






简述以下内容:
编译tesseract ocr的静态lib库,给c++编程中开发使用,可搭配opencv或leptonica库进行图片识别。都是当下最新的版本
文中所用到的网址如下
1.SW下载地址:https://software-network.org/client/
2.tesseract ocr下载地址:https://github.com/tesseract-ocr/tesseract
3.tesseract ocr依赖的lib库下载地址:https://github.com/peirick/Tesseract-OCR_for_Windows
4.leptonica下载地址:https://github.com/DanBloomberg/leptonica
5.tesseract ocr文字识别库下载地址:https://github.com/tesseract-ocr/tessdata
编译后的文件资源,也都已经上传
实操步骤
1.下载配置SW
下载最新的sw-master-windows_x86_64-client.zip解压到任意目录,把SW.exe所在路径设置为环境变量。
在CMD中执行sw setup,这一步是为了在编译tesseract ocr时自动找到SW_DIR的路径。
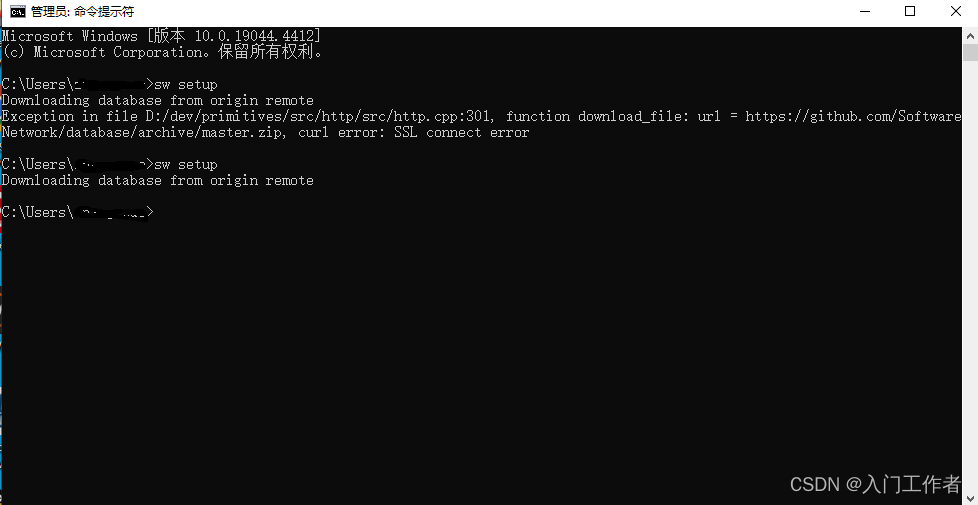
上图我是更换了一个网络才不会报错的,可能公司网有限制。
2.编译tesseract ocr
下载最新的tesseract,在目录中新建build目录,打开cmake-gui。
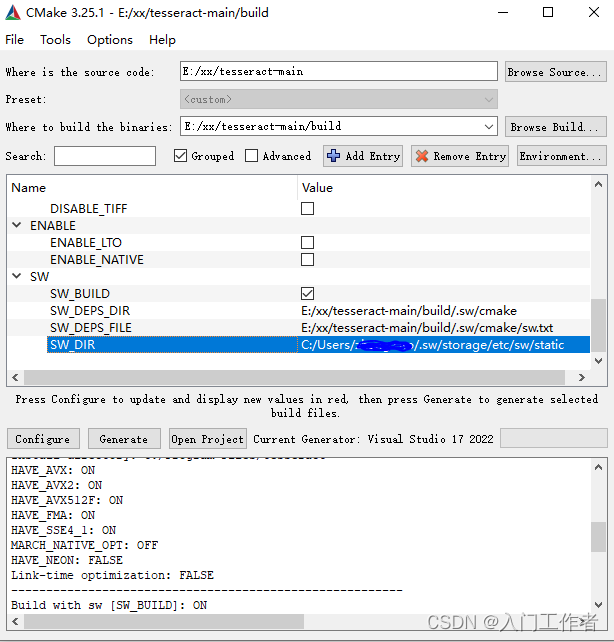
当然你需要选择你所用的VS版本和编译平台,如下图,他会自动找到SW所在路径,依次点击configure和generate,sw会下载很多依赖库到C:\Users\用户名.sw里面。
打开build下面的tesseract.sln,点击ALL_BUILD,右键生成
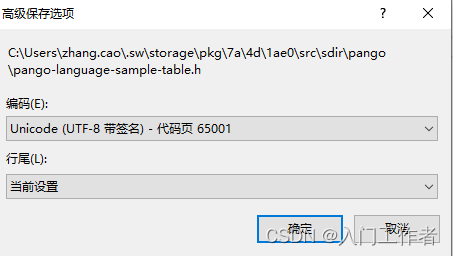
此时会出现多个(20个左右)文件报警如下,每次生成就会爆出一个,依次将该文件的编码类型改为utf-8 带签名(VS中具有这个功能),再次生成

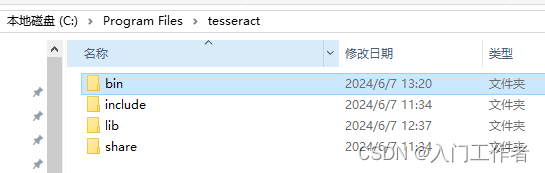
在debug和release模式下分别点击install后,在C:/program Files下会生成tesseract.exe和tesseract54d.lib、tesseract54.lib等文件
