisasm(line) in ["ADRP X10, #dword_C0140@PAGE", \
"ADRP X10, #dword_C013C@PAGE", \
"ADRP X10, #dword_C0138@PAGE", \
"ADRP X10, #dword_C0134@PAGE", \
"ADRP X10, #dword_C0130@PAGE", \
"ADRP X10, #dword_C012C@PAGE", \
"ADRP X10, #dword_C0128@PAGE", \
"ADRP X10, #dword_C0124@PAGE", \
"ADRP X10, #dword_C0120@PAGE", \
"ADRP X10, #dword_C011C@PAGE", \
"ADRP X10, #dword_C0118@PAGE"]:
pi = subprocess.Popen(['D:\\keystone-0.9.2-win64\\kstool.exe', 'arm64', 'ADRP X10, 0xA0000', hex(line)], shell=True, stdout=subprocess.PIPE)
output = pi.stdout.read()
asmcode = str(output[20:33])[:-1]
asmcode = asmcode.split(" ")
asmcode = "0x" + asmcode[4] + asmcode[3] + asmcode[2] + asmcode[1]
print(asmcode)
patch_dword(line, int(asmcode, 16))处理以后:
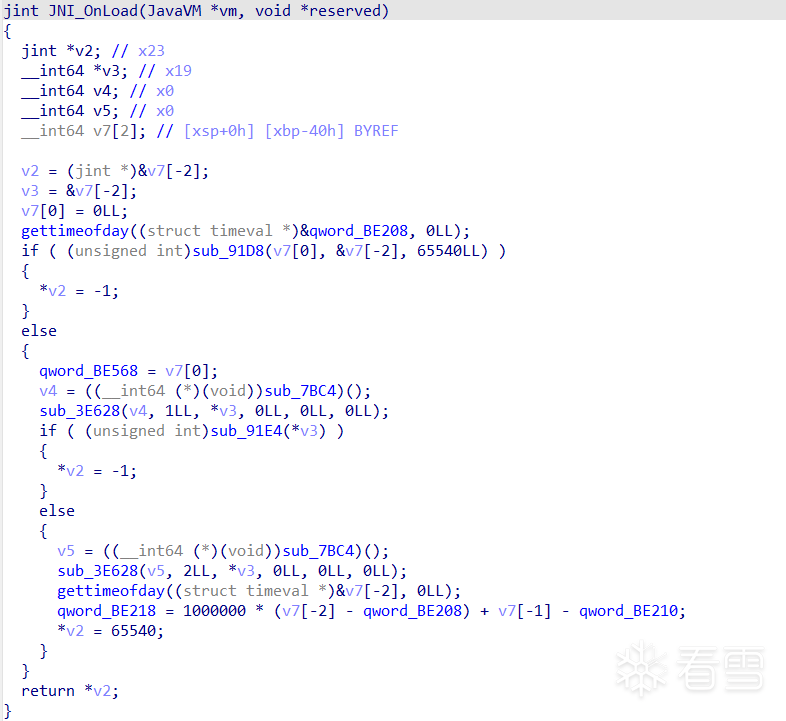
第二种混淆:字符串加密
加密后的字符串基本都长这个样子:
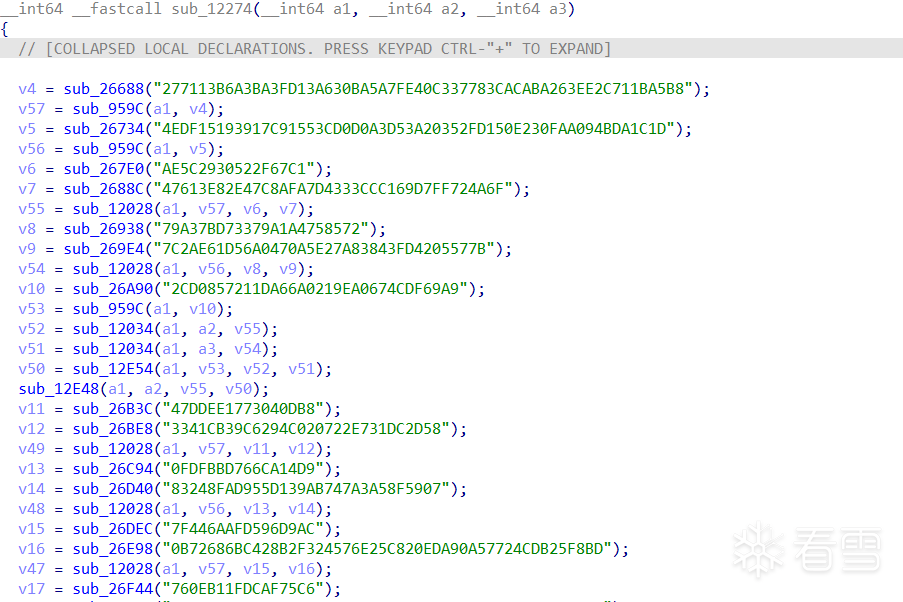
每个字符串的解密函数虽然都不一样,但是逻辑都差不多。处理字符串加密可以用的工具有很多,我习惯用frida。
第一步是通过交叉引用拿到加密后的字符串和它对应的解密函数的表:
from idautils import *
from idaapi import *
from idc import *
import string
rodata_start = 0x959B0
rodata_end = 0x9AF68
def get_string(addr):
out = ""
while True:
if get_byte(addr) != 0:
