



 本文介绍了大数据的基本概念,包括其三大特征:体量、多样性和价值。大数据的快速增长使得需要Hadoop这样的平台来处理。数据分析是为商业目标服务的数据收集、整理、加工和分析过程。在Hadoop生态系统中,Namenode负责元数据管理,而Datanode处理数据存储,两者不放在同一节点以确保数据安全和系统稳定性。此外,还探讨了并发与并行的区别。学习回顾中提到了NameNode与DataNode的关系以及HDFS的相关操作。
本文介绍了大数据的基本概念,包括其三大特征:体量、多样性和价值。大数据的快速增长使得需要Hadoop这样的平台来处理。数据分析是为商业目标服务的数据收集、整理、加工和分析过程。在Hadoop生态系统中,Namenode负责元数据管理,而Datanode处理数据存储,两者不放在同一节点以确保数据安全和系统稳定性。此外,还探讨了并发与并行的区别。学习回顾中提到了NameNode与DataNode的关系以及HDFS的相关操作。
什么是大数据
大数据是一个一个描述大量高速,复杂和可变数据的术语,需要先进的技术来实现信息的捕获,存储,分发,管理和分析。
大数据的特征
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- Volume(体量) – 90% created in the last 2ys. 50% in Hadoop after 5ys (百分之90的数据在过去二年产生,未来有百分之50的数据会在Hadoop这个平台);
- Volume(体量) – 90% created in the last 2ys. 50% in Hadoop after 5ys (百分之90的数据在过去二年产生,未来有百分之50的数据会在Hadoop这个平台);
- Variety – Multiple data formats (数据格式);
- Value – The knowledge gained by exploring data (通过探索数据获得的知识);
数据分析定义及特征
定义:
数据分析是基于商业目的的,有目的的进行收集、整理、加工和分析数据,提炼有价值信息的过程。
特征:
1.Time-based
A piece of data is something known at a certain moment in time, and that time is an important element (数据产生的时间是一个重要的元素);
2. Immutable
Because of its connection to a point in time, the truthfulness of the data does not change. We look at changes in big data as new entries, not updates of existing entries (数据的真实性不会改变。我们将大数据的变化视为新条目,而不是现有条目的更新);
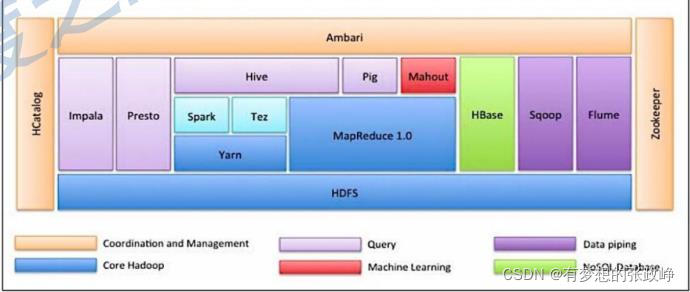
hadoop的生态图
并发与并行
高并发:主要是在web领域;把任务在不同的时间点交给处理器进行处理;在同一时间点,任务并不会同时运行。
并行运算:大数据领域;并行是把每一个任务分配给每一个处理器独立完成;在同一时间点,任务一定是同时运行。
强调文本 强调文本
Namenode和Datanode为什么不放在一个节点?
Datanode负责I/O处理数据的读写,Namenode处理请求响应
Namenode(NN)管理命名空间和“inode table”
Datanode(DN)
1.Datanode存储hdfs上block文件块,在一个hdfs的分布式文件系统里可以有多个Datanode,每个Datanode周期性的和Namenode通信,客户端也可以和Datanode进行交互或Datanode也可以进行互相通信
2.存储数据
3.报告给Namenode
4.许多机器上运行
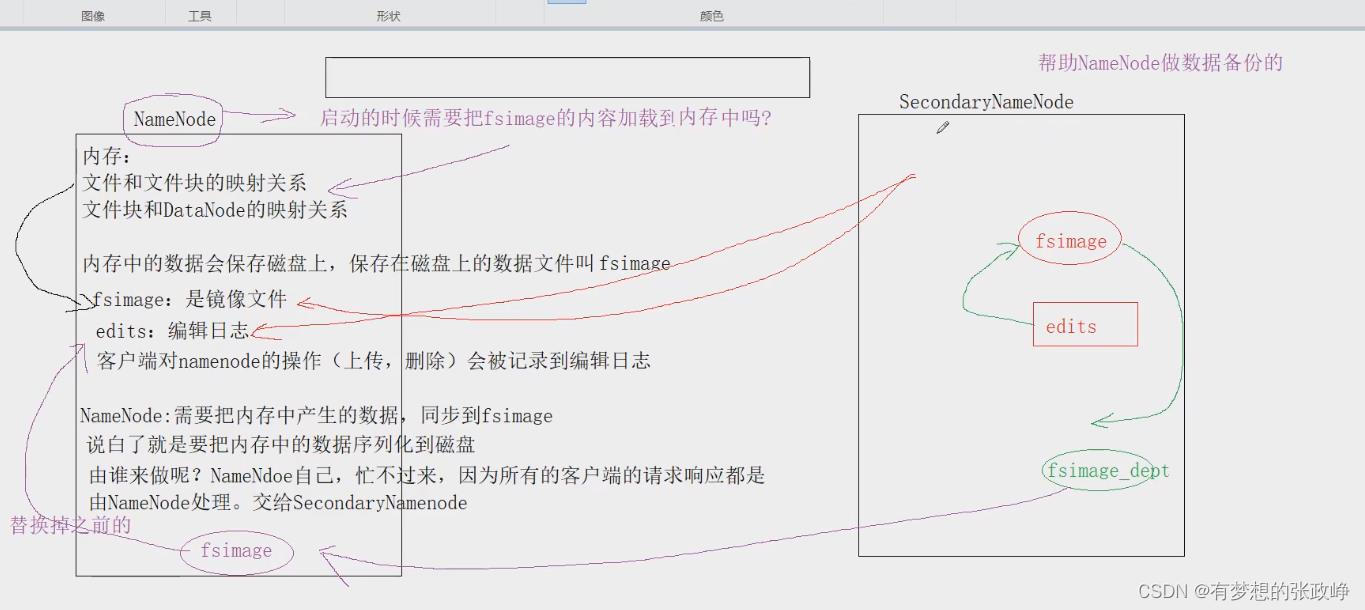
secondaryNamenode不可以替代Namenode
学习回顾
- NameNode存储数据吗?
- NameNode和DataNode的关系
- 通过Java实现对HDFS的文件读写
- 常用的HDFS命令有那些
- hdfs上的副本在节点之间如何保存的

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









