算法
1、数据结构中的算法,指的是数据结构所具备的功能。
2、解决特定问题的方法,他是前辈们的一些优秀的经验总结。
分治:
把一个大而复杂的问题,分解为很多个小的而简单的问题,利用计算机的强大计算能力来解决问题。
递归
是函数自己调用自己的一种行为,可以形成循环调用,进而实现分治算法。
什么情况下使用递归:
1、问题过于复杂无法拆解成循环语句。
2、问题非线性,而函数递归,由于借助栈内存,函数的每一此调用,就会把它的数据重新压入栈空间,它的数据都会保留下来,可以解决非线性的问题(二叉树的相关算法,汉诺塔问题等)。
在单线程模式下永远只能同时执行一个函数,当函数自己调用自己时(子集),会先执行子集的代码,然后子集执行完成后再返回到上一级继续执行。
如何安全实现递归:
使用递归很有可能造成"死循环",非常耗费资源。
1、先写出口,考虑如何让无限的调用停止下来。
if(条件) return;
2、解决一处小问题
3、把剩下的问题交给我的下一级(参数发生变化)
递归的优点:
代码简单,容易理解。
递归的缺点:
容易形成死循环,耗费内存,执行效率低(参数入栈,出栈,局部变量的定义、销毁)。
查找
顺序查找:从头到尾逐一比较,对于数据没有要求,但方法简单,在小规模的数据查找中比较实用,但效率低。
二分查找:前提就是数据必须有序,然后从数据的中间位置开始查起,若中间位置的数据比要查找的位置小,则从中间位置的左边找,否则从右边找。
从代码实现上来说,既可以用循环实现,也可以用递归实现。
块查找、权重查找,适用于特殊条件下,需要对数据进行排序、分析、总结、归纳。
排序
排序算法的稳定性:当序列中有相等的数据时,算法会不会改变这两个数据的前后位置。
冒泡:
是一种稳定排序,在排序过程中可以监测到数据是否已经有序(对数据的有序性敏感),可以立即停止,如果待排序的数据基本有序,则冒泡的效率是非常高的。
插入排序:
是一列数已经有序,再有新加入的数据时,适合使用插入排序。
选择排序:
是冒泡排序的一种变种,但是它没有冒泡对数据有序性的敏感,但它在排序过程中比冒泡少了很多数据交换,因此要比冒泡要快(数据比较混乱的情况下)。
快速排序:
一种基于交换的一种排序。
堆排序:
首先把数据当作完全二叉树,然后保障根结点最大,然后把根结点与最后一个元素交换,然后再调整二叉树(逐渐减少数组),让根依然保持最大,然后重复上次操作。
归并排序:
不交换数据,但需要借助额外的空间,用作临时的存储空间。
除了这些排序算法,还有很多其它的排序算法
各种排序的时间复杂度、空间复杂度
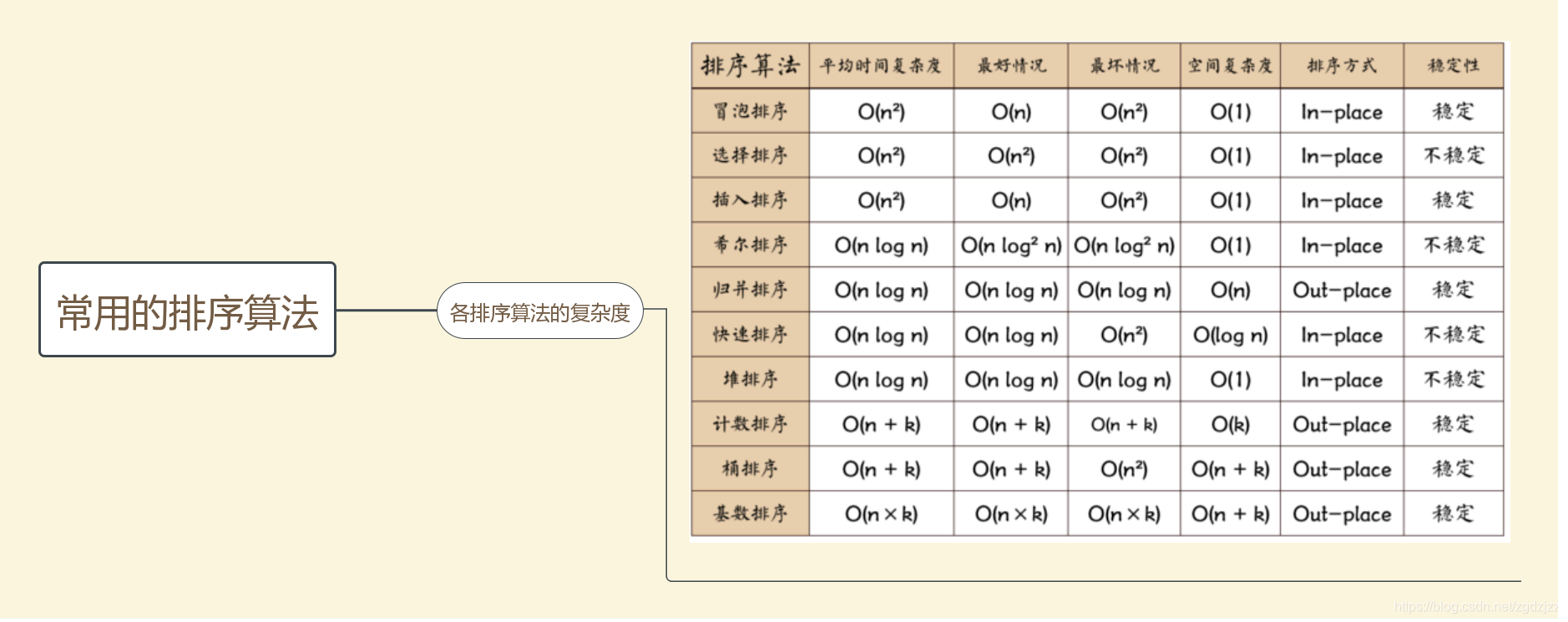
 经典算法与数据结构解析
经典算法与数据结构解析







 本文深入探讨了数据结构中的核心算法,包括分治、递归、查找与排序算法,详细解析了各种算法的工作原理、优缺点及适用场景,特别强调了排序算法的稳定性与时间、空间复杂度。
本文深入探讨了数据结构中的核心算法,包括分治、递归、查找与排序算法,详细解析了各种算法的工作原理、优缺点及适用场景,特别强调了排序算法的稳定性与时间、空间复杂度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









