




 本文概述了对抗样本的产生原理,如线性模型的脆弱性、对抗训练的正则化作用,以及多步攻击和迁移性。重点讨论了FGSM、BIM、Ensemble Adversarial Training和Cascade Adversarial Machine Learning在增强模型鲁棒性方面的贡献。关键发现包括对抗噪声的方向性、模型大小与鲁棒性关系,以及对抗训练的复杂性和适用场景。
本文概述了对抗样本的产生原理,如线性模型的脆弱性、对抗训练的正则化作用,以及多步攻击和迁移性。重点讨论了FGSM、BIM、Ensemble Adversarial Training和Cascade Adversarial Machine Learning在增强模型鲁棒性方面的贡献。关键发现包括对抗噪声的方向性、模型大小与鲁棒性关系,以及对抗训练的复杂性和适用场景。
1. Explaining And Harnessing A Dversarial Examples (ICLR2015)
神经网络对于对抗样本的攻击如此脆弱的原因,是因为网络的线性本质。文章还提出了最早的 FGSM (Fast Gradient Sigh Method)对抗样本生成方法。通过在训练样本中加入一定的对抗样本(随机生成),可以对模型起到一定的正则化作用。
Observations:


Towards Deep Learning Models Resistant to Adversarial Attacks
(1) 对抗样本可以被看作是高维点积的结果。其产生的原因是模型倾向于线性模型。
(2)通过不同模型产生的对抗样本可以被看做高维特征向量的集合。对于同一任务,多个模型会学习到相似的特征表达。
对抗样本在不同模型之间的泛化能力可以解释为对抗样本扰动与模型权重变量步调高度一致的结果,而不同的模型在执行相同的任务的时候,学习的都是相似的函数。
(3)噪声的方向比较重要,而不是空间中具体的哪个点。因为特征空间并不像实数里面到处嵌入了无理数一样,到处都存在对抗样本。https://www.zybuluo.com/wuxin1994/note/964742https://www.zybuluo.com/wuxin1994/note/964742https://www.zybuluo.com/wuxin1994/note/964742
(4)因为方向是比较重要的,所以噪声会在不同的图像上产生从而进行泛化
(5)该论文提出了一系列的产生对抗噪声的方法。
(6)对抗训练可以起到正则化的作用,其正则效果甚至优与dropout。
(7)用L1 weight decay 和添加噪声来模仿对抗训练的效果但是失败了。
(8)越容易优化的模型越容易被干扰。C ASCADE A DVERSARIAL MTowards Deep Learning Models Resistant to Adversarial Attacks ACHINE L EARNING R EG -
ULARIZED WITH A U NIFIED E MBEDDING
(9)线性模型对对抗样本没有抵抗力,除非添加了隐藏层(加了激活函数?)。
(10)RBF模型能PK对抗样本。
(11)用来产生噪声的模型对对抗样本毫无抵抗力。
(12)ensembles对抗样本能力有限。

(13)辣鸡图像无处不在并且容易生成。
(14)简单的线性模型并不能对抗辣鸡图像。Towards Deep Learning Models Resistant to Adversarial Attacks
(15)但是RBF阔以。
2. A DVERSARIAL MACHINE L EARNING AT SCALE(ICLR2017)
contributions:
(1)提出了如何将对抗训练应用到大的模型和数据集上
(2)对抗训练为一步的攻击带来了鲁棒性
(3)多步的攻击的迁移性没有单步的好
(4)标签缺失的问题会导致对抗训练在对抗样本上表现更好,与干净的样本相比.因为在对抗样本的构建过程中需要真实的样本,模型会学习探索其规律在构建过程中
基于FGSM的改进:
(1)从原先的以增加原始类别标记的损失函数为目标变为了减Towards Deep Learning Models Resistant to Adversarial Attacks少目标类别的损失函数为目标
(2)提出了BIM,但是FGSM的可转移性比BIM的可转移性强很多,这很可能是因为BIM生成的对抗样本太过针对性,因此减少了对抗攻击的泛化能力。这也许为黑箱攻击提供了一些鲁棒性。
(3)出了一个新的对抗训练方式来应对批量训练,使用一个可以独立控制每批次对抗案例的数量和相关权重的损失函数,训练的时候一些clean examples,一些adversary examples
(4)模型大小和鲁棒性的关系,作者指出对于没有对抗训练的模型,太大的模型或者太小的模型都C ASCADE A DVERSARIAL M ACHINE L EARNING R EG -
ULARIZED WITH A U NIFIED E MBEDDING会导致鲁棒性很差,而对于对抗训练的模型,由于条件限制,目前的模型越大,鲁棒性显得越好。
(5)对抗训练起到了一定的正则化的作用。在过拟合的模型上,对抗训练能够降低测试误差;而在像ImageNet这些训练误差就很高的数据集上(欠拟合),对抗训练反而增大了训练误差,扩大了训练误差和测试误差的差距。Towards Deep Learning Models Resistant to Adversarial Attacks
参考博客:https://blog.youkuaiyun.com/kearney1995/article/details/79789899
实验部分:单步攻击具有适用性,用一个单步攻击的方法对其他单步攻击的方法也使用(做实验的时候,训练集和测试集是一样的);单步攻击训练,在迭代攻击上测试效果不好;多步攻击训练,单步攻击测试,没做实验,因为没有意义。
3. ENSEMBLE ADVERSARIAL TRAINING : ATTACKS AND DEFENSES
the source: compute perturbations on one model
the target: transfer them to all others
参考博客:https://www.cnblogs.com/gris3/p/12688506.html
4. CASCADE A DVERSARIAL MACTowards Deep Learning Models Resistant to Adversarial AttacksHINE LEARNING REGULARIZED WITH A UNIFIED E MBEDDING(ICLR2018) Github
cascade adversarial training: transfers the knowledge of the end results of adversarial training 增加了关于抗训练最后结果的知识
在对抗样本的迁移过程中,训练方式相同的方法更好迁移
trains a network by injecting iter FGSM images craftedv from an already defended network

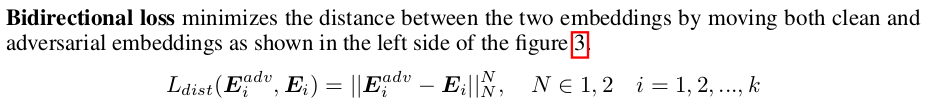
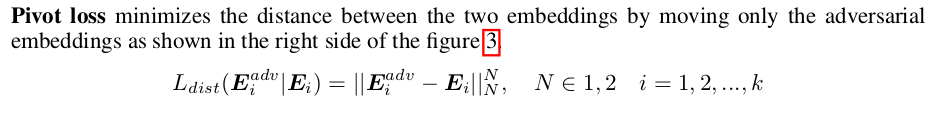
bidirectional loss 两类样本都移动;pivot loss 是只移动对抗样本
这个距离损失主要是要求两个图片的输出尽可能相同,而不是要求其为正确的label,并且这个正则化添加的地方离softmax越远,网络学习到的内容就越多,效果就越好, low-level similarity learning
黑盒攻击的时候:
- We re-train 110-layer ResNet models using Kurakin’s, cascade and ensemble adversarial training with/without low-level similarity learning and use those networks as source networks for black-box attacks.
- Target networks are the same networks(ResNet) used in table 3.
5. Towards Deep Learning Models Resistant to Adversarial Attacks
https://zhuanlan.zhihu.com/p/45684812
参考文献:
- https://blog.youkuaiyun.com/cdpac/article/details/53170940https://www.zybuluo.com/wuxin1994/note/964742
- https://www.zybuluo.com/wuxin1994/note/964742


















 2245
2245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









