



 XGBoost,即Extreme Gradient Boosting,是一种高效的机器学习算法,基于梯度提升树框架。本教程详细介绍了XGBoost的工作原理,包括模型公式、监督学习元素、目标函数、决策树集成、训练过程以及模型复杂度的定义。XGBoost通过优化目标函数,采用正则化项防止过拟合,支持自定义损失函数,能够处理回归、分类和排序等问题。
XGBoost,即Extreme Gradient Boosting,是一种高效的机器学习算法,基于梯度提升树框架。本教程详细介绍了XGBoost的工作原理,包括模型公式、监督学习元素、目标函数、决策树集成、训练过程以及模型复杂度的定义。XGBoost通过优化目标函数,采用正则化项防止过拟合,支持自定义损失函数,能够处理回归、分类和排序等问题。
XGBoost代表“Extreme Gradient Boosting”,其中“梯度增强”一词源于弗里德曼的论文《Greedy Function Approximation: A Gradient Boosting Machine》。这是一个关于梯度增强树的教程,大部分内容都是基于这些幻灯片,作者是XGBoost的原作者陈天琦。
梯度提升树已经被提出有一段时间了,有很多关于这个主题的材料。本教程将使用监督学习的元素,以一种自包含和有原则的方式解释提升树。我们认为这种解释更简洁、更正式,并推动了XGBoost中使用的模型公式
Elements of Supervised Learning
XGBoost用于监督学习问题,我们使用训练数据(具有多个特征)来预测目标变量
。在学习树之前,让我们先回顾一下监督学习中的基本元素。
Model and Parameters
有监督学习模型通常指的是用输入来预测
的数学结构。一个常见的例子是一个线性模型, 给定预测值
,其是输入特征的线性加权组合。根据任务的不同,预测值可以有不同的解释,如回归或分类。例如,它可以通过逻辑变换得到正类在逻辑回归中的概率,也可以作为我们对输出进行排序时的一个排序分数。
参数是我们需要从数据中学习的待定部分。在线性回归问题,参数是系数。通常我们会使用
表示参数(有许多参数在一个模型中,这里我们的定义是草率的)。
Objective Function: Training Loss + Regularization
通过对的合理选择,我们可以表达各种不同的任务,如回归、分类、排序等。训练模型的任务,旨在根据训练数据
和标签数据
站到最佳的参数
。为了训练模型,我们需要定义目标函数来度量模型与训练数据的匹配程度。
目标函数的一个显著特征是由训练损失和正则化项两部分组成:
其中是损失函数,
是正则化项。训练损失衡量的是我们的模型对训练数据的预测能力。一个常见的选择是均方误差,定义为:
另一个常用的损失函数是logistic损失,用于logistic回归:
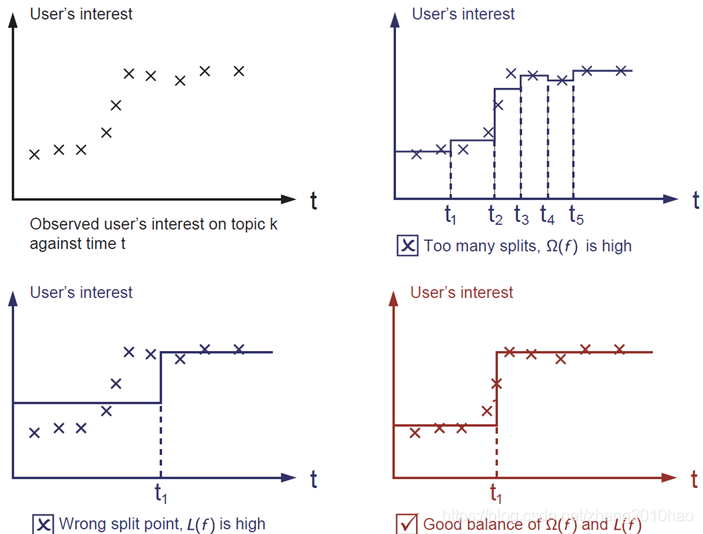
正则化项是人们经常忘记添加的,它控制了模型的复杂度,避免了过度拟合。这听起来有点抽象,所以让我们考虑下图中的问题。给定图像左上角的输入数据点,要求您在视觉上拟合一个阶跃函数。你认为三个方案中哪一个最合适?
Why introduce the general principle?
