






文章目录
前言
手写RPC项目的学习笔记:
1、protobuf 使用
参考学习:https://subingwen.cn/cpp/protobuf/
1.1 在Linux上编译和安装protobuf
1.1.1 安装
安装包下载地址
选择v21.12版本安装(其他安装版本很曲折,不推荐)
随后进入Linux环境执行命令
# 以protobuf 3.21.12为例
# 自行下载源码包,解压缩
$ tar zxvf protobuf-cpp-3.21.12.tar.gz
#进入到解压目录
$ cd protobuf-cpp-3.21.12/
# 构造并安装
$ ./config # 检查安装环境 生成makefile
$ make # 编译
$ sudo make install # 安装 如果是root不用加sudo
1.1.2 测试
$ protoc --version
protoc: error while loading shared libraries: libprotoc.so.32: cannot open shared object file: No such file or directory
通过输出的信息可以看到找不到动态库,此时可以通过find进行搜索
$ sudo find /usr/local/ -name libprotoc.so.32
/usr/local/lib/libprotoc.so.32
此时,动态库的路径就找到了 ,如果使用find进行搜索的时候,如果从/usr/local/ 目录搜索不到,可以从根目录搜索
随后打开系统配置文件
$ sudo vim /etc/ld.so.conf
将路径放入路径

随后输入 :wq 然后按 Enter
随后执行
$ sudo ldconfig # 更新配置
再次执行protoc --version

成功!!
1.2 Protobuf 语法
编写.proto文件
// Person.proto
syntax = "proto3"; //版本号
// 在该文件中对要序列化的结构体进行描述 消息体
message Person
{
int32 id = 1;
bytes name = 2;
bytes sex = 3;
int32 age = 4;
}
使用protoc工具将其转换为C++文件
$ protoc -I path .proto文件 --cpp_out=输出路径(存储生成的c++文件)
例如:在当前目录生成文件
protoc ./Person.proto --cpp_out=./

新建文件进行序列化和反序列化
#include"Person.pb.h"
#include<iostream>
using namespace std;
void main(){
//序列化
Person p;
p.set_id(10);
p.set_age(10);
p.set_sex("man");
p.set_name("lucy");
//序列化对象
string output;
p.SerializeToString(&output);
//反序列化
Person pp;
pp.ParseFromString(output);
cout<<pp.id()<<" "<<pp.sex()<<" "<< pp.age()<<endl;
}
2、Zookeeper 学习
入门参考学习:
https://www.cnblogs.com/xinyonghu/p/11031729.html
https://juejin.cn/post/7270393728926367785
https://www.runoob.com/w3cnote/zookeeper-tutorial.html
2.1 什么是Zookeeper
- ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是大数据生态中的重要组件。它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
- 它是一个为分布式应用提供一致性协调服务的中间件。
2.2 ZooKeeper提供了什么
- 文件系统:Zookeeper提供一个多层级的节点命名空间(节点称为znode)。与文件系统不同的是,这些节点都可以设置关联的数据,而文件系统中只有文件节点可以存放数据而目录节点不行。Zookeeper为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得Zookeeper不能用于存放大量的数据,每个节点的存放数据上限为1M。
- 监听通知机制:client端会对某个znode建立一个watcher事件,当该znode发生变化时,这些client会收到zk的通知,然后client可以根据znode变化来做出业务上的改变等。
2.3 Zookeeper数据类型:
zookeeper 中的所有存储的数据是由 znode 组成的,节点也称为 znode,并以 key/value 形式存储数据。整体结构类似于 linux 文件系统的模式以树形结构存储。其中根路径以 / 开头。Zookeeper会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统,如图所示:
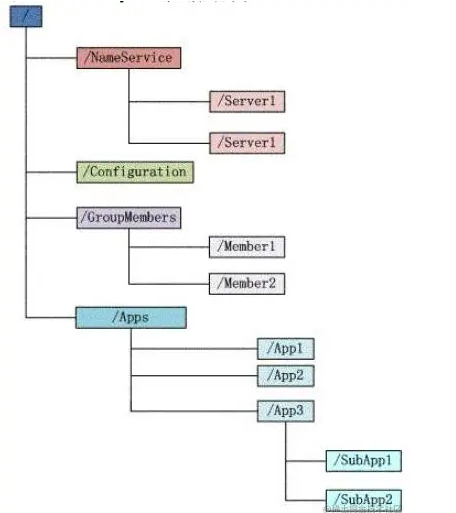
Zookeeper这种数据结构有如下这些特点:
- 每个子目录项如NameService都被称作为znode,这个znode是被它所在的路径唯一标识,如Server1这个znode的标识为/NameService/Server1。
- znode可以有子节点目录,并且每个znode可以存储数据,注意EPHEMERAL(临时的)类型的目录节点不能有子节点目录。
- znode是有版本的(version),每个znode中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据,version号自动增加。
- znode的类型:
Persistent 节点,一旦被创建,便不会意外丢失,即使服务器全部重启也依然存在。每个 Persist 节点即可包含数据,也可包含子节点。
Ephemeral 节点,在创建它的客户端与服务器间的 Session 结束时自动被删除。服务器重启会导致 Session 结束,因此 Ephemeral 类型的 znode 此时也会自动删除。
Non-sequence 节点,多个客户端同时创建同一 Non-sequence 节点时,只有一个可创建成功,其它匀失败。并且创建出的节点名称与创建时指定的节点名完全一样。
Sequence 节点,创建出的节点名在指定的名称之后带有10位10进制数的序号。多个客户端创建同一名称的节点时,都能创建成功,只是序号不同。 - znode可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是Zookeeper的核心特性,Zookeeper的很多功能都是基于这个特性实现的。
- ZXID:每次对Zookeeper的状态的改变都会产生一个zxid(ZooKeeper Transaction Id),zxid是全局有序的,如果zxid1小于zxid2,则zxid1在zxid2之前发生。
2.4 Zookeeper session基本原理
客户端与服务端之间的连接是基于 TCP 长连接,client 端连接 server 端默认的 2181 端口,也就是 session 会话。从第一次连接建立开始,客户端开始会话的生命周期,客户端向服务端的ping包请求,每个会话都可以设置一个超时时间。
Session 的状态
下面介绍几个重要的状态:
- connecting:连接中,session 一旦建立,状态就是 connecting 状态,时间很短。
- connected:已连接,连接成功之后的状态。
- closed:已关闭,发生在 session 过期,一般由于网络故障客户端重连失败,服务器宕机或者客户端主动断开。
2.5 Zookeeper权限控制ACL:
参考:https://www.runoob.com/w3cnote/zookeeper-acl.html
3、消息队列
消息队列MQ:保存消息的一个容器,本质是个队列。但这个队列需要支持高吞吐,高并发,并且高可用。
常用消息队列:
Kafka:分布式的、分区的、多副本的日志提交服务,在高吞吐场景下发挥较为出色
RocketMQ:低延迟、强一致、高性能、高可靠、万亿级容量和灵活的可扩展性,在一些实时场景中运用较广
Pulsar:是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体、采用存算分离的架构设计
BMQ:和Pulsar架构类似,存算分离,初期定位是承接高吞吐的离线业务场景,逐步替换掉对应的Kafka集群

















 1435
1435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









