







 文章分析了在C++中使用std::variant时,编译器在优化时避免了不必要的递归,直接操作存储结构,显示了现代编译器在性能上的智能。作者强调了在编写代码时应注重可读性和可重用性,性能优化应在必要时针对热点进行。
文章分析了在C++中使用std::variant时,编译器在优化时避免了不必要的递归,直接操作存储结构,显示了现代编译器在性能上的智能。作者强调了在编写代码时应注重可读性和可重用性,性能优化应在必要时针对热点进行。
我曾经在《Modern C++ std::variant的实现原理》分析了get<n>(variant)的实现,并由实现推断结论:如果你非常看重效率,那么请把常用的类型安排在前面。
基于的原因也很直接,它有个递归在里面:

过后,我反思了一下,这是debug模式,编译器可能没那么傻!
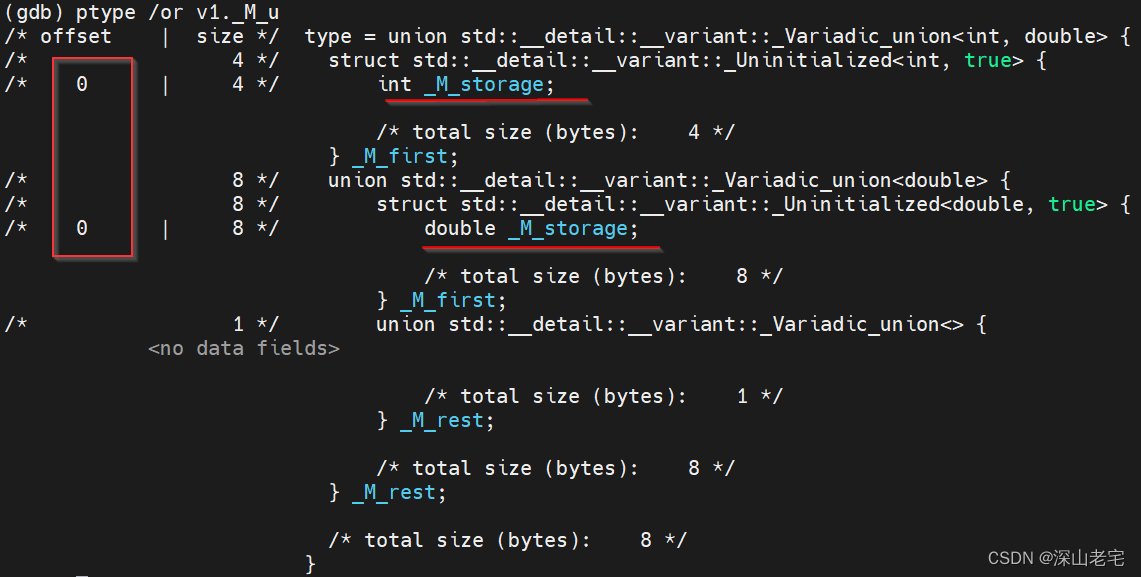
因为是union,所以上面三个return后面接的变量地址都相同,即
&v1._M_u._M_first == &v1._M_u._M_rest._M_first == &v1._M_u._M_rest._M_rest._M_first

从另一个角度看看:GDB打印_M_u, 包含每个成员的offset
所以没必要真正的递归那么多次去取,我们看看优化后的汇编代码怎么做的?
一个简单的程序:
#include <iostream>
#include <variant>
#include <string>
using namespace std;
int main() {
std::variant<char,double,string,int> v1(3);
cout<<"addr of v1:"<<&v1<<endl;
get<3>(v1)+=10;
cout<<get<3>(v1)<<endl;
return 0;
}
开启O2优化, 反汇编:
401190: 41 54 push %r12
401192: 66 0f ef c0 pxor %xmm0,%xmm0
401196: be 10 20 40 00 mov $0x402010,%esi
40119b: bf c0 40 40 00 mov $0x4040c0,%edi
4011a0: 55 push %rbp
4011a1: 48 83 ec 48 sub $0x48,%rsp
4011a5: 48 c7 44 24 30 00 00 movq $0x0,0x30(%rsp)
4011ac: 00 00
4011ae: 48 8d 6c 24 10 lea 0x10(%rsp),%rbp
4011b3: 0f 29 44 24 10 movaps %xmm0,0x10(%rsp)
4011b8: c6 44 24 30 03 movb $0x3,0x30(%rsp)
4011bd: c7 44 24 10 03 00 00 movl $0x3,0x10(%rsp) //$rsp+0x10为v1的地址
4011c4: 00
4011c5: 0f 29 44 24 20 movaps %xmm0,0x20(%rsp)
4011ca: e8 b1 fe ff ff callq 401080 <_ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc@plt>
4011cf: 48 89 c7 mov %rax,%rdi
4011d2: 48 89 ee mov %rbp,%rsi
4011d5: e8 86 fe ff ff callq 401060 <_ZNSo9_M_insertIPKvEERSoT_@plt>
4011da: 48 89 c7 mov %rax,%rdi
4011dd: e8 6e 01 00 00 callq 401350 <_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_.isra.0>
4011e2: 80 7c 24 30 03 cmpb $0x3,0x30(%rsp)
4011e7: 0f 85 6e ff ff ff jne 40115b <main.cold>
4011ed: 8b 44 24 10 mov 0x10(%rsp),%eax //&v1 -> $eax
4011f1: bf c0 40 40 00 mov $0x4040c0,%edi
4011f6: 8d 70 0a lea 0xa(%rax),%esi //v1+10 -> $esi
4011f9: 89 74 24 10 mov %esi,0x10(%rsp) //$esi -> v1
4011fd: e8 ee fe ff ff callq 4010f0 <_ZNSolsEi@plt>
401202: 48 89 c7 mov %rax,%rdi
401205: e8 46 01 00 00 callq 401350 <_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_.isra.0>
40120a: 0f b6 44 24 30 movzbl 0x30(%rsp),%eax
40120f: 48 89 ee mov %rbp,%rsi
401212: 48 8d 7c 24 0f lea 0xf(%rsp),%rdi
401217: ff 14 c5 c0 20 40 00 callq *0x4020c0(,%rax,8)
40121e: 48 83 c4 48 add $0x48,%rsp
401222: 31 c0 xor %eax,%eax
401224: 5d pop %rbp
401225: 41 5c pop %r12
401227: c3 retq
401228: e9 38 ff ff ff jmpq 401165 <main.cold+0xa>
40122d: 0f 1f 00 nopl (%rax)
上面我注释了最关键的4行汇编代码,为了方便看,我把它们单独拿下来:
4011bd: c7 44 24 10 03 00 00 movl $0x3,0x10(%rsp) //$rsp+0x10为v1的地址
4011ed: 8b 44 24 10 mov 0x10(%rsp),%eax //&v1 -> $eax
4011f6: 8d 70 0a lea 0xa(%rax),%esi //v1+10 -> $esi
4011f9: 89 74 24 10 mov %esi,0x10(%rsp) //$esi -> v1编译器根本没有不停的递归取下一个_M_rest, 而是直接把v1的前四个字节 load 到寄存器,加10后再存回去。
很真别小看了编译器。如今写代码要更多的注重“可读性”“可重用性”,至于performance如有必要之后可以找热点。



















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











