 Hive基础与进阶详解
Hive基础与进阶详解




大数据学习week3
Hive基础部分
Hive的体系架构
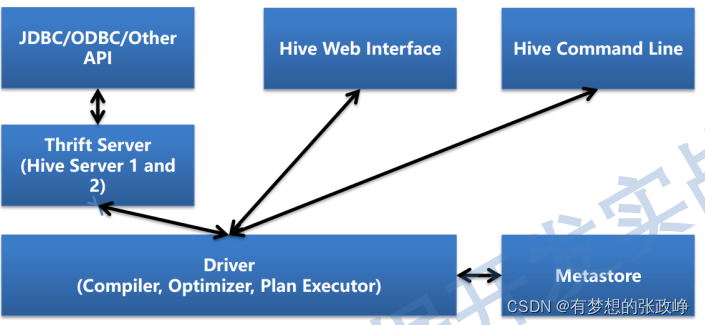
用户接口主要有三个:CLI(command line interface)命令行,JDBC 和 Web UI, CLI是开发过程中常用的接口,在hive Server2提供新的命令beeline,使用sqlline语法,会有单独的章节来介绍。
metaStore: hive的元数据结构描述信息库,可选用不同的关系型数据库来存储,通过配置文件修改、查看数据库配置信息。
Driver: 解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行 。
常见的三个面试问题
- 什么是内部表和外部表?90%
- 它们之间的主要区别是什么?80%
- 使用它们的最佳实践是什么?20% (最佳实践)
Hive 建表高阶语句 CTAS and CTE
- CTAS–按选择创建表格
基于select查询的结果生成表 - 不能生成分区表,外部表,桶表
- 像其他表格一样创建表格(fast)
复制表的结构,不携带数据
分区(partition):
- 为了提高性能,Hive可对数据进行分区
分区列的值将表分成段
查询时可以忽略整个分区 - 必须由用户正确创建分区。 插入数据时必须指定分区
- 在查询中使用时,“分区”列和常规列之间没有区别
- 在查询时,Hive将自动过滤掉未使用的分区以获得更好的性能
分桶(Buckets)
- bucket对应于HDFS中的文件段
- 随机抽样数据或加速JOIN的速度
- 根据“bucket列”的哈希函数将数据分成一组
- Hive不会自动执行分桶。 需要设置强制分桶
SET hive.enforce.bucketing = true; - 存储桶列的选择密切依赖于业务逻辑
- 要定义桶的数
量,我们应该避免每个桶中的数据太多或太少。 在靠近两个数据块的地方更好的选择。 使用2N作为桶的数量.
Hive进阶部分
什么是数据仓库
- 数据仓库解决方案构建在hadoop之上
- 提供类似SQL的查询语言Hive Query Language-HQL,它具有最小的学习曲线
强调文本 强调文本
Hive的视图
- View是一种逻辑结构,通过隐藏虚拟表中的子查询,连接和函数来简化查询
- Hive视图不存储数据不能物化
- 创建视图后,立即冻结其架构
- 如果删除或更改基础表,则查询视图将失败
- 视图是只读的,不能用作LOAD/INSERT/ALTER的目标
hive mapjoin
- MAPJOIN语句意味着只通过map执行连接,没有reduce job
MapReduce编程可以只有map阶段而没有reduce阶段. - MapJoin会读取小表中所有的数据到内存,然后广播到所有的运行map任务的节点。
类似于MapReduce DC,也就是Distributed Catch,分布式缓存 - 设置 hive.auto.convert.join=true后,Hive会在运行时自动将JOIN转换为MAPJOIN
有没有弊端呢?有弊端的,有时候会造成内存溢出
4.不支持如下操作
Use MAPJOIN after UNION ALL, LATERAL VIEW, GROUP BY/JOIN/SORT BY/CLUSTER BY/DISTRIBUTE BY
Use MAPJOIN before by UNION, JOIN and other MAPJOIN
5.底层就是基于Mapreduce的DC(分布式缓存)来实现的。
学习回顾
- hive的分区和分桶的概念
- 动态分区和静态分区的比较
- hive进阶中的语法的掌握
- hive的视图以及窗口案例的实践

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