out += chr(get_byte(addr))
else:
break
addr += 1
return out
addr = rodata_start
index = 0
while addr < rodata_end:
str = get_string(addr)
str_len = len(str) + 1
if all(c in string.hexdigits for c in str) and str_len > 8:
xrefaddrs = XrefsTo(addr, flags=0)
for xrefaddr in xrefaddrs:
call_addr = xrefaddr.frm
while print_insn_mnem(call_addr) != "BL":
call_addr = next_head(call_addr)
decode_func_addr = print_operand(call_addr, 0)
print("\"" + decode_func_addr + '***' + str + "\"" + ",")
addr += str_len结果:
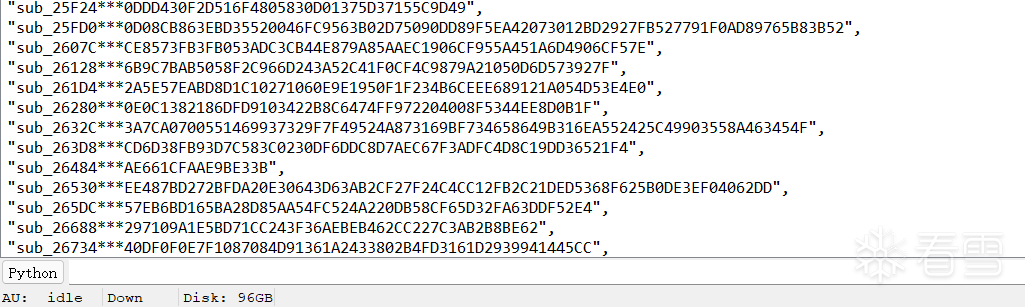
第二步是把这个表丢给frida,让frida去调一遍,拿到解密后的字符串。为了代码简洁这个表就没有列完,只有两项:
import frida
import sys
device = frida.get_usb_device(1)
session = device.attach("Test")
scr = """
var str_name_so = "libbaiduprotect.so";
var n_addr_so = Module.findBaseAddress(str_name_so);
// console.log("libbaiduprotect.so base address:");
// console.log(n_addr_so.toString(16));
var decode_func2str_list = [
"sub_25FD0***09598DD611D1543C",
"sub_2607C***8CA86FFB66BD1DAFC58A62B543A840AACA833ED67ABD44A28B8864F477F361B7D68D6BFD2B9058A2D2852AF671B255ECF79077F37EBB098FCE8573FB3FB053ADC3CB56EE62B55CA49FAD5FB346",
......
