







 本文详细介绍了MySQL数据库的设计和使用,从项目需求的原型模型出发,讲解了数据库设计的各个步骤,包括需求分析、E-R模型、逻辑设计和物理设计。接着,深入探讨了MySQL的初体验,包括其主要存储引擎、系统数据库、用户数据库的创建和管理。进一步,文章通过Navicat工具演示了数据库和表的创建,并回顾了SQL基础知识如数据类型、主键约束、存储引擎等。最后,文章讨论了SQL高级话题,如ALTER TABLE、主外键约束、数据操纵语言(DML)以及事务处理,同时还涵盖了索引、视图、备份恢复和用户权限设置等企业级开发技术。
本文详细介绍了MySQL数据库的设计和使用,从项目需求的原型模型出发,讲解了数据库设计的各个步骤,包括需求分析、E-R模型、逻辑设计和物理设计。接着,深入探讨了MySQL的初体验,包括其主要存储引擎、系统数据库、用户数据库的创建和管理。进一步,文章通过Navicat工具演示了数据库和表的创建,并回顾了SQL基础知识如数据类型、主键约束、存储引擎等。最后,文章讨论了SQL高级话题,如ALTER TABLE、主外键约束、数据操纵语言(DML)以及事务处理,同时还涵盖了索引、视图、备份恢复和用户权限设置等企业级开发技术。
数据库设计
项目需求——原型模型
快速运行模型(抛弃型)
特点:
-
用来获取用户需求,或是用来试探设计是否有效
-
需求一旦定下原型就抛弃
-
使用快速设计工具,要求快速构建,易于修改,节约成本。如:VS等
-
还可在原型中进化
-
-
快速原型是暂时使用,因此不要求完整,往往针对某个局部简历专门原型。如:界面原型、工作流原型、查询原型等
-
快速原型不能贯穿整个开发生命周期,他需要和其他过程模型相结合才能产生作用。如:瀑布模型中应用快速原型
运行进化模型(渐进型)
特点:
-
针对开发全流程,从最基本核心功能开始,逐渐增加新功能和新需求,反复扩充,最终发展到用户满意系统
-
通过不断发布新的软件版本而使软件逐步完善,适合用户急需的软件产品开发
注意:
-
没有明确“里程碑”,增加管理难度,对进度不能明确管理
-
快速变更,可能会影响软件内部结构稳定性,势必影响今后维护
原型开发步骤:
-
快速分析
-
构建原型
-
运行原型
-
评价原型
-
修改
数据库设计步骤:
-
需求分析
-
分析用户的需求,包括数据、功能和性能需求
-
-
概念结构设计
-
主要采用E-R模型进行设计,包括绘制E-R图
-
-
逻辑结构设计
-
通过E-R图转换成表,实现从E-R模型到关系模型的转换,进行关系规范化
-
-
数据库物理设计
-
主要为所设计的数据库选择合适的存储结构和存储路径
-
-
数据库的实施
-
包括编程、测试和试运行
-
-
数据库运行和维护
-
系统的运行和数据库的日常维护
-
MySql初体验
准备:
-
数据库管理系统的作用是什么?
-
简述MySql数据库的特点
-
请写出创建和删除数据库的SQL语句
-
MySQL支持的主要存储引擎有哪些
目标:
-
安装配置MySQL数据库
-
使用Navicat工具新建数据库
-
使用SQL语句创建数据库hospital
-
使用SQL语句创建hospital数据库中的表
-
使用MySQL的系统帮助功能
MySQL简介
流行的开源的关系型数据库
发展:瑞典MySQL AB公司==>2008被SUN收购==>2009 SUN被Oracle收购
优势:
-
运行速度快
-
使用成本低
-
易用
-
可移植性强
-
适用用户广
版本:
-
社区版:免费、开源;适用普通用户
-
企业版:收费,不可自由下载;功能和服务完善;适用对功能和安全要求较高的企业用户;
获取:MySQL :: Download MySQL Community Server
下载方式:
-
安装包程序(推荐);
-
解压免安装
安装方式:
-
配置High Availability:默认选项Standalone MySQL Server/classic MySQL Replication
-
配置Type and Networking:默认启用TCP/IP网络;端口3306
-
配置Account and Roles:用户名、密码,添加其他管理员;默认root管理员
-
配置Windows Service:配置MySQL Server
-
默认字符集
-
将bin目录写入环境变量:此电脑==>右键“属性”==>高级系统设置==>环境变量==>(系统)path==>新建==>粘贴mysql安装路径中bin所在文件夹位置
主要文件夹
1、bin目录
用于放置一些可执行文件,如mysql.exe、mysqld.exe、mysqlshow.exe等。
2、data目录
用于放置一些日志文件以及数据库。
3、include目录
用于放置一些头文件,如:mysql.h、mysql_ername.h等。
4、lib目录
用于放置一系列库文件。
5、share目录
用于存放字符集、语言等信息。
6、my.ini这个很重要
是MySQL数据库中使用的配置文件。
配置信息:
port=3306
default-character-set=utf8;
character-set-server=utf8
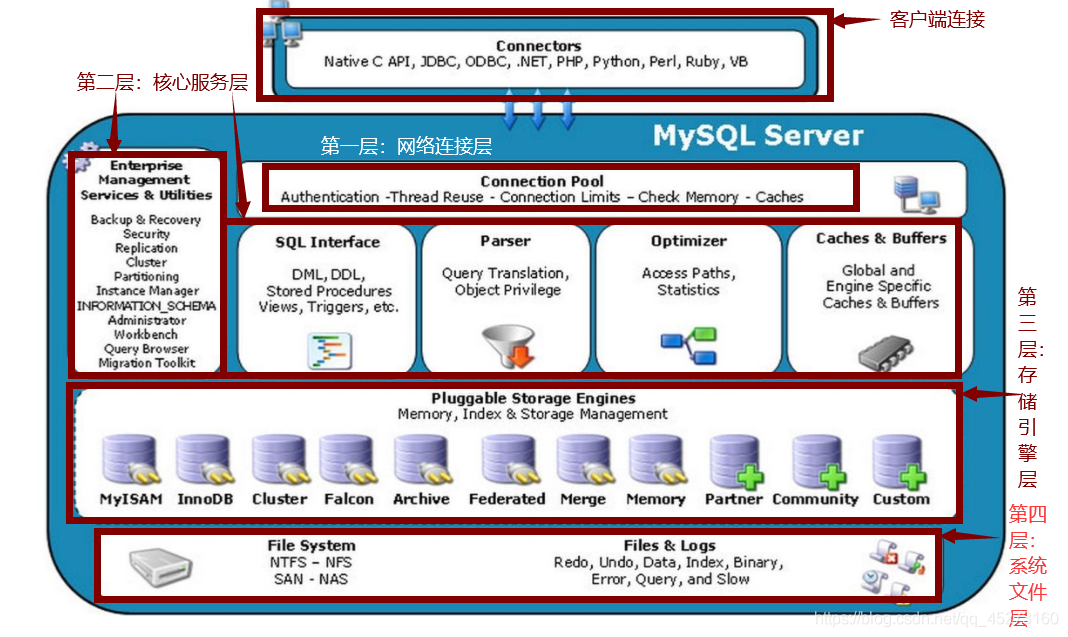
系统数据库和用户数据库
系统数据库:
-
Information_schema:主要存储数据库对象如用户表信息、字段信息、权限信息、字符集信息和分区信息等
-
Performance_schema:主要数据库服务器性能参数
-
mysql:主要存储系统用户信息
用户数据库:
-
用户自建维护的数据库
启动数据库步骤:
检查是否启动服务!!!
