






一、原理与作用机制
红黑树:自平衡二叉查找树
核心原理:通过颜色标记(红/黑)和旋转操作维护近似平衡,确保从根到叶的最长路径不超过最短路径的2倍13。其平衡规则包括:根节点为黑色、红色节点不能连续出现、各路径黑色节点数相同等。
作用机制:插入/删除时,通过变色和旋转(左旋、右旋)调整结构,时间复杂度稳定在 O(log n)。
// 左旋操作(C语言示例)
void leftRotate(TreeNode** root, TreeNode* x) {
TreeNode* y = x->right;
x->right = y->left;
if (y->left) y->left->parent = x;
y->parent = x->parent;
if (!x->parent) *root = y;
else if (x == x->parent->left) x->parent->left = y;
else x->parent->right = y;
y->left = x;
x->parent = y;
}
颜色翻转:解决连续红色节点问题:
private void flipColors(Node<T> h) {
h.color = !h.color;
h.left.color = !h.left.color;
h.right.color = !h.right.color;
}
B树:多路平衡查找树
核心原理:每个节点存储多个键值对(通常填满磁盘页大小),通过节点分裂与合并维持平衡。例如,一个m阶B树要求节点子节点数在 ⌈m/2⌉到m 之间。
作用机制:利用多叉结构降低树高,减少磁盘I/O次数。查找时通过二分法定位子节点,适合随机读写场景。
B+树:重点
核心原理:非叶子节点仅存储键(不存数据),所有数据存储在叶子节点,且叶子节点通过链表连接形成有序序列。
作用机制:范围查询时通过叶子链表顺序遍历,避免回溯父节点。内部节点仅作索引,进一步压缩树高,提升查询效率。
struct BPlusTreeNode {
int key_count;
KeyType keys[MAX_KEYS + 1];
struct BPlusTreeNode* children[MAX_KEYS + 2];
struct BPlusTreeNode* next; // 叶子节点链表指针
bool is_leaf;
};
插入后若叶节点满则分裂,中间键提升至父节点并维护链表:
public void insert(int key) {
if (root == null) {
root = new Node();
root.keys.add(key);
return;
}
Node current = root;
// 递归插入并分裂
if (current.isLeaf()) {
current.keys.add(key);
Collections.sort(current.keys);
if (current.keys.size() > MAX_KEYS)
splitLeaf(current);
} else {
// 定位子节点递归插入
}
}
提问:B+树中间节点的存储内容
中间节点(非叶子节点)不存储实际数据,而是存储键值(Key)和指针(Pointer),具体包括:键值(Key):用于分隔子树的取值范围。例如,若某中间节点包含键值K1和K2,则其左子树中所有键值 ≤ K1,中间子树的键值在(K1, K2]之间,右子树键值 > K2。
指针(Pointer):指向子节点(下一层节点)。中间节点的指针数比键值数多1,即若有n个键值,则有n+1个指针。
例如,一个中间节点的结构可能为:
[P0, K1, P1, K2, P2, ..., Kn, Pn]
其中,K1 < K2 < ... < Kn,P0指向键值 ≤ K1的子树,P1指向键值在(K1, K2]的子树,依此类推。
提问: 如何通过中间节点找到数据?
B+树的查找过程是自顶向下逐层搜索,具体步骤如下:
从根节点开始:将目标键值与中间节点的键值依次比较,确定下一步应进入的子树。
逐层向下:重复上述比较过程,直到到达叶子节点。
在叶子节点中定位数据:
叶子节点存储所有实际数据(或指向数据的指针),并按键值有序排列。
若为精确查找,通过二分法或顺序遍历找到目标键值对应的数据。
若为范围查询,利用叶子节点间的双向链表结构快速遍历相邻节点。
二、核心差异分析
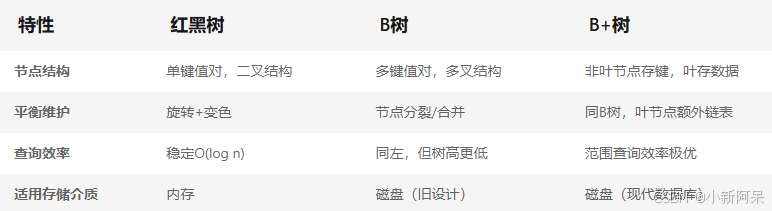
关键区别总结:树高与I/O优化:B/B+树通过多叉结构显著降低树高(例如1亿数据下,红黑树高约30,B+树仅需3-4层),减少磁盘访问次数。
范围查询支持:B+树叶子链表实现高效范围遍历(如查询[A,Z]仅需定位起点后顺序读取),而红黑树和B树需逐层回溯。
数据存储位置:B+树将数据集中在叶子节点,非叶节点仅存储索引,提升节点利用率。
三、典型应用场景
红黑树:
用途:内存密集型高频操作场景,如C++ STL的map、Java的TreeMap、Linux进程调度。
优势:插入/删除性能稳定,适合动态数据集。
B树:
用途:早期文件系统(如NTFS)、部分数据库(如MongoDB的默认索引)。
局限:范围查询效率低,逐渐被B+树替代。
B+树:
用途:现代关系型数据库(MySQL InnoDB、Oracle)、文件系统索引、大数据存储引擎。
优势:结合多叉结构与顺序访问特性,兼顾随机查询与范围扫描。
四、选型决策指南
内存 vs 磁盘:
内存操作优先红黑树(高频增删),磁盘存储必选B+树(I/O优化)。
查询模式:
随机查询:B/B+树均适用。
范围查询:B+树绝对优势(叶子链表遍历)。
数据规模:
小数据量:红黑树更灵活。
海量数据:B+树通过多级索引压缩树高,避免性能劣化。
五、总结与展望
红黑树、B树、B+树的设计哲学体现了计算机科学中时空权衡的核心思想:红黑树以内存效率优先,B/B+树以磁盘I/O优化为纲。随着存储技术的发展(如SSD随机访问速度提升),B+树的主导地位可能面临新结构的挑战,但其基于局部性原理和预读机制的设计思想仍将持续影响数据库与文件系统的演进。


















 13
13

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