]
for (let i in decode_func2str_list)
{
var str = decode_func2str_list[i].substring(12)
var funcaddr = parseInt(decode_func2str_list[i].substring(4, 9), 16)
var n_funcaddr = funcaddr + parseInt(n_addr_so, 16);
//console.log("n_funcaddr address:");
//console.log(n_funcaddr.toString(16));
var call_func = new NativeFunction(ptr(n_funcaddr), 'pointer', ['pointer']);
var str_arg = Memory.allocUtf8String(str);
var p_str_ret = call_func(str_arg);
var str_ret = Memory.readCString(p_str_ret);
console.log("\\"" + str_ret + "\\"" + ",");
}
"""
def on_message(message, data):
print(message)
#print(message['payload'].encode("utf-8"))
script = session.create_script(scr)
script.on("message", on_message)
script.load()结果:
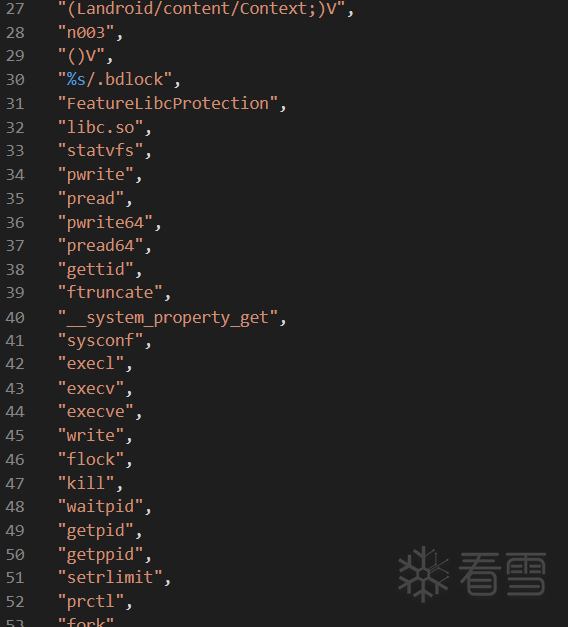
第三步就是把加密后的字符串直接patch成加密前的字符串,因为如果用set_cmt(也就是IDA7.4以前的MakeComm)把加密前的字符串当成注释加上的话F5的窗口是没有的,这样直接patch看起来更清晰直观。加密后的字符串总是比加密前的字符串长,多出来的就patch成0。同样为了代码简洁加密前的字符串没有列完,只有两项:
from idautils import *
from idaapi import *
from idc import *
import string
rodata_start = 0x959B0
rodata_end = 0x9AF68
def get_string(addr):
out = ""
while True:
if get_byte(addr) != 0:
out += chr(get_byte(addr))
else:
break
addr += 1
return out
addr = rodata_start
index = 0
decrypted_str = [
"n001",