启动方式:
属性窗口
DOS命令(管理员权限操作MySQL5.5):
> net start mysql MySQL 服务正在启动 . MySQL 服务已经启动成功。 > net stop mysql MySQL 服务正在停止. MySQL 服务已成功停止。
修改配置文件后需重启MySQL服务才能生效
登录mysql:
命令行方式:
语法: mysql -u用户名 -p
//用户名、密码同时输入---问题:密码是明码 > mysql -uroot -proot //用户名明码,密码使用 * 替代 > mysql -uroot -p Enter password: ****
通过 MySQL 5.5 Command Line Client 登录
mysql指令示例:
mysql版本和用户名
查询数据库列表
Navicat使用
创建连接
创建数据库
-
操作向导
-
SQL语句
知识回顾
结构化查询语句
| 名称 | 解释 | 示例 |
|---|---|---|
| DML(数据操作语言) | 操作数据库中所包含的数据 | INSERT、UPDATE、DELETE |
| DDL(数据定义语言) | 创建、删除数据库对象等操作 | CREATE、DROP、ALTER |
| DQL(数据查询语言) | 对数据库中的数据进行查询 | SELECT |
| DCL(数据控制语言) | 控制数据库组件存取许可、权限等 | GRANT、COMMIT、ROLLBACK |
数据类型
1.数值类型
| 类型 | 说明 | 取值范围 | 存储需求 |
|---|---|---|---|
| TINYINT | 非常小数据 | 有符号:-2^7~2^7-1 无符号:0~2^8-1 | 1字节 |
| SMALLINT | 较小数据 | 有符号:-2^15~2^15-1 无符号:0~2^16-1 | 2字节 |
| MEDIUMINT | 中等大小数据 | 有符号:-2^23~2^23-1 无符号:0~2^24-1 | 3字节 |
| INT | 标准整数 | 有符号:-2^31~2^31-1 无符号:0~2^32-1 | 4字节 |
| BIGINT | 较大数据 | 有符号:-2^63~2^63-1 无符号:0~2^64-1 | 8字节 |
| FLOAT | 单精度浮点数 | ±1.1754351e-38 | 4字节 |
| DOUBLE | 双精度浮点数 | ±2.2250738585072014e-308 | 8字节 |
| DECIMAL | 字符串形式浮点数 | Decimal(M,D) | M+2字节 |
UNSIGNED属性:标识为无符号数,非负数
ZEROFILL属性:宽度(位数)不足以0填充;设置此属性后,自动添加UNSIGNED属性
2. 字符串
| 类型 | 说明 | 长度 |
|---|---|---|
| CHAR[(M)] | 定长字符串 | M字节 |
| VARCHAR[(M)] | 变长字符串 | 可变长度 |
| TINYTEXT | 微型文本 | 0~2^8-1 |
| TEXT | 文本串 | 0~2^16-1 |
3. 日期类型
| 日期类型 | 格式 | 取值范围 |
|---|---|---|
| DATE | YYYY-MM-DD,日期格式 | 1000-01-01~9999-12-31 |
| DATETIME | YY-MM-DD hh:mm:ss | 1000-01-01 00:00:00~9999-12-31 23:59:59 |
| TIME | hh:mm:ss | -835:59:59~838:59:59 |
| TIMESTAMP | YYYYMMDDHHMMSS | 1970年某时刻~2038年某时刻,精度1秒,时间戳 |
| YEAR | YYYY格式年份 | 1901~2155 |
创建表
语法:
CREATE TABLE [IF NOT EXISTS] 表名( 字段1 数据类型 [字段属性|约束][索引][字段备注], 字段2 数据类型 [字段属性|约束][索引][字段备注], #…… 字段n 数据类型 [字段属性|约束][索引][字段备注] )[表类型][表字符集][表备注];
示例:
#创建学生表 CREATE TABLE student( `studentNo` INT(4) PRIMARY KEY, `name` VARCHAR(20), #…… ); /* 多个字段用逗号隔开 保留字用撇号(``)括起来 单行注释:#...... 多行注释:/*...*/ */
字段的约束和属性
| 名称 | 关键字 | 说明 |
|---|---|---|
| 主键约束 | PRIMARY KEY(PK) | 设置字段为主键 唯一标识(默认非空、唯一) |
| 外键约束 | FOREIGN KEY(PK) | 两表建立连接关系 指定应用主表哪一字段 |
| 自增约束 | AUTO_INCREMENT | 字段自增、默认+1 通常作为主键使用 |
| 非空约束 | NOT NULL | 字段必填 |
| 默认约束 | DEFAULT | 字段赋予初值 |
| 唯一约束 | UNIQUE KEY(UK) | 字段内容唯一 可空,但只能有一个空值 |
主键约束
语法:
#单主键 CREATE TABLE [IF NOT EXISTS] 表名( 字段1 数据类型 PRIMARY KEY, #…… ); CREATE TABLE [IF NOT EXISTS] 表名( 字段1 数据类型, #…… [CONSTRAINT<约束名>] PRIMARY KEY[列名] ); #联合主键 CREATE TABLE [IF NOT EXISTS] 表名( #…… PRIMARY KEY[列名1,列名2,……] );
示例:
#单主键 CREATE TABLE student( `studentNo` INT(4) PRIMARY KEY, #…… ); CREATE TABLE student( `studentNo` INT(4), #…… PRIMARY KEY(studentNo) ); #联合主键 CREATE TABLE IF NOT EXISTS prescription( `patientID` INT(4), `depID` INT(4), `checkItemID` INT(4), #…… PRIMARY KEY(patientID,checkItemID,depID) ); #联合主键技巧:将更易区分的字段靠前以提升查询效率
注释与字符集编码
注释:
-
COMMENT 关键字
-
表结构中可见,不同于代码注释
CREATE TABLE student( `studentNo` INT(4) PRIMARY KEY COMMENT '学生编号', #…… )COMMENT='测试表';
设置字符集编码
-
默认使用MySQL自助设定字符集
-
为存储独特数据,可创表时指定字符集
CREATE TABLE [IF NOT EXISTS] 表名( #…… )CHARSET='字符集名';
创表示例:
| 病人表 | patient | ||||
|---|---|---|---|---|---|
| 序号 | 字段名 | 字段说明 | 数据类型 | 长度 | 约束 |
| 1 | patientID | 病人编号 | int | 4 | 主键,自增 |
| 2 | password | 密码 | varchar | 20 | 非空 |
| 3 | birthDate | 出生日期 | date | ||
| 4 | gender | 性别 | varchar | 4 | 非空,默认‘男’ |
| 5 | patientName | 病人姓名 | varchar | 50 | 非空 |
| 6 | phoneNum | 联系电话 | varchar | 50 | |
| 7 | 邮箱 | varchar | 70 | ||
| 8 | identityNum | 身份证号 | varchar | 20 | 唯一 |
| 9 | address | 地址 | varchar | 255 | 默认‘地址不详’ |
CREATE TABLE IF NOT EXISTS patient(
`patientID` INT(4) NOT NULL PRIMARY key auto_Increment COMMIT '病人编号' ,
`password` VARCHAR(20) NOT NULL COMMIT '密码',
`birthDate` DATE COMMIT '出生日期'
`gender` VARCHAR(4) DEFAULT '男' NOT NULL COMMIT '性别',
`patientName` VARCHAR(50) NOT NULL COMMIT '病人姓名',
`phoneNum` VARCHAR(50) COMMIT '联系电话',
`email` VARCHAR(70) COMMIT '邮箱',
`identityNum` VARCHAR(20) UNIQUE KEY COMMIT '身份证号',
`address` VARCHAR(255) DEFAULT '地址不详' COMMIT '地址'
)COMMIT='病人表';
表格创建
| 科室表 | department | ||||
|---|---|---|---|---|---|
| 序号 | 字段名 | 字段说明 | 数据类型 | 长度 | 约束 |
| 1 | depID | 科室编号 | int | 4 | 主键、自增 |
| 2 | depName | 科室名称 | varchar | 50 | 非空 |
| 检查项目表 | checkitem | ||||
|---|---|---|---|---|---|
| 序号 | 字段名 | 字段说明 | 数据类型 | 长度 | 约束 |
| 1 | checkItemID | 检查项目编号 | int | 4 | 主键、自增 |
| 2 | checkItemName | 检查项目名称 | varchar | 50 | 非空 |
| 3 | checkItemCost | 检查项目价格 | float | 非空 |
| 检查项目关系表 | department_checkItem | ||||
|---|---|---|---|---|---|
| 序号 | 字段名 | 字段说明 | 数据类型 | 长度 | 约束 |
| 1 | id | 关系编号 | int | 4 | 唯一、自增 |
| 2 | depID | 科室编号 | int | 4 | 非空 |
| 3 | checkItemID | 检查项目编号 | int | 4 | 非空 |
| 处方表 | prescription | ||||
|---|---|---|---|---|---|
| 序号 | 字段名 | 字段说明 | 数据类型 | 长度 | 约束 |
| 1 | examID | 检查ID | int | 4 | 主键、自增 |
| 2 | patientID | 病人编号 | int | 4 | 非空 |
| 3 | depID | 开处方的科室编号 | int | 4 | 非空 |
| 4 | checkItemID | 检查项目编号 | int | 4 | 非空 |
| 5 | checkResult | 检查结果 | varchar | 500 | |
| 6 | examDate | 检查日期 | datetime | 非空 |
获取当前日期:日期函数NOW()
mysql存储引擎
-
存储数据核心组件,指定表的存储类型和存储形式
-
存储引擎的类型(九种):MyISAM、InnoDB、Memory、CSV等
查看引擎:SHOW ENGINES;
常见引擎介绍:
InnoDB:支持具有提交、回滚和崩溃恢复能力的事务控制
MyISAM:不支持事务,不支持外键约束,访问速度较快
| 功能 | InnoDB | MyISAM |
|---|---|---|
| 事务处理 | 支持 | 不支持 |
| 外键约束 | 支持 | 不支持 |
| 表空间大小 | 较大 | 较小 |
| 数据行锁定 | 支持 | 不支持 |
| 多删除、更新操作; 安全性高,事务处理及并发处理 | 不需要事务,空间小; 以查询访问为主 | |
| 存储文件 | *.frm:表结构定义文件 ibdate1文件(仅此文件) | * .frm:表结构定义文件 * .MYD:数据文件 * .MYI:索引文件 |
查看当前默认存储引擎
SHOW VARIABLES LIKE 'default_storage_engine%'
修改存储引擎:
修改my.ini配置文件,重启后生效
default_storage_engine=MyISAM
表的存储引擎
使用默认
创建表时添加
CREATE TABLE 表名( #…… )ENGINE=存储引擎;
示例:
CREATE TABLE temp(
id int(4)
)ENGINE=MyISAM;
SQL高级
准备:
-
什么是主外键约束?
-
DML和DQL的功能是什么 ?
-
简述LIMIT子句可实现什么功能?
-
使用子查询是注意事项有哪些?
