




 本文深入解析Transformer模型,涵盖Attention机制、Multi-headAttention、残差网络、PositionalEncoding等关键组件,探讨其在自然语言处理领域的革新作用。
本文深入解析Transformer模型,涵盖Attention机制、Multi-headAttention、残差网络、PositionalEncoding等关键组件,探讨其在自然语言处理领域的革新作用。
Attention 机制 – Transformer
推荐先看
此外,代码十分推荐看 Bert-pytorch 里面的实现,代码比上述的要更加清晰,可以看完上述代码与 bert 之后再看。
1. Scaled Dot-product Attention
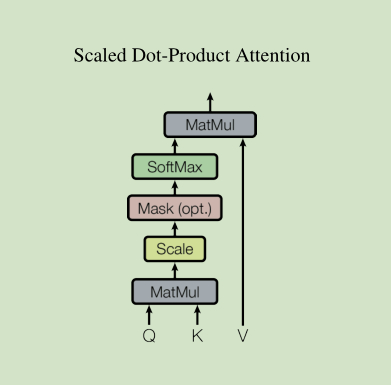
- 首先, Q 与 K 进行了一个点积操作,这个就是我在 Attention 讲到的score操作;
- 然后经过 Scale 操作,其实就是为了防止结果过大,除以一个尺度标度 d k \sqrt{d_k} dk, 其中 d k d_k dk 是 Q 中一个向量的维度;
- 再然后, 经过一个Mask操作; 考虑到Q,K都是矩阵,且由于句子的长度是不定的,因此Q,K中必然会有一个补齐的操作,为了避免补齐的数据会影响我们Attention的计算,因此需要将补齐的数据设置为负无穷,这样经过后面的Softmax后就接近于 0,这样就不会对结果产生影响了。
- 最后经过一个 Softmax 层, 然后计算Attention Value。
我们可以看到,这个依旧沿袭的是 Attention 的经典思想,不过在其中添加了一些操作如Scale, Mask,这意味着,对于Attention 而言, 其只要核心思想不变,适当的调整数据能够获得更好的结果。其公式如下:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
这里解释一下 Scaled Dot-product Attention 在本文中的应用,也是称为 Self-Attenion 的原因所在,这里的Q,K, V 都是同源的,意思就是说,这里是句子对句子自己进行Attention来查找句子中词之间的关系,这是一件很厉害的事情,回想LSTM是怎么做的,再比较 Self-Attention, 直观的感觉,Self-Attention更能把握住词与词的语义特征,而LSTM对长依赖的句子,往往毫无办法,表征极差,这一点会单独讨论。
2. Muti-head Attention
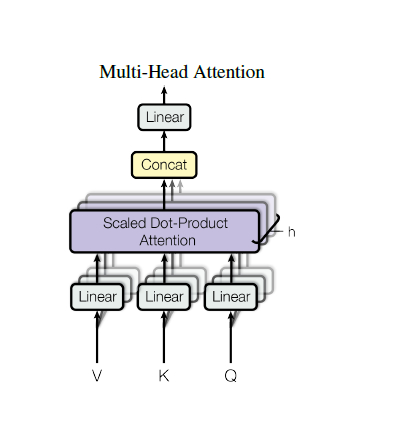
这里多头的含义其实就是采用多个Attention来从多个维度来把握词的信息,我们从图中看到,这里有 h=8 个Attention,每个Attention输出一种 Self-Attention 的结果,然后 Concat 起来。
- 首先,Q,K, V 进过了一个线性变换,然后再传入到 Scaled Dot-Product Attention 中, 注意一点,对于不同的 Scaled Dot-Product Attention 而言, 变换矩阵是不一样的,且这些变换矩阵都参与训练。
- 然后,将每个 Attention 的输出 Concat。
- 最后,进过一个线性变换输出,这个线性变化矩阵也是可训练的。
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , ⋯ , h e a d n ) W O head_i = Attention( QW_i^Q, KW_i^K, VW_i^V) \\ MultiHead(Q,K,V) = Concat(head_1, \cdots, head_n)W^O headi=Attention(QWiQ,KWiK,VWiV)MultiHead(Q,K,V)=Concat(head1,⋯,headn)WO
3. 残差网络,Normalization与feed-forward network
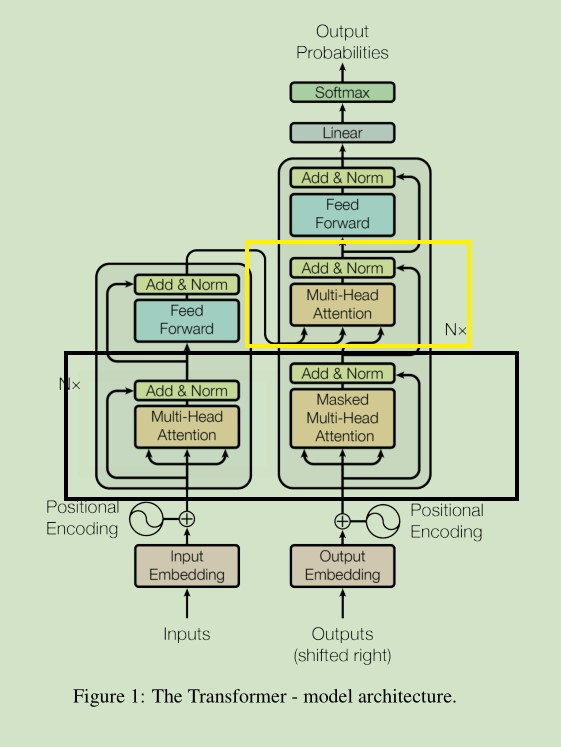
- 首先,Encoder 与Decoder中都有着很明显的残差连接,这种残差结构能够很好的消除层数加深所带来的信息损失问题。这也是一篇很值得看的文章。
- 其次,有一个Layer Normalization过程,这在神经网络中其实也是很常见的手段,也是很经典的一篇文章。
- 然后,数据经过了一个前馈神经网络, 该前馈神经网络采用了两个线性变换,激活函数为Relu,公式如下:
F F N ( x ) = R e l u ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = Relu(0, xW_1 + b_1) W_2 + b_2 FFN(x)=Relu(0,xW1+b1)W2+b2
4. Transformer 中如何使用 Multi-head Attention
Transformer 中使用 Multi-head Attention要注意以下几点:
- 在 Encoder 与 Decoder 中的黑色框中,采用的都是是 Self-Attention ,Q,K,V 同源。