"(Ljava/lang/String;Ljava/lang/String;Ljava/lang/String;Ljava/lang/String;IZ)V",
......
]
while addr < rodata_end:
str = get_string(addr)
str_len = len(str) + 1
if all(c in string.hexdigits for c in str) and str_len > 8:
i = 0
tmp_addr = addr
decrypted_strlen = len(decrypted_str[index])
while i < str_len:
if i >= decrypted_strlen:
patch_byte(tmp_addr, 0x00)
else:
patch_byte(tmp_addr, ord(decrypted_str[index][i]))
i = i + 1
tmp_addr = tmp_addr + 1
index = index + 1
addr += str_len还是前面的sub_12274,来看处理完以后的效果:
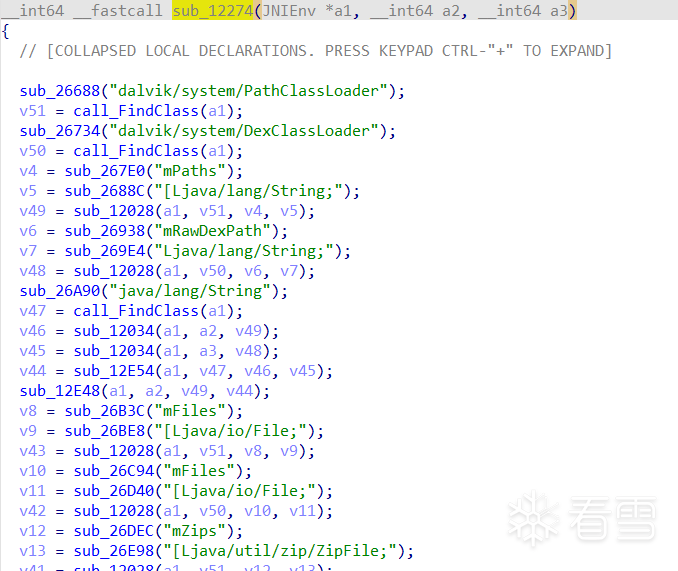
第三种混淆:libc函数动态获取
sub_B3B4动态获取libc中的函数并保存,我们这里做一下符号重命名即可。
首先把F5中的sub_B3B4保存下来,然后写个脚本把qword_BE238命名为_exit_libc,qword_BE240命名为exit_libc,qword_BE248命名为pthread_create_libc,依次类推即可。
from idautils import *
from idaapi import *
from idc import *
flag = 0
for line in open("D:\\libc.cpp"):
if flag == 0:
strs = line.split("\"")
funcname = strs[-2]
funcname += "_libc"
flag = 1
continue
if flag == 1:
addrname = line[8:13]
addrname = int(addrname, 16)
flag = 0
set_name(addrname, funcname, SN_CHECK)结果:
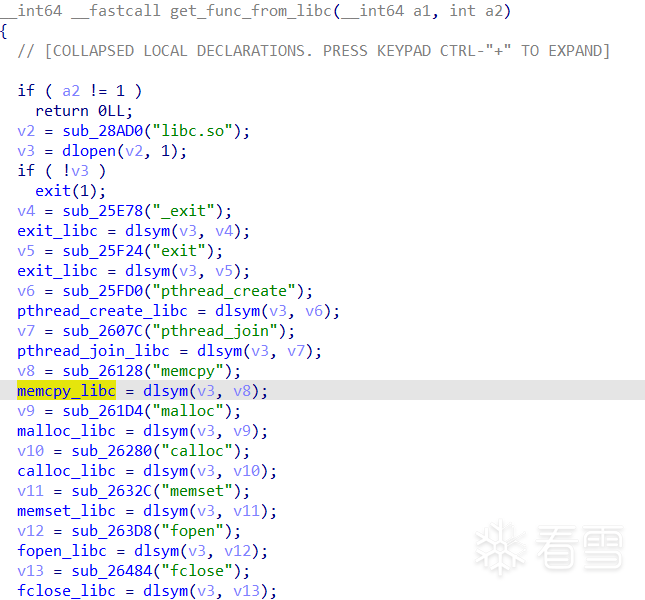
用这些函数的地方也看的比较清楚。
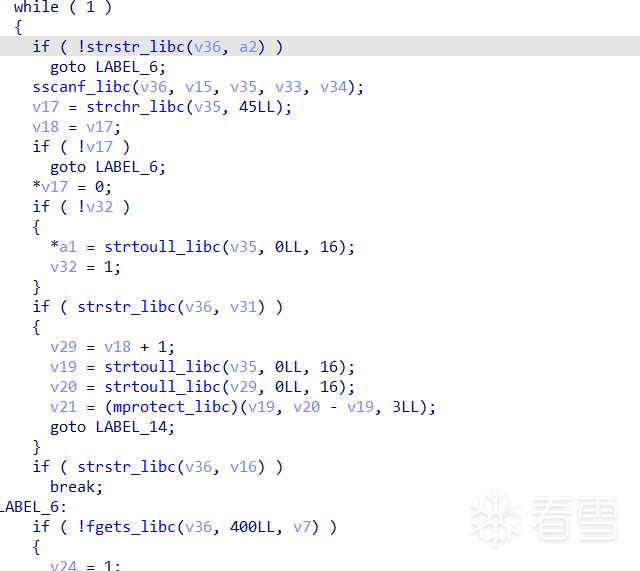
总结
百度加固免费版libbaiduprotect.so里面基本上就是这些花样,还是比较好搞定的。

















 4764
4764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