目标:
-
掌握使用SQL语句修改、删除表的方法
-
掌握使用SQL语句实现对表添加/删除约束的方法
-
掌握使用SQL语句对表进行增删改操作的方法
-
掌握简单子查询的用法
ALTER TABLE……(修改表……)
修改表名
ALTER TABLE <就表名> RENAME[TO]<新表名>; #示例: ALTER TABLE `temp` RENAME TO `newtemp`;
添加字段
ALTER TABLE 表名 ADD 字段名 数据类型 [属性]; #示例: ALTER TABLE `newtemp` ADD `uname` VARCHAR(20);
修改字段
ALTER TABLE 表名 CHANGE 原字段名 新字段名 数据类型 [属性]; #示例: ALTER TABLE `newtemp` CHANGE `uname` `username` VARCHAR(30);
删除表中字段
ALTER TABLE 表名 DROP 字段名; #示例: ALTER TABLE `newtemp` DROP `username`;
实验示例:
| 日志表 | log | ||||
|---|---|---|---|---|---|
| 序号 | 字段名 | 字段说明 | 数据类型 | 长度 | 约束 |
| 1 | id | 日志编号 | int | 4 | 非空 |
| 2 | time | 操作时间 | date | 非空 | |
| 3 | action | 操作记录 | varchar | 50 | 非空 |
实现:
DROP TABLE IF EXISTS `log`;
CREATE TABLE IF NOT EXISTS LOG(
`id` INT(4) NOT null COMMENT '日志编号',
`time` DATE NOT NULL COMMENT '操作时间',
`action` VARCHAR(50) NOT NULL COMMENT '操作记录'
)COMMENT='日志表';
操作要求:
#- 将log表改名action_log ALTER TABLE `log` RENAME `action_log`; #- 添加备注(comment)字段,数据类型varchar(70) ALTER TABLE `action_log` ADD `comment` VARCHAR(70); #- time字段改名actiontime,数据类型改为DATETIME ALTER TABLE `action_log` CHANGE `time` `actiontime` DATETIME NOT NULL COMMENT '操作时间'; #- 删除备份(comment)字段 ALTER TABLE `action_log` DROP `comment`;
添加主键
ALTER TABLE 表名 ADD CONSTRAINT 主键名 PRIMARY KEY 表名(主键字段) #获取帮助 HELP ALTER TABLE; #查表 SHOW TABLES; #查库 show databases; #查表的结构 DESCRIBE action_log; DESC 表名 #查表中约束 SHOW CREATE TABLE 表名 #删除表中约束 alter table `表名` drop FOREIGN key `约束名`;
示例:
#将action_log表中id字段设置为主键 ALTER TABLE `action_log` ADD CONSTRAINT `pk_action_log` PRIMARY KEY `action_log`(id);
添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY(外键字段) REFERENCES 关联表名(关联字段);
示例:
#将处方表prescription的depID字段与department表depID字段建立主外键关联 ALTER TABLE `prescription` ADD CONSTRAINT fk_prescription_department FOREIGN KEY(depID) REFERENCES department(depID);
注:MyISAM存储类型的表不支持外键,所以通过逻辑关联方式保证数据完整性和一致性
实验:
#为prescription表添加主键约束:病人编号、开处方科室编号、检查项目编号、检查时间构成组合主键 ALTER TABLE `prescription` ADD CONSTRAINT pk_prescription PRIMARY KEY(patientID,checkitemID,depID,examDate); #为department_checkitem表添加外键约束 #-主表checkitem和从表department_checkitem通过checkItemID字段建立主外键关联 ALTER TABLE `department_checkitem` ADD CONSTRAINT `fk_department_checkitem_checkitem` FOREIGN KEY(checkitemID) REFERENCES checkitem(checkitemID); #-主表department和从表department_checkItem通过depID字段建立主外键关联 ALTER TABLE `department_checkitem` ADD CONSTRAINT `fk_department_checkitem_department` FOREIGN KEY(depID) REFERENCES department(depID);
数据操纵语言(必备技能!!!!!!!)
-
DML(Data Manipulation Language)
-
DML对数据库中表执行操作:
-
插入(INSERT)
-
-
插入单行数据
-
插入多行数据
-
将查询结果插入到新表
-
-
更新(UPDATE)
-
删除(DELETE)
-
-
软件开发人员日常使用最频繁的操作
DML——插入单条语句
INSERT INTO 表名[(字段名列表)] values(值列表);
说明:
-
字段名是可选的,如省略,则依次插入所有字段
-
多个列表和多个值之间使用逗号分开
-
值列表和字段名列表一一对应
-
如果插入表中的部分字段数据,则字段名列表必填字段不能省
INSERT INTO `patient`(`password`,`birthdate`,`gender`,`patientName`,`phoneNum`,`email`,`identityNum`,`address`)
VALUES('123456','1985-06-07','女','夏颖','13800000000','xiaying@126.com','110000198512060711','天津市');
DML——插入多条语句
INSERT INTO 表名[(字段名列表)] values(值列表1),(值列表2),.....,(值列表n);
INSERT INTO `patient`(`password`,`birthdate`,`gender`,`patientName`,`phoneNum`,`email`,`identityNum`,`address`)
VALUES('123456','1985-06-08','男','李政','13800000002','lizheng@163.com','110000198506081100','天津市')
,('123456','2010-03-02','女','李沁','13800000003','liqin@sohu.com','110000201003021100','天津市')
,('123456','1999-01-02','女','李思雨','13800000004','siyv@hotmail.com','110000199901021100','天津市')
,('123456','2008-10-17','男','夏天','13800000005','xiatian@qq.com','110000200810171100','天津市')
INSERT INTO `checkitem`(checkitemName,checkitemCost)
VALUES('血常规',30.0),('尿常规',20),('血脂检查',25),('凝血五项',50),('肺炎支、衣原体(快速)',66);
经验:避免表结果发生变化,写明具体字段名!
DML——将查询结果插入到新表
| SQL Server | 对比 | MySQL | 说明 |
|---|---|---|---|
| INSERT INTO 新表(字段1,字段2,……) SELECT 字段1,字段2,…… FROM 原表; | 相同 | INSERT INTO 新表(字段1,字段2,……) SELECT 字段1,字段2,…… FROM 原表; | 原先有表 添加查询 |
| SELECT 字段1,字段2,…… INTO 新表 FROM 原表; | 不同 | CREATE TABLE 新表 (SELECT 字段1,字段2,…… FROM 原表); | 原先无表 只用一次 |
示例:
#原先ptemp表存在 INSERT INTO ptemp(patientID,password) SELECT patientID,password FROM patient #查询并创建表ptemp,仅使用一次 CREATE TABLE ptemp SELECT patientID,password FROM patient
DML——更新数据
UPDATE 表名 SET 字段1=值1,字段2=值2,……,字段n=值n [WHERE 条件];
示例:
--修改夏颖的邮箱和地址 UPDATE patient SET email='ying.xia@qq.com',address='西安市' WHERE patientName='夏颖'
DML——删除数据
删除数据记录
DELETE FROM 表名[WHERE 条件];--删除数据,自增继续 TRUNCATE TABLE 表名;--删除数据,保留结构等,自增重置,语句效率高
示例:
DELETE FROM ptemp WHERE patientID=1; TRUNCATE TABLE ptemp;
比较DROP、DELETE、TRUNCATE
| DROP | DELETE | TRUNCATE | |
|---|---|---|---|
| 类型 | DDL 会隐式提交,不能回滚 | DML 删除数据是记录redo和undo表空间,以便回滚,手动提交,ROLLBACK回滚撤销 | DDL 隐式提交,不记日志,不能回滚 |
| 功能 | 删除表结构及所有数据,并释放空间 | 删除满足条件的数据,无条件全删 | 删除表中记录,重建表结构 |
说明:
-
执行速度:DORP>TRUNCATE>DELETE
-
慎重使用DROP、TRUNCATE
-
使用DELETE语句删除表中部分数据使用WHERE子句,且要注意表空间足够大
实验练习:
病人表(patient)
| 病人姓名 | 性别 | 出生日期 | 联系电话 | 邮箱 | 登录密码 | 身份证号 | 地址 |
|---|---|---|---|---|---|---|---|
| 刘占波 | 男 | 1999-03-08 | 13800000006 | zhanbo@163.com | 678901 | 210000199003082100 | 惠州市 |
| 廖慧颖 | 女 | 1987-05-02 | 13800000007 | huiying@qq.com | 789012 | 220000198705022200 | 广州市 |
| 李伟忠 | 男 | 1975-03-02 | 13800000008 | wz@qq.com | 890123 | 230000197503022300 | 沈阳市 |
| 姚维新 | 男 | 1986-10-11 | 13800000009 | ywz@hotmail.com | 901234 | 310000198610113100 | 北京市 |
| 陈建 | 男 | 1975-03-04 | 13800000010 | cz@qq.com | 012345 | 320000197503043200 | 北京市 |
| 林永清 | 女 | 1992-01-01 | 13800000011 | yongqing@qq.com | 098765 | 330000199201013300 | 长春市 |
| 李亚 | 女 | 1993-03-02 | 13800000012 | liya@qq.com | 987654 | 340000199303023400 | 保定市 |
INSERT INTO `patient`(`patientName`,`gender`,`birthdate`,`phoneNum`,`email`,`password`,`identityNum`,`address`)
VALUES('刘占波','男','1999-03-08','13800000006','zhanbo@163.com','678901','210000199003082100','惠州市')
,('廖慧颖','女','1987-05-02','13800000007','huiying@qq.com','78901','2220000198705022200','广州市')
,('李伟忠','男','1975-03-02','13800000008','wz@qq.com','890123','230000197503022300','沈阳市')
