




 YOLO将目标检测问题转化为回归问题,直接从图像像素映射到边界框坐标和类别概率。具备快速检测、低背景误检率及良好泛化性能的特点。YOLO采用7×7网格,每个网格预测2个边界框,共输出30维张量。
YOLO将目标检测问题转化为回归问题,直接从图像像素映射到边界框坐标和类别概率。具备快速检测、低背景误检率及良好泛化性能的特点。YOLO采用7×7网格,每个网格预测2个边界框,共输出30维张量。
You Only Look Once:Unified, Real-Time Object Detection
CVPR2016
https://pjreddie.com/darknet/yolo/
YOLO 提出的背景是 基于CNN目标检测的速度太慢了,主要目的就是提速。
We reframe object detection as a single regression problem, straight from image pixels to bounding box coordinates and class probabilities
这里是将目标检测问题变为一个简单的回归问题,YOLO直接将图像像素信息映射到 矩形框坐标和物体类别概率信息
YOLO 特定如下:
1) 速度快
2)YOLO 做出预测时是基于整幅图像推理得到的 ,所以 YOLO将背景误检为物体的概率要比 Fast R-CNN 低
YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance.
3) YOLO的泛华性能比较好
YOLO learns generalizable representations of objects
YOLO 的缺点就是 物体的位置精度较差
YOLO 框架
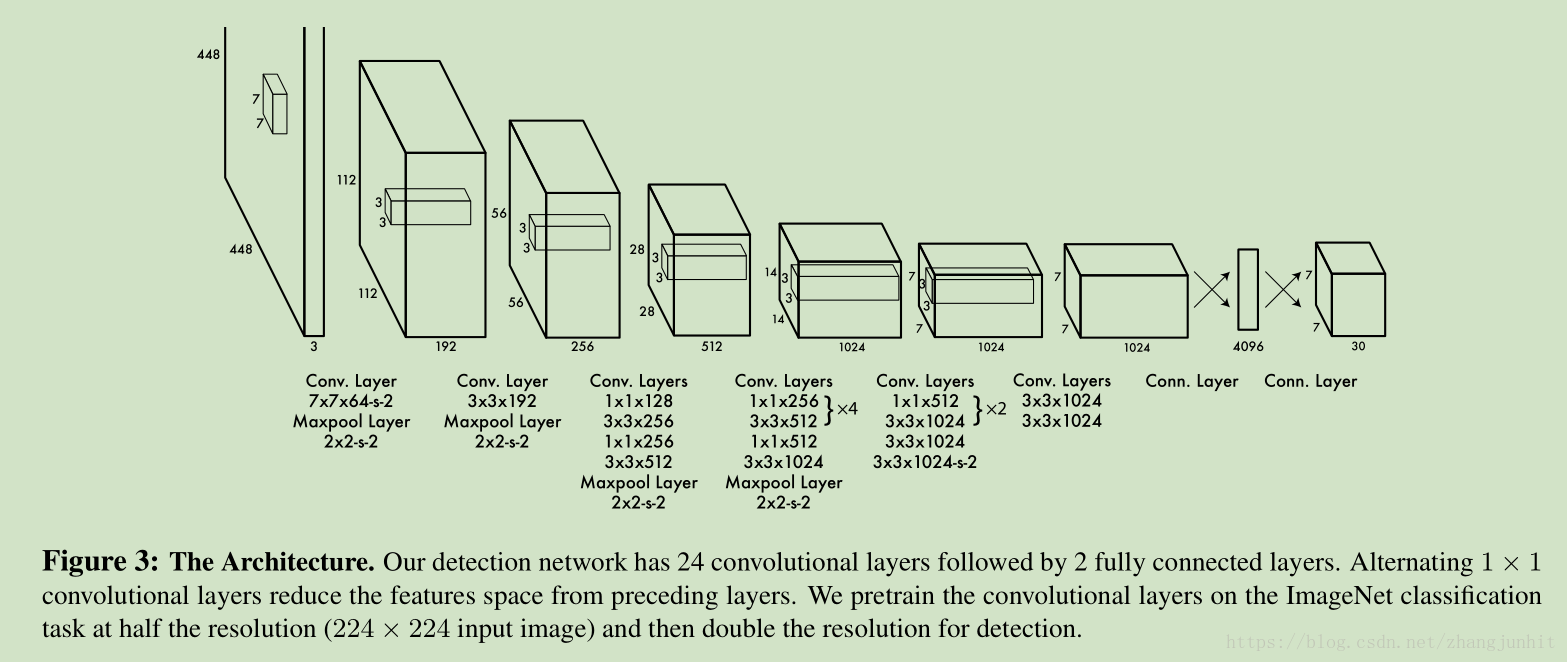
For evaluating YOLO on P ASCAL VOC, we use S = 7, B = 2. P ASCAL VOC has 20 labelled classes so C = 20.