- 需要注意的是只有在 Decoder 中的 Muti-head 中才有 Mask 操作,而在Encoder中却没有,这是因为我们在预测第 t个词时,需要将 t 时刻及以后的词遮住,只对前面的词进行 self-attention,这点不理解的话可以回想一下Sequence-to-Sequence那篇文章中对机器翻译的训练过程 。
- 在黄色框中, Q 来自Decoder层, 而 K, V来自Encoder的输出 。
5. Positional encoding
由于 Self-Attention 自己是把握不到句子的顺序信息的,因此,Transformer 需要采用 Positional encoding 来获取序列的顺序信息,论文中采用了正余弦函数的方式。
本质上的核心思想是: 在偶数位置,使用正弦编码,在奇数位置,使用余弦编码
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE(pos, 2i) = sin(pos / 10000^{2i/d_{model}}) \\ PE(pos, 2i+1) = cos(pos / 10000^{2i/d_{model}})
PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)
通过上式,我们可以得出:
s
i
n
(
α
+
β
)
=
s
i
n
α
c
o
s
β
+
c
o
s
α
s
i
n
β
c
o
s
(
α
+
β
)
=
c
o
s
α
c
o
s
β
−
s
i
n
α
s
i
n
β
P
E
(
p
o
s
+
k
)
=
P
E
(
p
o
s
)
+
P
E
(
k
)
sin(\alpha + \beta) = sin \alpha cos \beta + cos \alpha sin \beta \\ cos(\alpha + \beta) = cos \alpha cos \beta - sin \alpha sin \beta \\ PE(pos + k) = PE(pos) + PE(k)
sin(α+β)=sinαcosβ+cosαsinβcos(α+β)=cosαcosβ−sinαsinβPE(pos+k)=PE(pos)+PE(k)
6. 最后的 Linear 与 Softmax
这个其实没什么好说的,一般都会在最后一层加一个前馈神经网络来增加泛化能力,最后用一个 softmax 来进行预测。
回归到整体
前面已经将所有的细节都讲的很清楚了,这里回到整体的情况下来简要谈一下论文中的Encoder与Decoder。
- Encoder 是由一个Stack组成, Stack中有6个相同的Layer, 每个Layer的结构如3图中所示
- Decoder 同样由一个Stack组成, Stack中也有6个相同的Layer, 与 Encoder中的Layer有所差别, 主要是多了一个将Encoder输出引入的Muti-Head机制,这点在3图中也能很明白的看出来。
QA
1. Mask 三连问
mask 操作是什么?
mask 操作是对某些值进行掩盖,使得其再参数更新时不产生效果。
它是怎么做的?
通过将需要被mask的位置设置为负无穷,这样在后面的Softmax后,这些位置的概率就接近于 0,这样就不会对结果产生影响了。
为什么要 mask ?
Transformer 本身的 mask 操作分为两部分: padding mask 与 sequence mask。
-
Padding mask: 考虑到每个批次中输入序列的长度是不一样的,而往往我们要先进行对其,对不足长度的文本进行 padding, 而这些padding 的词其实是没有意义的, 因此我们在做 Self-attention 的时候应该忽略它。
-
Sequence Mask: 在Decoder 中,其不应该看见未来的信息,即对一个序列,当
time_step=t时, 我们Decoder 的输出应该只依赖于 t 时刻之前的输入,而不应该依赖于 t 时刻之后的输入。具体的做法是,产生一个上三角矩阵,上三角的值全为 1,下三角的值权威0,对角线也是 0。
2. Scaled Dot-product Attention 中的Scaled 是啥,有啥用?
Scaled 就是缩放数据。
- 比较大的输入会使得 softmax 的梯度变得很小,当数量级较大时, softmax 将几乎全部的概率分布都分配给了最大值对应的标签, 此时梯度消失为 0, 参数更新会变得困难。
- 假设 Q, K 的各个分量是相互独立的随机变量,均值为 0, 方差为1,那么点积 Q ⋅ K Q \cdot K Q⋅K 的均值为 0, 方差为 d k d_k dk 。 方差越大,说明点积的数量级越大,通过除以 d k \sqrt{d_k} dk 将方差稳定到 1, 可以有效的控制前面提到的梯度消失问题。
3. 为什么 Position embddding 采用正余弦函数 ?
因为有:
P
E
(
p
o
s
+
k
)
=
P
E
(
p
o
s
)
+
P
E
(
k
)
PE(pos + k) = PE(pos) + PE(k)
PE(pos+k)=PE(pos)+PE(k)
这样使得模型能够记住相对位置信息。

















 1948
1948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