,('姚维新','男','1986-10-1','113800000009','ywz@hotmail.com','901234','310000198610113100','北京市')
,('陈建','男','1975-03-04','13800000010','cz@qq.com','012345','320000197503043200','北京市')
,('林永清','女','1992-01-0','113800000011','yongqing@qq.com','098765','330000199201013300','长春市')
,('李亚','女','1993-03-02','13800000012','liya@qq.com','987654','340000199303023400','保定市');
科室表(department)
| 科室编号 | 科室名称 |
|---|---|
| 1 | 急诊科 |
| 2 | 呼吸科 |
| 3 | 内科 |
INSERT INTO `department`(`depName`)
VALUES('急诊科'),('呼吸科'),('内科');
科室检查项目关系表(department_checkItem)
| 科室编号 | 检查项目编号 |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 1 |
| 2 | 5 |
| 3 | 1 |
| 3 | 2 |
| 3 | 3 |
| 3 | 4 |
INSERT INTO `department_checkItem`(depID,checkItemID) VALUES(1,1),(1,2),(2,1),(2,5),(3,1),(3,2),(3,3),(3,4);
处方表(prescription)
| 病人编号 | 开处方的科室编号 | 检查结果 | 检查项目编号 | 检查日期 |
|---|---|---|---|---|
| 1 | 1 | 正常 | 1 | 2020-01-02 |
| 1 | 1 | 正常 | 2 | 2020-01-02 |
| 2 | 2 | 肺炎支原体阳性 | 5 | 2020-04-05 |
| 1 | 1 | 正常 | 1 | 2020-02-06 |
| 8 | 3 | 正常 | 4 | 2020-03-02 |
| 8 | 3 | 血糖偏高 | 3 | 2020-03-02 |
| 8 | 3 | 正常 | 1 | 2020-03-02 |
| 10 | 3 | 正常 | 3 | 2020-03-02 |
| 1 | 1 | 白细胞数量偏高 | 1 | 2020-07-08 |
INSERT INTO `prescription`(patientID,depID,checkResult,checkItemID,examDate) VALUES(1,1,'正常',1,'2020-01-02') ,(1,1,'正常',2,'2020-01-02') ,(2,2,'肺炎支原体阳性',5,'2020-04-05') ,(1,1,'正常',1,'2020-02-06') ,(8,3,'正常',4,'2020-03-02') ,(8,3,'血糖偏高',3,'2020-03-02') ,(8,3,'正常',1,'2020-03-02') ,(10,3,'正常',3,'2020-03-02') ,(1,1,'白细胞数量偏高',1,'2020-07-08');
修改病人表数据
-- 将姓名为“刘占波”的病人密码修改为8765
UPDATE `patient`
SET `password`='8765'
WHERE `patientName`='刘占波';
-- 将血常规检查价格减少2元
UPDATE `checkitem`
SET `checkitemCost`=`checkitemCost`-2
WHERE `checkitemName`='血常规';
数据查询语句(DQL :Data Query Language)
-
用于查询数据库的表中数据
-
是数据库中最为核心的语句,使用频率最高
SELECT <字段名列表> FROM <表名或视图> [WHERE <查询条件>] [GROUP BY <分组的字段名>] [HAVING <条件>] [ORDER BY<排序的字段名>[ASC或DESC]]
经验:
为调高效率建议使用:SELECT <字段名列表> FROM <表名或视图> WHERE <查询条件>结构
常用函数
SQL中常用的操作封装,为程序员提供便利,提高开发效率
常用函数有:
-
字符串函数
-
时间日期函数
-
聚合函数
-
数学函数
字符串函数
| 函数名 | 作用 | 举例 |
|---|---|---|
| CONCAT(str1,str2,...,strn) | 连接字符串 | SELECT CONCAT('hello',' ','world!'); 结果:hello world! |
| LOWER(str) | 转小写 | SELECT LOWER('Hello'); 结果:hello |
| UPPER(str) | 转大写 | SELECT UPPER('Hello'); 结果:HELLO |
| SUBSTRING(str,num,len) | 从num处截取字符串len长 | SELECT SUBSTR('Hello world!',7,5); 结果:world |
| INSERT(str,pos,len,newstr) | 从pos处插入len长替换为str | SELECT INSERT('Hello world!',7,5,'Lee'); 结果:Hello lee! |
时间日期函数
| 函数名 | 作用 | 举例 |
|---|---|---|
| CURDATE() | 获取当前日期 | SELECT CURDATE(); 结果:2022-05-12 |
| CURTIME() | 获取当前时间 | SELECT CURTIME(); 结果:08:45:02 |
| NOW() | 获取当前日期和时间 | SELECT NOW(); 结果:2022-05-12 08:45:38 |
| WEEK(date) | 返回日期date为一年中第几周 | SELECT WEEK(NOW()); 结果:19 |
| YEAR(date) | 返回日期data年份 | SELECT YEAR(NOW()); 结果:2022 |
| HOUR(time) | 返回日期data小时 | SELECT HOUR(NOW()); 结果:8 |
| MINUTE(time) | 返回日期data分钟 | SELECT MINUTE(NOW()); 结果:47 |
| DATEDIFF(date1,date2) | 返回日期data1,date2间隔天数 距之前日期结果为正,之后为负 | SELECT DATEDIFF(NOW(),'2022-5-1'); 结果:1 |
| ADDDATE(date,n) | 返回日期data加上n天后日期 | SELECT ADDDATE(NOW(),7); 结果:2022-05-19 08:51:19 |
| UNIX_TIMESTAMP(date) | 日期转换成时间戳 | SELECT UNIX_TIMESTAMP('2022-5-12'); 结果:1652284800 |
聚合函数
| 函数名 | 作用 | 举例 |
|---|---|---|
| COUNT() | 返回统计记录总数 | SELECT COUNT(checkItemID) FROM checkitem; 建议:使用主键或int型字段 |
| MAX() | 返回某字段最大值 | SELECT MAX(checkItemCost) FROM checkitem; |
| MIN() | 返回某字段最小值 | SELECT MIN(checkItemCost) FROM checkitem; |
| SUM() | 返回某字段总和 | SELECT SUM(checkItemCost) FROM checkitem; |
| AVG() | 返回某字段平均数 | SELECT AVG(checkItemCost) FROM checkitem; |
建议:查询结果使用别名
数学函数
| 函数名 | 作用 | 举例 |
|---|---|---|
| CEIL(x) | 返回大于等于数值x的最小整数 | SELECT CEIL(2.1);结果:3 SELECT CEIL(-2.1);结果:-2 |
| FLOOR(x) | 返回小于等于数值x的最大整数 | SELECT FLOOR(2.1);结果:2 SELECT FLOOR(-2.1);结果:-3 |
| RAND() | 返回0~1间的随机数 | SELECT RAND(); 结果:0.8137022227176486 |
分页查询(LIMIT)
SELECT <字段名列表> FROM <表名或视图> [WHERE <查询条件>] [GROUP BY <分组的字段名>] [HAVING <条件>] [ORDER BY<排序的字段名>[ASC或DESC]] [LIMIT[位置偏移量,]行数]; #位置偏移量——从0开始 #行数——显示条数 #LIMIT后只有一个数字时——取行数
经验:通常和ORDER BY子句一起使用,先排序后取范围
实验示例(查询病人表):
-- 查询2020年2月以前做过血常规检查的病人编号、检查结果和检查时间
SELECT patientID,checkResult,examDate
FROM prescription
WHERE checkItemID=1 and examDate<='2020-02-01';
-- 查询所有年龄大于20岁的病人,并按照按年龄从小到大排序,显示从第3条到第5条记录的病人的姓名、性别、年龄、手机号码和住址
SELECT patientName,gender,FLOOR(DATEDIFF(CURDATE(),birthDate)/365) AS age,phoneNum,address
FROM patient
WHERE FLOOR(DATEDIFF(CURDATE(),birthDate)/365)>20
ORDER BY FLOOR(DATEDIFF(CURDATE(),birthDate)/365) ASC
LIMIT 2,3;
-- 查询所有病人的最大年龄,最小年龄和平均年龄
SELECT MAX(FLOOR(DATEDIFF(CURDATE(),birthDate)/365)) AS MaxAge,MIN(FLOOR(DATEDIFF(CURDATE(),birthDate)/365)) AS MinAge,AVG(FLOOR(DATEDIFF(CURDATE(),birthDate)/365)) AS AvgAge
FROM patient;
子查询
查询嵌套
SELECT patientID,checkResult,examDate
FROM prescription
WHERE checkItemID=(
SELECT checkitemId
FROM checkitem
WHERE checkItemName='血常规') and examDate<='2020-02-01';
子查询嵌套在SELECT、UPDATE、INSERT、DELETE
子查询在WHERE语句中
SELECT …… FROM 表1 WHERE 字段1 比较运算符(子查询);
AS关键字
起别名,ANSI标准
别名使用处:表、字段、查询结果
别名一旦使用,就必须统一使用否则报错
SELECT 字段列表 FROM 表名 AS 表别名; #简便方法 SELECT 字段列表 FROM 表名 表别名;-- 使用空格替代AS
示例:
-- 查询所有年龄大于20岁的病人 -- FLOOR(DATEDIFF(CURDATE(),birthDate)/365)>20 -- 并按照按年龄从大到小排序, -- 显示病人的姓名、性别、年龄 SELECT patientName,gender,t.age FROM (SELECT patientName,gender,FLOOR(DATEDIFF(CURDATE(),birthDate)/365) AS age FROM patient) as t WHERE t.age>=20 ORDER BY age DESC
实验示例:
-- 查询姓名为“夏颖”的病人
-- - 第一次“血常规”检查的时间及检查结果
SELECT examDate,checkResult
FROM prescription
WHERE patientID=(
SELECT patientID
FROM patient
WHERE patientName='夏颖')
AND checkitemId=(
SELECT checkitemID
FROM checkitem
WHERE checkitemName='血常规')
ORDER BY examDate ASC
LIMIT 1
-- - 最后一次“血常规”检查的时间及检查结果
SELECT examDate,checkResult
FROM prescription
WHERE patientID=(SELECT patientID FROM patient WHERE patientName='夏颖')
AND checkitemId=(SELECT checkitemID FROM checkitem WHERE checkitemName='血常规')
ORDER BY examDate DESC
LIMIT 1
准备
-
IN子查询的功能是什么?
-
EXISTS子查询能实现什么样的功能?
-
使用子查询时有哪些注意事项?