Our final prediction is a 7 × 7 × 30 tensor.
输入图像经过一系列卷积层和两个全链接层处理得到 7 × 7 × 30 tensor
The final output of our network is the 7 × 7 × 30 tensor of predictions
如何解析这个 7 × 7 × 30 tensor
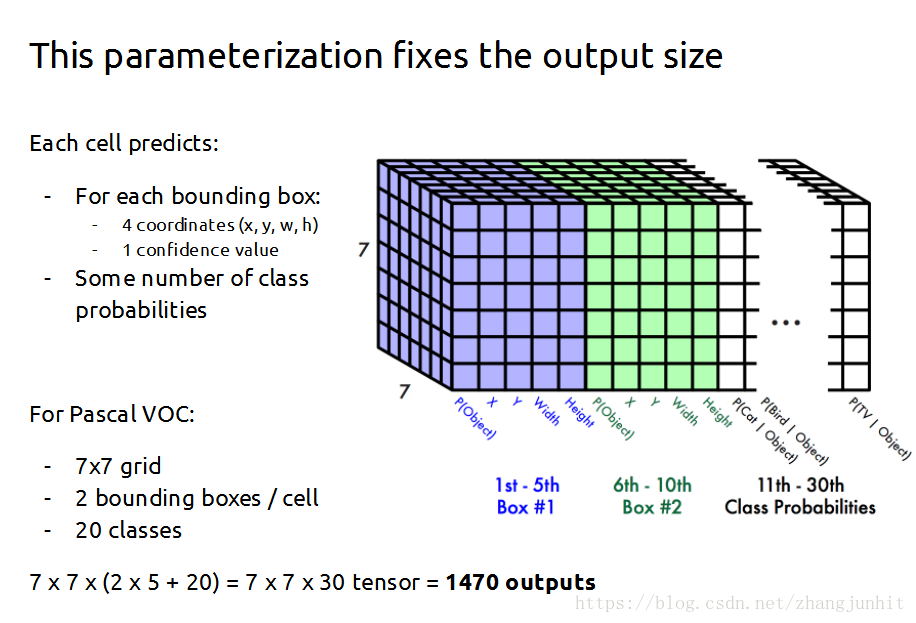
7 × 7 表示将图像分为 7 × 7 个网格,对图像进行分块处理,有点类似滑动模板目标检测。每个网格使用两个不同的模板进行检测, Each grid cell predicts B bounding boxes。 这里的模板匹配检测就是 R-CNN里面的 bounding boxes regression,对每个模板进行微调。每个 bounding boxe 对应4个坐标信息和 1个 概率信息。2个 bounding boxes 共计 10个信息。 剩下的 20个信息就是 Pascal VOC 中 20个类别概率信息 Class probability
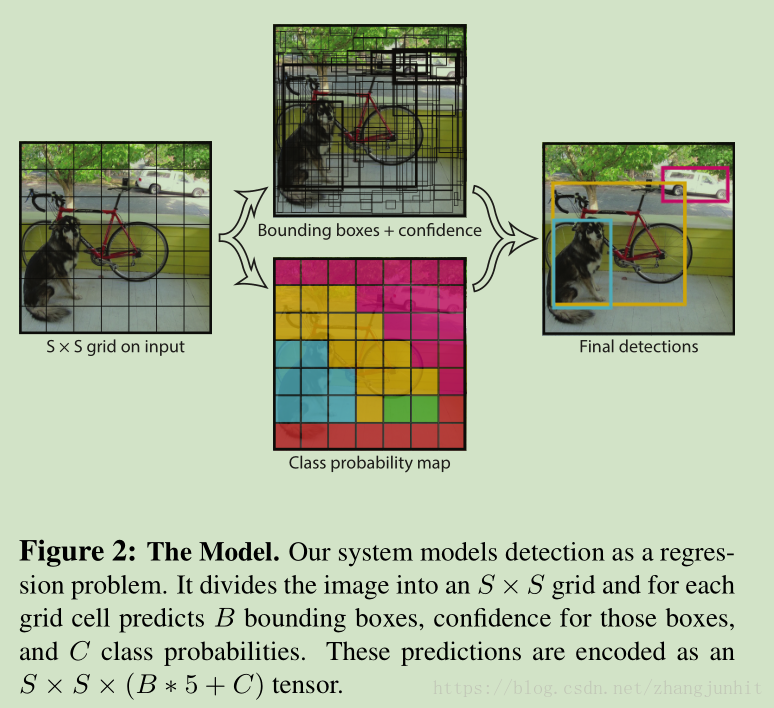
最后可以用 non-maximal suppression 对检测的结果进行过滤一下
11

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