3.编译Tesseract-ocr_for_windows-master
目的是生成giflib.lib、libjpeg.lib、liblept.lib、libpng.lib、libtiff.lib、libwebp.lib、openjpeg.lib、zlib.lib
第一步是要先下载leptonica的源码放在Tesseract-ocr_for_windows-master的解压目录内的leptonica中,如下图
第二步,打开tesseract.sln后,我直接选择不生成jbig2enc、libtesseract、tesseract这三项(别问,问就是生成的有问题),我只要生成上一节tesseract静态库依赖的静态库
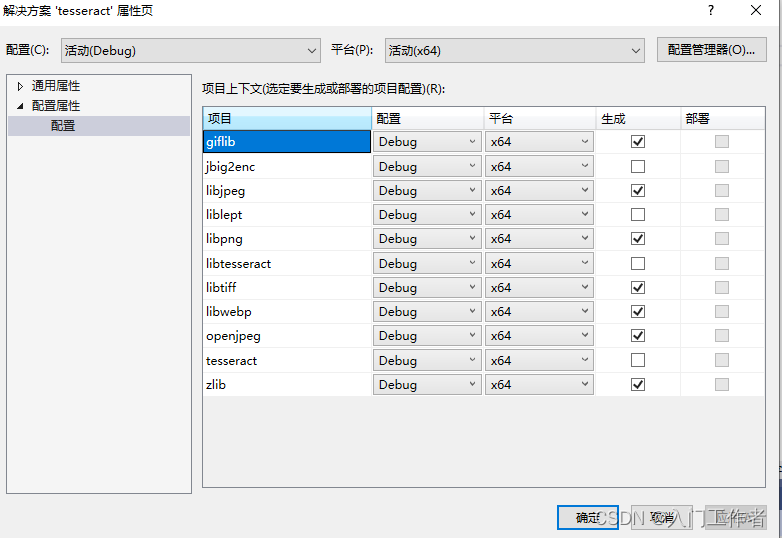
现在就会生成如下8个lib库,可生成debug和release版本
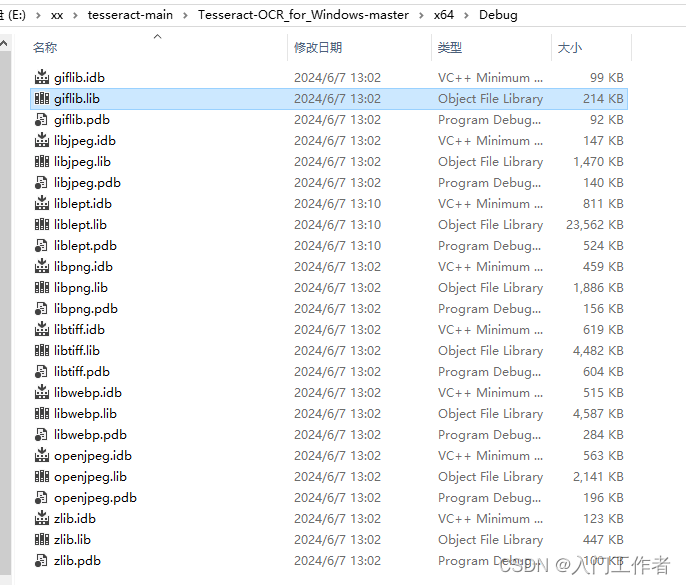
4.下载文字识别库,放在tessdata目录下,例如在你的c++项目exe目录中

5.使用opencv打开图片传入ocr识别,测试代码如下
#include<tesseract/baseapi.h>
//#include <leptonica/allheaders.h> //可以用opencv读取图像,代替
//#include <leptonica/pix_internal.h>
#include<opencv2/opencv.hpp>
using namespace tesseract;
int main()
{
char* outText;
tesseract::TessBaseAPI* api = new tesseract::TessBaseAPI();
/*
Initialize OCR engine to use English (eng) and The LSTM
OCR engine.
There are four OCR Engine Mode (oem) available
OEM_TESSERACT_ONLY Legacy engine only.
OEM_LSTM_ONLY Neural nets LSTM engine only.
OEM_TESSERACT_LSTM_COMBINED Legacy + LSTM engines.
OEM_DEFAULT Default, based on what is available.