目标
-
掌握IN子查询的用法
-
掌握EXISTS子查询
-
掌握子查询的使用原则和注意事项
-
能够使用SQL进行综合查询
-- 查询在“2020-01-02”做过“尿常规”这项检查的病人名单
-- 要求:使用多种方法
-- 一、采用表连接
-- 使用INNER JOIN
SELECT patientName
FROM patient
INNER JOIN prescription on patient.patientID=prescription.patientID
INNER JOIN checkitem on prescription.checkItemID=checkitem.checkItemID
WHERE checkitem.checkItemName ='尿常规' and prescription.examDate='2020-01-02'
-- 使用WHERE
SELECT patientName
FROM patient,prescription,checkitem
WHERE patient.patientID=prescription.patientID
and prescription.checkItemID=checkitem.checkItemID
and checkitem.checkItemName ='尿常规'
and prescription.examDate='2020-01-02'
-- 二、使用子查询
SELECT patientName FROM patient
WHERE patientID=(SELECT patientID
FROM prescription
WHERE checkitemID=(SELECT checkitemID
FROM checkitem
WHERE checkitemName='尿常规')
AND examDate='2020-01-02');
IN子查询
子查询返回多值时使用
语法:
SELECT......FROM 表名 WHERE 字段名 IN(子查询);
-- 查询在"2020-03-02"做过"血脂、血糖检查"的病人名单
SELECT patientName FROM patient
WHERE patientID IN (SELECT patientID
FROM prescription
WHERE checkitemID=(SELECT checkitemID
FROM checkitem
WHERE checkitemName='血脂检查')
AND examDate='2020-03-02');
-- 查询最近一次开出过"血脂检查"的科室看过的病人姓名
-- 查询病人姓名
SELECT patientName FROM patient
WHERE patientID IN (
-- 查询病人的科室
SELECT patientID FROM prescription
WHERE depID IN (
-- 最近一次时间开出过"血脂检查"的科室
SELECT depID FROM prescription WHERE examDate=(
SELECT MAX(examDate) FROM prescription WHERE checkItemID=
(SELECT checkitemID FROM checkitem WHERE checkitemName='血脂检查')))
AND checkitemID=(
-- 血脂检查编号
SELECT checkitemID FROM checkitem WHERE checkitemName='血脂检查'))
分析:
NOT IN 子查询
-- 查询最近一次开出过"血脂检查"的科室以外其他科室看过的病人姓名
SELECT patientName FROM patient
WHERE patientID IN (
-- 查询病人的科室
SELECT patientID FROM prescription
WHERE depID NOT IN (
-- 最近一次时间开出过"血脂检查"的科室
SELECT depID FROM prescription WHERE examDate=(
SELECT MAX(examDate) FROM prescription WHERE checkItemID=
(SELECT checkitemID FROM checkitem WHERE checkitemName='血脂检查')))
AND checkitemID=(
-- 血脂检查编号
SELECT checkitemID FROM checkitem WHERE checkitemName='血脂检查'))
实践示例:
-- 查询开具“血常规”检查的科室
SELECT depName FROM department WHERE depID IN(
-- 查询科室编号
SELECT depID FROM department_checkitem WHERE checkitemID=(
-- 查询血常规编号
SELECT checkitemID FROM checkitem WHERE checkitemName='血常规'))
-- 查询不能开具“血脂检查”检查的科室
-- 查询开具“血脂检查”检查的科室
SELECT depName FROM department WHERE depID NOT IN(
-- 查询科室编号
SELECT depID FROM department_checkitem WHERE checkitemID=(
-- 查询血脂检查编号
SELECT checkitemID FROM checkitem WHERE checkitemName='血脂检查'))
EXISTS 子查询
-- 判断表存在问题 DROP TABLE IF EXISTS temp; CREATE TABLE temp( ...... );
SELECT ...... FROM 表名 WHERE EXISTS (子查询); /* 说明: 子查询 有 返回结果:EXISTS返TRUE 子查询 无 返回结果:EXISTS返FALSE===>外层查询不执行 */
-- 查找是否有病人做过"血脂检查"
SELECT patientName
FROM patient
WHERE EXISTS( -- 如果有,请显示做过检查的病人姓名
-- 血脂检查的病人编号
SELECT patientID
FROM prescription
WHERE checkitemID=(SELECT checkitemID
FROM checkitem
WHERE checkitemName='血脂检查')
AND patient.patientID=prescription.patientID);
NOT EXISTS : 表示结果集中没有记录返回TRUE,否则FALSE
-- 检查病人"刘占波"是否做过"凝血五项"检查
-- 如果没有做过,插入一条记录
-- 以"内科"名义在今天给他开一个"凝血五项"检查
INSERT INTo prescription(patientID,depID,examDate,checkitemID)
-- 判断以下查询结果,没有结果时执行外层SQL操作
SELECT patientID,3 as depID, CURDATE() AS examDate,4 AS checkitemID
FROM patient
WHERE NOT EXISTS
(SELECT patientID
FROM prescription
WHERE checkitemID=
(SELECT checkitemID
FROM checkitem
WHERE checkitemName='凝血五项')-- 查询“凝血五项”检查编号
AND patient.patientID=prescription.patientID) -- 查询“病人编号”条件
AND patientName='刘占波';
小结:
什么是子查询?
-
当一个查询为另一个查询的条件时,称为子查询。
子查询可以出现的位置?
-
任何允许使用表达式的地方
-
嵌套在父查询SELECT语句的子查询,可包括:
-
SELECT子句
SELECT (子查询)[AS 类别名] FROM 表名;
-
FROM子句
SELECT * FROM (子查询) AS 表别名;
-
WHERE子句
-
GROUP BY子句
-
HAVING子句
-
子查询注意事项:
通常,将子查询放在比较条件的右侧以增加可读性
子查询可以返回单行或多行数据,此时注意条件关键字选择:
-
子查询返单行数据时,比较条件中使用——比较运算符
-
子查询返多行数据时,比较条件中使用——IN 或 NOT IN 关键字
-
如需判断子查询是否返回数据时,需使用——EXISTS 或 NOT EXISTS 关键字
只出现子查询中、没有出现在父查询中的类不能包含在输出列中
实验示例:
-- 统计病人最近在医院的总花费
-- 思路:
-- 1.查询获取病人最近一次到医院看病的日期,使用 GROUP BY 子句
SELECT MAX(examDate),patientID
FROM prescription
GROUP BY patientID;
-- 2.使用 IN 子句查询匹配病人最近一次看病的时间
-- -在父查询的SELECT子查询中嵌套子查询在 patient 表中查询病人名字
SELECT(SELECT patientName
FROM patient
WHERE patientID=p1.patientID) AS patientName
,examDate,checkitemId
FROM prescription AS p1
WHERE p1.examDate IN (
SELECT MAX(examDate)
FROM prescription p2
WHERE p1.patientID=p2.patientID
GROUP BY patientID
);
-- 3.使用表连接关联 prescription 表和 checkitem 表,通过对 patientID 分组,
-- 使用 SUM() 函数计算病人当天的总花费
SELECT(SELECT patientName
FROM patient
WHERE patientID=p1.patientID) AS patientName,
SUM(checkitemCost) AS totalCost,examDate
FROM prescription AS p1 INNER JOIN checkitem ON p1.checkItemID=checkitem.checkitemId
WHERE p1.examDate IN (
SELECT MAX(examDate)
FROM prescription p2
WHERE p1.patientID=p2.patientID
GROUP BY patientID
)
GROUP BY patientID;
实验示例:
| 学生表 | Student | |||
|---|---|---|---|---|
| 字段名称 | 字段说明 | 数据类型 | 长度 | 属性 |
| studentNo | 学生编号 | INT | 4 | 非空,主键 |
| loginPwd | 登录密码 | VARCHAR | 20 | 非空 |
| studentName | 姓名 | VARCHAR | 50 | 非空 |
| sex | 性别 | CHAR | 2 | 非空,默认“男” |
| gradeId | 年级编号 | INT | 4 | 无符号 |
| phone | 联系电话 | VARCHAR | 50 | |
| address | 地址 | VARCHAR | 255 | 默认值“地址不详” |
| bornDate | 出生日期 | DATETIME | ||
| 邮件账号 | VARCHAR | 50 | ||
| IdentityCard | 身份证号 | VARCHAR | 18 | 唯一 |
| 课程表 | Subject | |||
|---|---|---|---|---|
| 字段名称 | 字段说明 | 数据类型 | 长度 | 属性 |
| subjectNo | 课程编号 | INT | 4 | 非空,主键,标识列,自增1 |
| subjectName | 课程名称 | VARCHAR | 50 | |
| classHour | 学时 | INT | 4 | |
| gradeID | 年级编号 | INT | 4 |
| 成绩表 | Result | |||
|---|---|---|---|---|
| 字段名称 | 字段说明 | 数据类型 | 长度 | 属性 |
| studentNo | 学号 | INT | 4 | 非空 |
| subjectNo | 课程编号 | INT | 4 | 非空 |