上面介绍的元素构成了监督学习的基本元素,它们是机器学习工具包的天然构件。例如,你应该能够描述梯度提升树和随机森林之间的差异和共性。以一种形式化的方式理解这个过程也有助于我们理解我们正在学习的目标,以及诸如剪枝和平滑等启发法背后的原因。
Decision Tree Ensembles
既然我们已经介绍了监督学习的要素,让我们从真正的树开始。首先,让我们首先了解XGBoost的模型选择:决策树集成。树集成模型由一组分类回归树(CART)组成。这里有一个简单的CART示例,它可以分类用户是否喜欢虚拟的电脑游戏X。
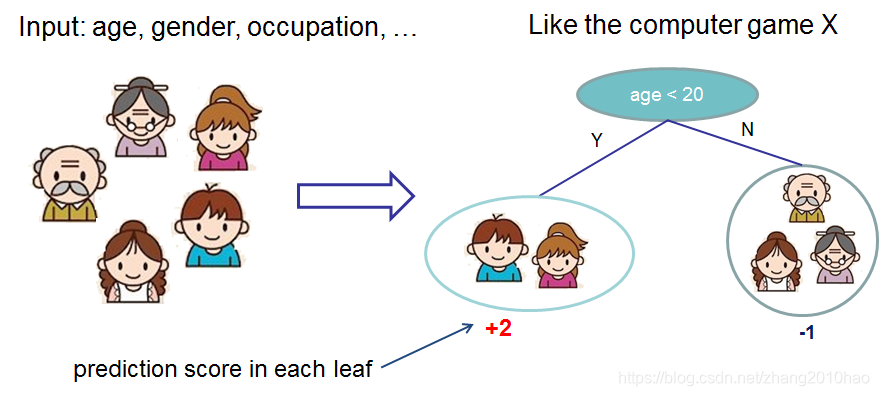
我们把一个家庭的成员分到不同的叶子节点,并在相应的叶子上给他们打分。CART与决策树稍有不同,在决策树中,叶子只包含决策值。在CART中,每个叶节点都有一个真实的分数,这给了我们比分类更丰富的解释。这还允许使用一种有原则的、统一的优化方法,我们将在本教程的后面部分看到这一点。
通常情况下,一棵单独的树不够强壮,不能用于实践。实际使用的是集成模型,它将多个树的预测汇总在一起。
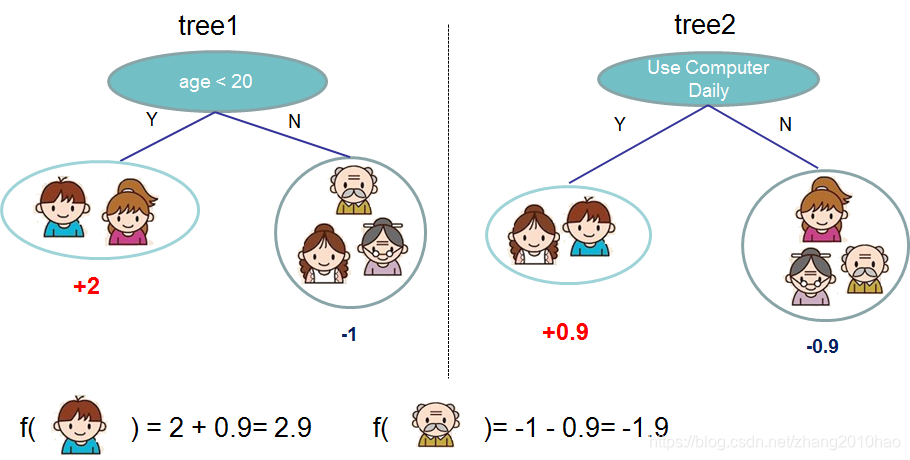
这是一个由两棵树组成的树的例子。将每棵树的预测得分相加,得到最终得分。如果你看看这个例子,一个重要的事实是这两棵树试图互补。数学上,我们可以把模型写成这种形式:
其中为树的数量,
为函数空间
中的一个函数,
为所有可能的CARTs的集合。优化的目标函数为:
现在有一个棘手的问题:随机森林中使用的模型是什么?树集成!所以随机森林和提升树是完全相同的模型;区别在于我们如何训练他们。这意味着,如果您为树集成编写一个预测服务,您只需要编写一个,它应该适用于随机森林和梯度提升树。
Tree Boosting
既然我们已经介绍了模型,现在让我们转向训练:我们应该如何学习树?答案是,就像所有监督学习模型一样,定义一个目标函数并优化它!
让下式为目标函数(请记住,它总是需要包含训练损失和正则化)::
Additive Training
我们要问的第一个问题是:树的参数是什么?你会发现我们需要学习的是那些函数,每个函数都包含树的结构和叶子分数。学习树结构比传统的优化问题要困难得多,在传统优化问题中,你可以简单地取梯度。一次学完所有的树是很难的。相反,我们使用一种附加策略:修复我们所学的内容,并一次添加一个新树。我们把第
步的预测值写成
。然后我们有
......
