



 本文介绍如何使用Hive进行按区间条件的数据分组统计,包括按重量区间和时间间隔进行分组的方法,并提供具体实例。
本文介绍如何使用Hive进行按区间条件的数据分组统计,包括按重量区间和时间间隔进行分组的方法,并提供具体实例。
Hive 按区间条件 分组统计
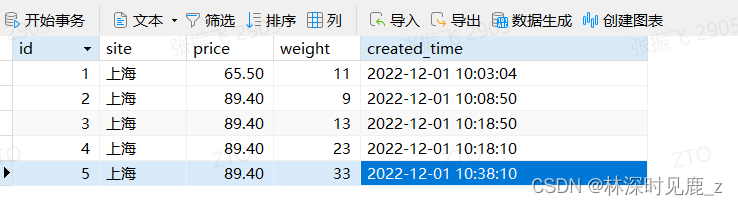
数据准备
-- 建表
CREATE TABLE `site_trans` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`site` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`price` decimal(10, 2) NULL DEFAULT NULL,
`weight` double NOT NULL DEFAULT 0,
`created_time` datetime NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
);
-- 数据插入
INSERT INTO `site_trans` VALUES (1, '上海', 65.50, 11, '2022-12-01 10:03:04');
INSERT INTO `site_trans` VALUES (2, '上海', 89.40, 9, '2022-12-01 10:08:50');
INSERT INTO `site_trans` VALUES (3, '上海', 89.40, 13, '2022-12-01 10:18:50');
INSERT INTO `site_trans` VALUES (4, '上海', 89.40, 23, '2022-12-01 10:18:10');
INSERT INTO `site_trans` VALUES (5, '上海', 89.40, 33, '2022-12-01 10:38:10');
按 区间条件 分组统计
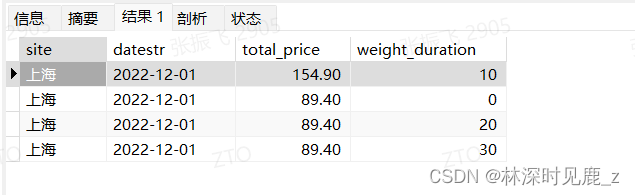
按重量段 分区统计:
-- 按重量区间统计:
SELECT
site,
substring(created_time,1,10) datestr,
sum(price) as total_price,
floor( weight / 10 ) * 10 AS weight_duration
FROM
`site_trans`
GROUP BY
site,
substring(created_time,1,10),
floor( weight / 10 ) * 10;
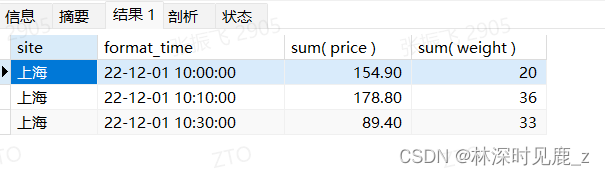
按时间段 分区统计:
-- 按间隔n分钟统计:10分钟 (2022-12-05 00:00:03数据问题未处理,拼接时间字符串时可处理)
SELECT
site,
format_time,
sum( price ),
sum( weight )
FROM
(
SELECT
site,
price,
weight,
date_format( concat( DATE ( created_time ), ' ', HOUR ( created_time ), ':', floor( MINUTE ( created_time )/ 10 )* 10 ), '%y-%m-%d %h:%i:%s' ) AS format_time
FROM
`site_trans`
) res
GROUP BY
site,
format_time
ORDER BY
format_time;

















 7708
7708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