| examDate | 考试日期 | DATETIME | 非空 | |
| studentResult | 考试成绩 | INT | 4 | 非空 |
| 年级表 | Grade | |||
|---|---|---|---|---|
| 字段名称 | 字段说明 | 数据类型 | 长度 | 属性 |
| gradeID | 年级编号 | INT | 4 | 非空,标识列,自增1 |
| gradeName | 年级名称 | VARCHAR | 50 | 非空 |
数据填充:
| 表:grade | |
|---|---|
| 年级编号 | 年级名称 |
| 1 | 一学年 |
| 2 | 二学年 |
| 3 | 三学年 |
| 表:subject | |||
|---|---|---|---|
| 课程编号 | 课程名称 | 学时 | 年级编号 |
| 1 | Logic Java | 220 | 1 |
| 2 | HTML | 160 | 1 |
| 3 | Java OOP | 230 | 2 |
| 表 | student | ||||||
|---|---|---|---|---|---|---|---|
| 学生编号 | 登录密码 | 姓名 | 性别 | 年级编号 | 联系电话 | 地址 | 出生日期 |
| 10000 | 012345 | 郭靖 | 男 | 1 | 13645678983 | 天津市西区 | 1990/9/8 |
| 10001 | 123456 | 李文才 | 男 | 1 | 13532165487 | 地址不详 | 1994/4/12 |
| 10002 | 234567 | 李思文 | 男 | 1 | 13645698752 | 河南洛阳 | 1995/7/23 |
| 10003 | 345678 | 张平 | 女 | 1 | 13854648724 | 地址不详 | 1995/6/10 |
| 10004 | 456789 | 韩秋杰 | 女 | 1 | 13579546521 | 北京市海淀区 | 1995/7/15 |
| 10005 | 567890 | 张秋丽 | 女 | 1 | 13065498354 | 北京市新城区 | 1994/1/17 |
| 10006 | 678901 | 肖梅 | 女 | 1 | 15065449873 | 河北省石家庄市 | 1991/2/17 |
| 10007 | 789012 | 秦洋 | 男 | 1 | 13365498775 | 上海市卢湾区 | 1992/4/18 |
| 10008 | 890123 | 何青青 | 女 | 1 | 13689756421 | 广州市天河区 | 1997/7/23 |
| 20000 | 901234 | 王宝宝 | 男 | 2 | 13689717286 | 地址不详 | 1966/6/5 |
| 20010 | 012345 | 何小华 | 女 | 2 | 13697654214 | 地址不详 | 1995/9/10 |
| 30011 | 098765 | 陈志强 | 女 | 3 | 15854698321 | 地址不详 | 1994/9/27 |
| 30012 | 987654 | 李露露 | 女 | 3 | 16946542185 | 地址不详 | 1992/9/27 |
| 表 | result | ||
|---|---|---|---|
| 学号 | 课程编号 | 考试日期 | 考试成绩 |
| 10000 | 1 | 2019-02-07 | 71 |
| 10001 | 1 | 2019-02-07 | 46 |
| 10002 | 1 | 2019-02-07 | 83 |
| 10003 | 1 | 2019-02-07 | 60 |
| 10004 | 1 | 2019-02-07 | 60 |
| 10005 | 1 | 2019-02-07 | 95 |
| 10006 | 1 | 2019-02-07 | 93 |
| 10007 | 1 | 2019-02-07 | 23 |
脚本:
-- 搭建数据库 CREATE TABLE student( `studentNo` INT(4) NOT NULL COMMENT '学生编号' PRIMARY KEY, -- 非空,主键, `loginPwd` VARCHAR(20) NOT NULL COMMENT '登录密码',-- 非空, `studentName` VARCHAR(50) NOT NULL COMMENT '姓名', -- 非空, `sex` CHAR(2) DEFAULT '男' NOT NULL COMMENT'性别', -- 非空,默认“男”, `gradeId` INT(4) UNSIGNED COMMENT '年级编号', -- 无符号, `phone` VARCHAR(50) COMMENT'联系电话', `address` VARCHAR(255) DEFAULT '地址不详' COMMENT '地址',-- 默认值“地址不详”, `bornDate` DATETIME COMMENT '出生日期', `email` VARCHAR(50) COMMENT'邮件账号', `IdentityCard` VARCHAR(18) UNIQUE KEY COMMENT'身份证号'-- 唯一 )COMMENT='学生表'; CREATE TABLE subjet( `subjectNo`INT(4) NOT NULL COMMENT'课程编号' PRIMARY KEY AUTO_INCREMENT,-- 非空,主键,标识列,自增1 `subjectName`VARCHAR(50) COMMENT'课程名称', `classHour`INT(4) COMMENT'学时', `gradeID`INT(4) COMMENT'年级编号' )COMMENT '课程表'; CREATE TABLE result( `studentNo`INT(4) NOT NULL COMMENT'学号' ,-- 非空 `subjectNo`INT(4) NOT NULL COMMENT'课程编号',-- 非空 `examDate` DATETIME NOT NULL COMMENT'考试日期',-- 非空 `studentResult`INT(4) NOT NULL COMMENT'考试成绩'-- 非空 )COMMENT '成绩表'; CREATE TABLE grade( `gradeID`INT(4) NOT NULL UNIQUE KEY AUTO_INCREMENT COMMENT'年级编号' ,-- 非空,标识列,自增1 `gradeName`VARCHAR(50) NOT NULL COMMENT'年级名称'-- 非空 );
实验示例:
-- 查询学生信息
-- -查询2019年2月17日考试前5名的学生的学号和分数
SELECT studentNo,studentResult
FROM result
WHERE examDate='2019-02-17'
ORDER BY studentResult DESC
LIMIT 5;
-- -将女生按年龄从大到小排序,从第2条开始显示6名女生的姓名、年龄、出生日期、手机号码信息
SELECT studentName,FLOOR(DATEDIFF(CURDATE(),bornDate)/365) AS age,bornDate,phone
FROM student
WHERE sex='女'
ORDER BY bornDate DESC
LIMIT 1,6;
-- -查询参加2019年2月17日考试的所有学员的最高分、最低分、平均分
SELECT MAX(studentResult) AS '最高分',MIN(studentResult) AS '最低分',AVG(studentResult) AS '平均分'
FROM result
WHERE examDate='2019-02-17';
-- 查询指定学生的考试成绩
-- -查询参加最近一次Logic Java考试成绩的学生的最高分和最低分
SELECT MAX(studentResult) AS '最高分',MIN(studentResult) AS '最低分'
FROM result
WHERE subjetNo=(SELECT subjetNo
FROM subjet
WHERE subjetName='Logic Java')
AND
examDate=(SELECT MAX(examDate)
FROM result
WHERE subjetNo=(SELECT subjetNo
FROM subjet
WHERE subjetName='Logic Java'))
-- 查询某课程缺考的学生名单
-- -使用NOT IN关键字的子查询来查询未参加HTML课程最近一次考试的在读学生名单
SELECT studentName
FROM student
WHERE studentNo NOT IN(
SELECT subjetNo
FROM subjet
WHERE subjetNo=(
SELECT subjetNo
FROM subjet
WHERE subjetName='HTML')
AND examDate=(
SELECT MAX(examDate)
FROM subjet
WHERE subjetNo=(
SELECT subjetNo
FROM subjet
WHERE subjetName='HTML')))
AND ??
企业级开发技术
准备:
-
什么是事务?事务的功能及使用场景是什么?
-
事务具有的4个特性是什么?
-
索引的常见类型有哪些?
-
视图的使用场景是什么?
-
常见的备份和恢复MySQL数据库的方法有哪些?
目标:
-
掌握使用事务保证操纵数据的完整性的方法
-
掌握如何创建并使用索引
-
掌握如何创建并使用视图
-
掌握如何进行数据库的备份和恢复
事务(TRANSACTION):
-
将一系列数据操作捆绑成一个整体进行统一管理的机制
-
多个操作作为一个整体向系统提交,要么执行、要么不执行
-
是一个不可分割的工作逻辑单元
事务特性(ACID):
Atomicity(原子性):事务各步操作作为一个整体向系统提交,要么执行、要么不执行
Consistency(一致性):当事务完成时,数据必须处于一致状态
Isolation(隔离性):并发事务之间彼此隔离、独立,不应以任何方式依赖于或影响其他事务
Durabitity(持久性):事务完成后,他对数据库的修改被永久保持
创建事务:
MySQL中支持事务的存储引擎
-
InnoDB支持事务
-
通过UNDO日志和REDO日志实现对事物的支持
-
UNDO日志:复制事务执行前的数据,用于在事务发生异常时回滚数据
-
REDO日志:记录在事务执行中,每条对数据进行更新的操作;当事务提交时,将内容刷新到磁盘
-
-
-
MyISAM不支持事务
实现事务的方式:
-
SQL语句
-
设置自动提交关闭或开启
屏蔽自动提交:SET autocommit=0
语法:
#开始事务 BEGIN; 或 START TRANSACTION; #提交 COMMIT; #回滚 ROLLBACK; #设置自动提交 SET autocommit=0|1; 0:关闭自动提交 1:开启自动提交
示例:
#转账事务
SET autocommit=0;
-- BEGIN;
-- 或
START TRANSACTION;
UPDATE `account` SET balance=balance-500 WHERE `accountName`='张三';
UPDATE `account` SET balance=balance+500 WHERE `accountName`='李四';
UPDATE `account` SET balance=balance+500 WHERE `accountName`='李四';
ROLLBACK;
SET autocommit=1;
使用事务原则:
-
事务尽可能简短,以期节省系统资源
-
事务中访问数量尽可能少,防止并发事务争夺资源
-
查询数据尽量不使用事务,因为不对数据进行操作
-
在事务处理过程中尽量不要出现等待用户输入的操作,防止长时占用系统资源等待阻塞
实验练习:
/*
使用事务为处方表插入多条数据(回滚事务)
--“夏颖”在呼吸科看病,医生给她开了“血常规”和“肺炎、支原体(快速)”两项检查
--由于今天医院试剂已用完,无法做“肺炎、支原体(快速)”检查,导致处方失败
观察表中结果
--正确提交
--回滚事务
思路:
1.关自动提交
2.开始事务
3.SQL语句
4.结束事务(提交|回滚)
5.开自动提交
*/
SET autocommit=0;
BEGIN;
-- SQL语句1;
-- SQL语句2;
-- ... ...
