







 超级会员免费看
超级会员免费看
 本文探讨了在高并发系统中,分库分表后如何解决数据库ID的全局唯一性问题。文章指出,使用业务字段作为主键可能存在局限,建议使用生成的唯一ID。详细介绍了基于Snowflake算法的发号器服务,用于生成有序、全局唯一的ID,以替代UUID并避免其带来的问题。此外,还讨论了Snowflake算法的优缺点及其在实际项目中的应用和改造,强调理解原理并根据业务需求选择适合的解决方案。
本文探讨了在高并发系统中,分库分表后如何解决数据库ID的全局唯一性问题。文章指出,使用业务字段作为主键可能存在局限,建议使用生成的唯一ID。详细介绍了基于Snowflake算法的发号器服务,用于生成有序、全局唯一的ID,以替代UUID并避免其带来的问题。此外,还讨论了Snowflake算法的优缺点及其在实际项目中的应用和改造,强调理解原理并根据业务需求选择适合的解决方案。
文章目录
引言
前面我们了解了分布式存储两个核心问题:数据冗余和数据分片,以及在传统关系型数据库中是如何解决的。当我们面临高并发的查询数据请求时,可以使用主从读写分离的方式,部署多个从库分摊读压力;当存储的数据量达到瓶颈时,我们可以将数据分片存储在多个节点上,降低单个存储节点的存储压力,此时我们的架构变成了下面这个样子:
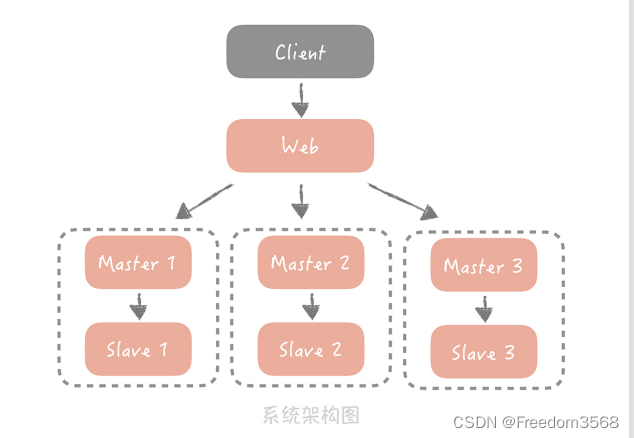
你可以看到,我们通过分库分表和主从读写分离的方式解决了数据库的扩展性问题,但数据库在分库分表之后,我们在使用数据库时存在的许多限制,比方说查询的时候必须带着分区键;一些聚合类的查询(像是 count())性能较差,需要考虑使用计数器等其它的解决方案,其实分库分表还有一个问题就是主键的全局唯一性的问题。
一、数据库主键
数据库中的每一条记录都需要有一个唯一的标识,依据数据库的第二范式,数据库中每一个表中都需要有一个唯一的主键,其他数据元素和主键一一对应。那么关于主键的选择就成为一个关键点了,一般来讲,你有两种选择方式:
-
- 使用业务字段作为主键,比如说对于用户表来说,可以使用手机号,email 或者身份证号作为主键。
-
- 使用生成的唯一 ID 作为主键。
对于

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