剩下的问题是:每一步我们想要哪棵树?一个很自然的事情就是添加一个优化我们目标的。
如果我们考虑使用均方误差(MSE)作为损失函数,目标就变成了:
MSE的形式很友好,有一次项(通常称为残差)和二次项。对于其他的损失(例如逻辑损失),要得到这样好的表单并不容易。一般情况下,我们把损失函数的泰勒展开式推广到二阶:
和
的定义为:
在我们移除所有常数之后,在步骤处的特定目标就变成了:
这就是我们对新树的优化目标。这个定义的一个重要优点是目标函数的值只取决于和
。这就是XGBoost支持自定义损失函数的方式。我们可以优化每一个损失函数,包括逻辑回归和成对排序,使用完全相同的解决方案,以
和
为输入!
Model Complexity
我们已经介绍了训练步骤,但是等一下,有一件重要的事情,正则化术语!我们需要定义树的复杂度。为了做到这一点,让我们首先改进树
的定义为:
其中为叶子节点的得分向量,
为将每个数据点赋值到对应叶子的函数,
为叶子数量。在XGBoost中,我们将复杂性定义为:
当然,定义复杂性的方法不止一种,但是这种方法在实践中很有效。正则化是大多数树包处理得不太仔细的一部分,或者干脆忽略它。这是因为传统的树学习方法只强调改善杂质,而复杂性控制则留给启发式。通过正式定义它,我们可以更好地了解我们正在学习什么,并获得表现良好的模型。
The Structure Score
这就是推导的神奇之处。重新制定树模型后,我们可以将第颗树的目标值写成:
其中是分配给第
个叶子的数据点的索引集。注意,在第二行中,我们更改了求和的索引,因为同一叶子上的所有数据点都得到相同的分数。我们可以进一步压缩表达式,定义
和
:
在这个方程中,彼此独立,公式
是二次的,给定结构
的最佳
和减少最好的目标我们可以得到:
最后一个方程衡量了树结构的好坏。

如果这一切听起来有点复杂,让我们看看图片,看看如何计算分数。基本上,对于给定的树结构,我们将统计数据和
推到它们所属的叶子上,将统计数据相加,然后使用公式计算树的好坏。这个分数类似于决策树中的杂质度量,除了它还考虑了模型的复杂性。
Learn the tree structure
现在,我们有了一种方法来衡量一棵树的好坏,理想情况下,我们会列举所有可能的树,然后选出最好的一棵。在实践中,这是一个棘手的问题,因此我们将尝试一次优化树的一个级别。具体来说,我们试着把一片树叶分成两片,它得到的分数是:
该公式可分解为:1)新左叶分数2)新右叶分数3)原叶分数4)附加叶正则化。我们可以看到一个重要的事实:如果获得小于,我们会做的更好不是添加分支。这正是基于树的模型中的修剪技术!通过使用监督学习的原则,我们可以很自然地得出这些技术有效的原因:
对于实值数据,我们通常希望寻找最优的分割。为了有效地做到这一点,我们将所有实例排序,如下图所示。
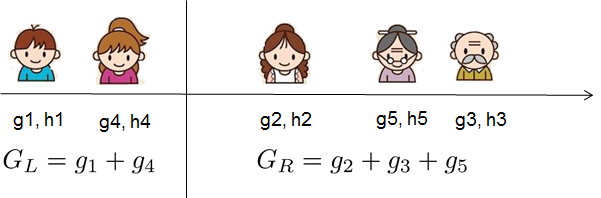
从左到右的扫描足以计算所有可能的分裂解的结构分数,我们可以有效地找到最佳分裂。
注意
加法树学习的局限性
由于难以枚举所有可能的树结构,所以我们一次添加一个分割。这种方法在大多数情况下都能很好地工作,但是也有一些由于这种方法而失败的边缘情况。对于这些边缘情况,由于我们一次只考虑一个特征维,所以训练结果是退化模型。看一下可以学习简单的梯度增强算法吗?了一个例子。
Final words on XGBoost
现在您已经了解了什么是助推树,您可能会问,XGBoost的介绍在哪里?XGBoost正是本教程中介绍的正式原则所激发的工具!更重要的是,它是在深入考虑系统优化和机器学习原理的基础上发展起来的。这个库的目标是突破计算机的计算极限,提供一个可伸缩的、可移植的、精确的库。请务必尝试一下,最重要的是,向社区贡献您的智慧(代码、示例、教程)!
XGBoost教程
在AWS上分布XGBoost纱线

















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