-- SQL语句N;
INSERT INTO prescription(patientID,depid,checkitemid,examDate)
VALUES((SELECT patientID FROM patient WHERE patientName='夏颖')
,(SELECT depid FROM department WHERE depName='呼吸科')
,(SELECT checkitemId FROM checkitem WHERE checkitemName='血常规')
,NOW());
INSERT INTO prescription(patientID,depid,checkitemid,examDate)
VALUES((SELECT patientID FROM patient WHERE patientName='夏颖')
,(SELECT depid FROM department WHERE depName='呼吸科')
,(SELECT checkitemId FROM checkitem WHERE checkitemName='肺炎、支原体(快速)')
,NOW());
COMMIT;-- 提交
ROLLBACK;-- 回滚
SET autocommit=1;
索引(INDEX)
-
数据存储在数据表中,索引市创建在数据库表的对象上
-
由表中的一个字段或多个字段生成的键的组成
-
是对数据库表中一列或多列值进行排列的一种结构
作用:
-
大大提高数据库的检索速度
-
改善数据库性能
MySQL索引按存储类型分类:
-
B-树索引(BTREE):InnoDB‘,MyISAM均支持
-
哈希索引(HASH)
常见索引类型:
| 索引类型 | 说明 |
|---|---|
| 普通索引 | 基本索引类型 允许在定义索引的列中插入重复值和空值 |
| 唯一索引 | 不允许在定义索引的列中插入重复值 允许有空值 |
| 主键索引 | 主键列每个值非空、唯一 主键列自动创建主键索引 |
| 复合索引 | 将多列组合作为索引 |
| 全文索引 | 支持值的全文查找 允许重复值和空值 |
示例:
商场会员卡系统
| 序号 | 字段名 | 字段说明 | 数据类型 | 示例 |
|---|---|---|---|---|
| 1 | id | 会员编号 | int | 可创建主键索引 |
| 2 | memName | 会员姓名 | varchar(10) | 可创建普通索引 |
| 3 | identityNum | 身份证号 | varchar(18) | 可创建唯一索引 |
| 4 | phoneNum | 会员电话 | varchar(20) | |
| 5 | address | 会员地址 | varchar(50) | |
| 6 | remark | 会员备注 | TEXT | 可创建全文索引 |
创建/删除索引
创建语法:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name ON table_name(column_name[length]...);
如果创建索引没有指定索引类型,创建的为普通索引
# 通过CREATE INDEX语句无法创建主键索引,需要下列语句 ALTER TABLE tablename ADD PRIMARY KEY(columnname);
删除语法:
DROP INDEX index_name ON table_name;
删除表时,该表的所有索引同时会被删除
示例:
| 表 | member | ||
|---|---|---|---|
| 序号 | 字段名 | 字段说明 | 数据类型 |
| 1 | id | 会员编号 | int |
| 2 | memName | 会员姓名 | varchar(10) |
| 3 | identityNum | 身份证号 | varchar(18) |
| 4 | phoneNum | 会员电话 | varchar(20) |
| 5 | address | 会员地址 | varchar(50) |
| 6 | remark | 会员备注 | TEXT |
示例:
#为会员表添加索引 #- 设置memName列为普通索引 CREATE INDEX index_memName ON member(memName); #- 设置identityNum列为唯一索引 CREATE UNIQUE INDEX index_identityNum ON member(identityNum); #- 设置id列为主键索引 ALTER TABLE member ADD PRIMARY KEY(id); #- 设置remark列为全文索引 CREATE FULLTEXT INDEX index_remark ON member(remark);
创建索引的指导原则
列选择创建原则
-
频繁搜索的列
-
经常用作查询选择列
-
经常排序、分组的列
-
经常用作连接的列(主键/外键)
列不选择原则
-
仅包含几种不同值的列
-
表中仅包含几行
使用索引注意事项
-
查询时减少使用“*”返回表中全部列,不要返回不需要的列
-
索引应该尽量小,字节数小的列上建立索引
-
WHERE子句中有多个条件表达式时,包含索引列的表达式应置于其他条件表达式之前
-
避免在ORDER BY子句中使用表达式
-
根据业务数据发生频率,定期重新生成或重新组织索引,进行碎片整理
查看索引
语法:
SHOW INDEX FROM 表名;
示例:
#查看数据库中patient表中索引 SHOW INDEX FROM patient;
删除索引
语法:
DROP INDEX index_name ON table_name;
示例:
#删除member表中remark列上全文索引 DROP INDEX index_remark ON member;
注意:
-
删除表时,该表的所有索引将同时删除
-
删除表中的列时,如果要删除的列为索引的组成部分,则该列也会从索引中删除
-
如果组成索引的所有列都被删除,则整个索引将被删除
实践示例:
#为病人表添加合适的索引 #-为提高查询速度,要为hospital数据库中病人表(patient)中的病人身份证号列(identityNum)和姓名(patientName)添加合适的索引 CREATE INDEX index_name ON patient(patientName);-- 普通索引 CREATE UNIQUE INDEX index_identityNum ON patient(identityNum);-- 唯一索引
视图(VIEW)
视图为不同的人关注不同的数据;保证信息的安全性
-
视图是一张“虚拟表”
-
表示一张表的部分数据或多张表的综合数据
-
其结构和数据是建立在对表的查询基础上
-
-
视图中不存在数据
-
数据存放在视图所引用的原始表中
-
-
一个原始表,根据不同用户的不同需求,可以创建不同的视图
-
用途:
-
筛选表中的行
-
防止未经许可的用户访问敏感数据
-
降低数据库复杂程度
-
将多个物理数据表抽象为一个逻辑数据表
-
-
优势:
-
开发人员
-
限制数据检索更方便
-
维护应用程序更方便
-
-
最终用户
-
结果更易理解
-
获取数据更容易
-
-
创建、查看视图
使用SQL语句创建视图
CREATE VIEW view_name AS <SELECT 语句>;
使用SQL语句删除视图
DROP VIEW [IF EXISTS] view_name;
使用SQL语句查看视图
SELECT 字段1,字段2,…… FROM view_name;
使用视图注意事项:
-
视图中可以是多个表
-
一个视图可以嵌套另一个视图,但最好不要超过3层
-
对视图数据进行添加、更新、删除操作会直接影响应用表中的数据
-
当视图数据来自多个表时,不允许添加和删除数据
查看视图
use information_schema; SELECT * FROM views \g;
经验:视图对修改数据有很多限制,一般实际开发中视图仅用于——查询
实践示例:
#使用视图查看病人的医疗费用 #-创建视图,显示病人编号和总的医疗费用 CREATE VIEW v_patient_cost AS SELECT prescription.patientid,patientName,SUM(checkitemCost) AS totalcost FROM prescription INNER JOIN checkitem ON prescription.checkitemId=checkitem.checkItemId INNER JOIN patient ON prescription.patientID=patient.patientID GROUP BY prescription.patientID;
数据库备份与恢复
为什么进行数据库备份:
可能导致数据丢失的意外情况
-
数据库故障
-
突然断电
-
病毒入侵
-
人为误操作
-
程序错误
-
运算错误
-
磁盘故障
-
灾难(如火灾、地震)和盗窃
-
……
数据备份
容灾基础
防止误操作或系统故障导致数据遗失,将全部或部分数据从应用主机分散或阵列复制到其他存储介质的过程
MySQL数据备份的常用方法
-
mysqldump备份数据库:客户端常用逻辑备份工具
-
CREATE和INSERT INTO语句保存到文本文件
-
属于DOS命令
-
语法:
mysqldump [options] database[table1,[table2].....] > [path]/filename.sql #指令 [连接数据库参数]备份数据库名[将备份的表名(不写是全部)] > [路径]/备份文件名 /* option参数: -u username:用户名 -h host :主机名,本机可省略 -p password:登录密码 */
注意:
1.DOS命令
2.使用时不仅如此mysql命令行
示例:
#以root账户登录到mysql服务器,使用命令行备份hospital数据库,存储到d:\ mysqldump -uroot -proot hospital >d:\20220518hospital.sql mysqldump -uroot -p hospital >d:\20220518hospital.sql Enter password: **** /* 指令说明: 注意密码明文,上面两种写法,推荐第二种 每行结束没有 ; sql文件说明: "-- "开头:关于SQL语句注释信息 "/*!开头,*/" 结尾 :关于MySQL服务器相关注释 */
常用参数:
| 参数 | 描述 |
|---|---|
| -add-drop-table | 在每个CREATE TABLE 语句前添加DROP TABLE语句, 默认打开,可用-skip-add-drop-table取消 |
| -add-locks | 该选项会在INSERT语句中绑定一个LOCK TABLE和UNLOCK TABLE 语句 好处:防止记录被再次导入时,其他用户进行操作 |
| -t或-no-create-info | 仅导出数据,而不添加CREATE TABLE语句 |
| -c或--commplete-insert | 在INSERT语句的列上加列名,在数据导入另一个数据库是有用 |
| -d或-no-date | 不写表的任何信息,只转储表结构 |
-
备份文件包含主要信息:
-
备份后文件包含MySQL服务器及mysqldump工具版本号
-
备份账户名称
-
主机信息
-
备份数据库名称
-
SQL语句注释和服务器相关注释
-
CREATE和INSERT语句
-
-
Navicat备份数据
右键点击数据库 --> 转储SQL文件 --> 结构和数据 ...