*/
// Initialize tesseract-ocr with English, without specifying tessdata path
if (api->Init(NULL, "tessdata/eng", OEM_LSTM_ONLY))
{
fprintf(stderr, "Could not initialize tesseract.\n");
exit(1);
}
Open input image with leptonica library
//Pix* image = pixRead("9.bmp"); //可以用opencv读取图像,代替
//api->SetImage(image);
//Set Page segmentation mode to PSM_AUTO (3)
// Other important psm modes will be discussed in a future post.
// 设置分割模式
api->SetPageSegMode(tesseract::PSM_AUTO);
// Open input image using OpenCV
cv::Mat im = cv::imread("9.bmp", 0);
// Set image data
api->SetImage(im.data, im.cols, im.rows, 1, im.step);
//std::cout << im.step;
// Get OCR result
outText = api->GetUTF8Text();
printf("---- OCR output:---- \n%s", outText);
// Destroy used object and release memory
api->End();
delete[] outText;
//pixDestroy(&image);
return 0;
}
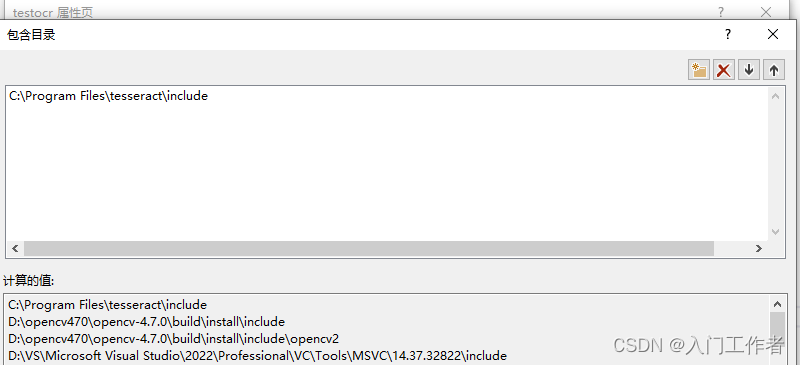
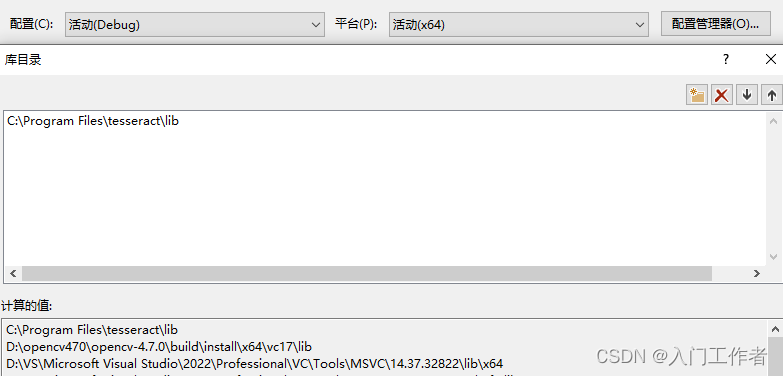
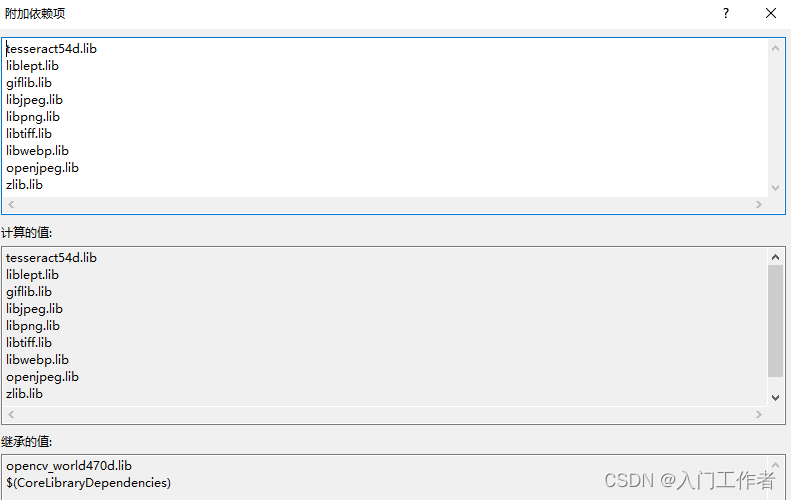
vs工程中需要包含头文件和库目录,库名称。这样生成的exe可以直接给别人电脑使用。
题外话
如果你不用opencv,那就用leptonica的库进行开发,之前下载有leptonica的源码,进行cmake和vs编译就会有lib静态库生成,则可读取图片进行识别。
参考资料
1.https://blog.youkuaiyun.com/Jay_Xio/article/details/116296767
2.https://mp.weixin.qq.com/s/f1LPa4CKZ7D22dzSvMlvOQ
疑问
如何生成dll动态库呀,有大佬指导吗?

















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