数据恢复
通过技术手段,将保存在硬盘的介质上的丢失的数据进行抢救和恢复的技术
导入方法:
-
使用mysql命令——DOS指令;要求事先创建数据库(因为创建备份文件没有建库指令)
语法:
mysql -u用户名 -p [导入的数据库名]<物理路径/备份文件名.sql Enter password:*******
示例:
/* 1. 登录数据库 2. 创建数据库 : tempdb 3. DOS环境下键入指令 */ mysql -uroot -p tempdb<d:/20220518hospital.sql #不加分号(;) Enter password: **** #成功后出现空行,没有提示
-
使用source命令——mysql 内部指令;数据库已连接状态下使用;使用将恢复到的数据库
语法
source 物理路径/备份文件名.sql
示例
/* 1. 登录数据库 2. 创建数据库 : tdb 3. 使用数据库tdb 3. 数据库中键入指令 */ source d:/20220518hospital.sql #不加分号(;) #语句执行过程逐条显示成功OK,只到结束
-
使用Navicat导入数据
1.右击要恢复的数据库
2.选择“运行SQL文件...”选项
3.导入窗口选择SQL文件
4.点击“开始”按钮导入数据
用户权限设置
MySQL默认的用户为root,拥有超级权限,不建议使用root用户
数据库管理员(DBA,Database Adminstrator)负责不同数据库使用者创建的一系列用户账号,授予不同权限
创建用户:
语法:
CREATE USER `username@host` [IDENTIFIED BY [PASSWORD]`password`]; /* 本地用户使用 localhost,可远程登录使用% IDENTIFIED,设置用户密码,默认为空 */
示例:
create user `lele@localhost` identified by '123456';
查看用户及相关权限
use mysql; #select * from user; #查看服务器、用户名、密码哈希值、查权限、增权限、改权限、删权限 select host,user,authentication_string,select_priv,insert_priv,update_priv,delete_priv from user;
删除用户
drop user `username1@host`[,`username2@host`......];
示例:
drop user `lele@localhost`;
创建用赋予权限
-
CREATE、DROP权限
-
INSERT、DELETE、UPDATE、SELECT权限
-
ALTER权限
语法:
GRANT priv_type ON 数据库名.表名 TO `username@host` [IDENTIFIED BY [PASSWORD] 'password' [WITH GRANT OPTION]; /* priv_type:权限 数据库名.表名:所有的话使用通配符 * `username@host`:用户名及服务器 IDENTIFIED BY:设置密码 PASSWORD:转换密码的函数 'password':密码明文 WITH GRANT OPTION:对新建用户赋予权限,可选项 */
示例:
GRANT select,delete ON hospital.* TO 'lele'@'localhost' IDENTIFIED BY '123456';
修改管理员账号
1-使用mysqladmin命令修改超级管理员账号密码
mysqladmin -u username -p password "newpassword" #要求新密码要有双引号
2-使用set语句
set password=PASSWORD("新密码");
3-修改mysql.user表
update mysql.user set password=**PASSWORD**("新密码") where user=“指定用户名” and host=“localhost” ;
4-mysql8.0修改密码指令
ALTER USER `username@host` IDENTIFIED BY '新密码'; #如遇报错,执行:flush privilege
管理其他账户密码
语法:
SET PASSWORD [FOR `username@host`]=PASSWORD("newpassword");
示例:
#GRANT select,delete ON hospital.*
# TO 'lele'@'localhost' IDENTIFIED BY '123456';
set password for 'lele'@'localhost' =password("lele");
密码丢失找回
-
管理员命令行停止服务 net stop mysql
-
指令 mysql --skip-grant-tables 键后不能操作,“任务管理器”(ctrl+shift+esc)有mysqld.exe,不关闭此窗口
-
新开管理员命令行,无密码登录mysql 指令:mysql -u用户名
-
update修改表 mysql库中user表:update mysql.user set password=PASSWORD("新密码") where user=“指定用户名” and host=“localhost”
-
修改成功后刷新权限:flush privilege 是密码生效
-
关闭运行 mysql --skip-grant-tables指令的窗口
-
启动服务 net start mysql(不能启动时,手动关闭“任务管理器”中mysqld.exe)
-
使用新密码正常登陆服务器
存储过程(Stored Procedure)
准备:
什么是存储过程?存储过程的功能是什么?
存储过程有哪些优势?
存储过程的流程控制是如何实现的?
目标:
理解存储过程的概念
会创建、修改、删除、查看存储过程
掌握存储过程的流程控制语句
什么是存储过程:
是一组为了完成特定功能的SQL语句的集合
经编译后存储数据库中
通过指定存储过程的名字并给出参数的值
MySQL5.0版本开始支持存储过程,是数据库引擎更强大灵活
可以有参数及返回值
可以包含数据操作语句、变量、逻辑控制语句
优点:
-
减少网络流量
-
提升执行速度
-
减少数据连接次数
-
安全性高
-
复用性高
缺点:
-
可移植性差
创建存储过程
语法:
CREATE PROCEDURE 过程名([过程参数[,过程参数[,......]]]) [特性] 存储过程体
常用特性
| 特性 | 说明 |
|---|---|
| LANGUAGE SQL | 表示存储过程语言,默认SQL |
| {CONTAINS SQL|NO SQL|READS SQL DATA |MODIFIES SQL|FILE SQL DATA } | 表示存储过程要做的工作类别 默认值:CONTAINS SQL |
| SQL SECURITY{ DEFINER|INVOKER } | 指定存储过程执行权限 默认值:DEFINER DEFINER:创建者权限 INVIKER:执行者权限 |
| COMMENT 'string' | 存储过程注释信息 |
示例:
CREATE PROCEDURE proc_patient_countPatien() BEGIN select count(*) from patient; END
声明语句分隔符
使用DELIMITER关键字将分隔符设置为“$$” 或“//”
DELIMITER //
还原为默认分隔符“;”
DELIMITER ;
注意不设置分隔符,编译器会视为不同SQL语句处理,编译过程会报错
示例:
#存储过程输出病人总数 DELIMITER // #声明分割符 CREATE PROCEDURE proc_patient_countPatien() BEGIN #过程体开始 select count(*) from patient; END // #过程体结束 DELIMITER ; #恢复默认分隔符
过程体的标识
需要标识开始、结束
BEGIN //.... END
定义存储过程参数
[IN|OUT|INOUT]
IN:输入参数
-
必须输入
-
不能返回
OUT:输出参数
-
存储过程中改变,可返回
INOUT:输入输出参数
-
调用过程时指定
-
存储过程中可被改变和返回
CREATE PROCEDURE proc_patient_countPatien2(OUT patientNum INT) BEGIN //..... END
调用存储过程
CALL 存储过程名([参数1,参数2,.....]);
示例:
CALL proc_patient_countPatien();
类似于java中方法调用
示例:
delimiter // create procedure proc_patient_countPatient2(OUT patientNum INT)#输出参数 begin select count(*) INTO patientNum from patient; end // delimiter ; #调用并输出病人信息 call proc_patient_countPatient2(@patientNum);#@patientNum用户变量 select @patientNum;
存储过程中的变量
与java类似,定义存储时可以使用变量
#声明变量 DECLARE 变量名[,变量名...] 数据类型 [DEFAULT 值]; #变量赋值 SET 变量名=表达式值[,变量名=表达式...];
定义存储过程局部变量必须放在存储过程体开始,否则报错!!!
示例:
#声明交易时间变量 trade_time,并设置默认值为2020-07-01 DECLARE trade_time date DEFAULT '2020-07-01'; SET total=100;
MYSQL变量
系统变量
指MySQL全局变量,以“@@”开头,形式为“@@变量名”
用户自定义变量
局部变量
一般用于SQL的语句块中,如:存储过程中的BEGIN和END语句块
作用域——仅限于定义该变量的语句块内
生命周期——仅限于存储过程被调用时间
释放时机——存储过程执行的END时
会话变量(也叫:用户变量)
服务器维护每个客户端连接时的变量,与MySQL客户端绑定
可以短暂存值,传递给同一连接中的其他SQL语句
释放时机——当MySQL客户端连接退出时
创建形式——一般以“@”开始,形式为“@变量名”
示例:
/* 创建存储过程,通过用户输入的科室编号和病人姓名,查询该病人在该科室最后一次的检查时间。 分析: - 输入参数:科室编号、病人姓名 - 输出参数:该病人在该科室最后一次检查时间 - 结果:根据输入参数查询获取指定预期结果 */ #定义 delimiter // create procedure proc_exam_GetLastExamDateByPatientNameAndDepID( in patient_name varchar(50), in dep_id int, out last_exam_date DATETIME) begin declare patient_id int; select patientID into patient_id from patient where patientName=patient_name; select patient_id; select max(examDate) into last_exam_date from prescription where patientId=patient_id and depId=dep_id; end// delimiter ; #调用 #设置病人名 set @patientName='夏颖'; #设置科室编号 set @dep_id=1; #调用存储过程 call proc_exam_GetLastExamDateByPatientNameAndDepID(@patientName,@dep_id,@last_exam_date); #结果 +------------+ | patient_id | +------------+ | 1 | +------------+ 1 row in set (0.00 sec) Query OK, 1 row affected (0.00 sec) #查询输出变量 select @last_exam_date; +---------------------+ | @last_exam_date | +---------------------+ | 2020-07-08 00:00:00 | +---------------------+ 1 row in set (0.00 sec)
SELECT INTO语句可以给多个变量赋值
#示例: SELECT patientId,patientName INTO patient_id,patient_name FROM patient WHERE patientID=1;
用户变量在存储过程间传递
用户变量不仅可以在存储过程内和客户端中设置,还可以在不同存储过程间传递值
示例:
#创建存储过程proc1()设置用户变量并赋值
#创建存储过程proc2()调用输出变量
mysql> delimiter //
mysql> create procedure proc1()
-> begin
-> set @name='王明';
-> end//
mysql> delimiter ;
mysql> delimiter //
mysql> create procedure proc2()
-> begin
-> select concat('name',@name);
-> end//
mysql> delimiter ;
mysql> call proc2();
+----------------------+
| concat('name',@name) |
+----------------------+
| NULL |
+----------------------+
mysql> call proc1();
mysql> call proc2();
+----------------------+
| concat('name',@name) |
+----------------------+
| name王明 |
+----------------------+
Navicat中创建、调用存储过程
Navicat提供良好的开发环境,比MySQL命令行操作简便快捷
基本步骤:
-
创建存储过程:
-
点击“函数”节点,在弹出的下拉菜单中选择“新建函数”
-
在右侧会出现自动创建存储过程模板,并在其中编写
-
注意:此环境中不需要写 delimiter 声明语句;模板自动增加definer赋值语句.
-
运行存储过程
-
点击“保存”,自动存储在数据库“函数”节点下
-
点击"运行"
-
根据要求填入参数
-
点击“确定”执行存储过程,并输出结果

















 636
636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









