






Parallel Query, supported from version 9.6, is a feature that processes a single query using multiple processes (Workers).
For instance, if certain conditions are met, the PostgreSQL process that executes the query becomes the Leader and starts up to Worker processes (maximum number is max_parallel_workers_per_gather). Each Worker process then performs scan processing, and returns the results sequentially to the Leader process. The Leader process aggregates the results returned from the Worker processes.
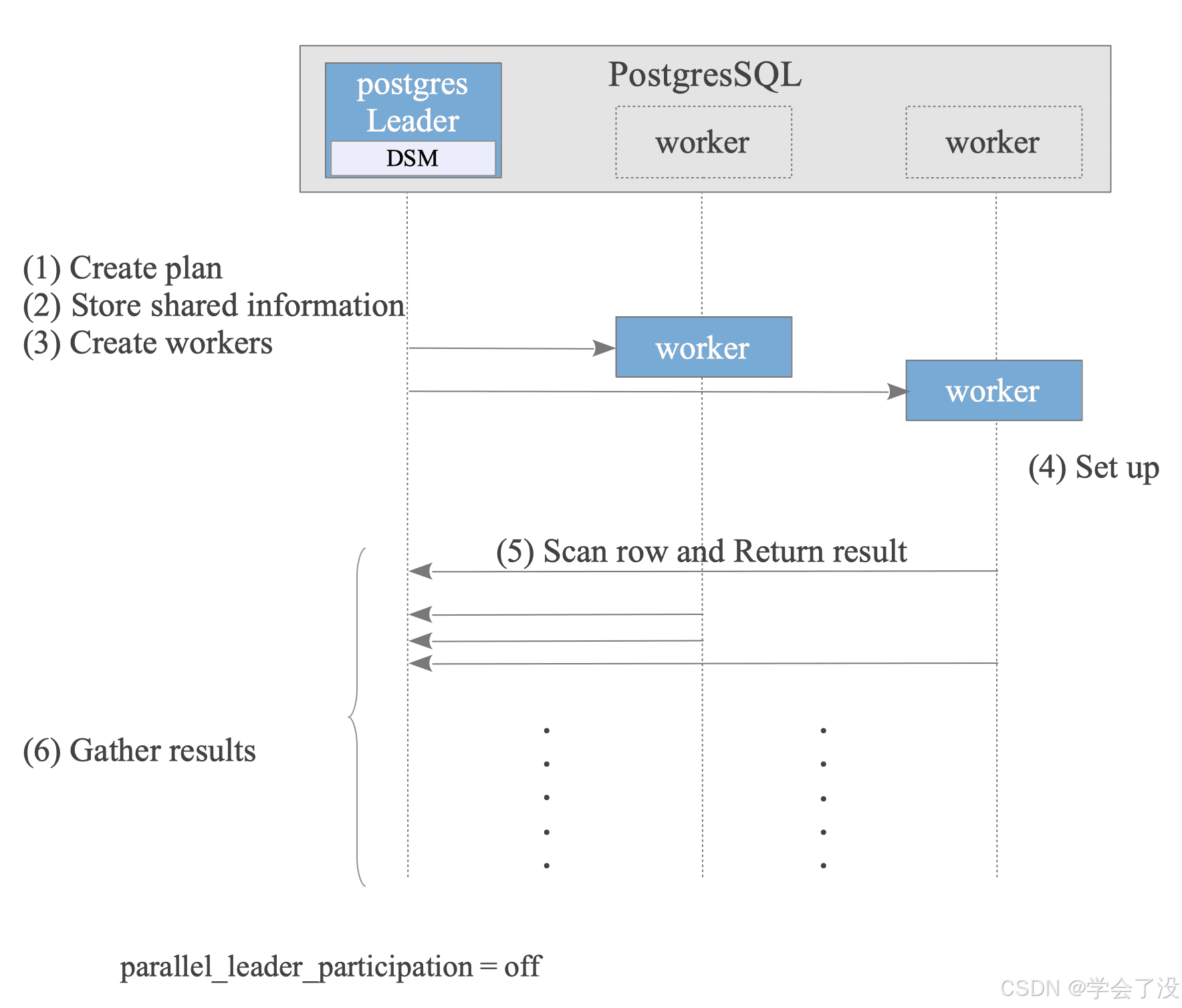
- Leader Creates Plan:
The optimizer creates a plan that can be executed in parallel. - Leader Stores Shared information:
To execute the plan on both the Leader and Worker nodes, the Leader stores necessary information in its Dynamic Shared Memory (DSM) area. For more details, see the following explanation. - Leader Creates Workers.
- Worker Sets up State:
Each worker reads the stored shared information to sets up its state, ensuring a consistent execution environment with the Leader. - Worker Scans rows and Returns results.
- Leader Gathers results.
- After the query finishes, the Workers are terminated, and the Leader releases the DSM area.
In Parallel Query processing, the Leader and Worker processes communicate Dynamic Shared Memory (DSM) area.
The Leader process allocates memory space on demand (i.e., it can be allocated as needed and released when no longer required). Worker processes can then read and write data to these memory regions as if they were their own.
并行查询,从版本9.6开始支持,是一个使用多个进程(Worker)处理单个查询的功能。
例如,如果满足某些条件,执行查询的PostgreSQL进程将变成领导者(Leader),并启动最多max_parallel_workers_per_gather个 Worker 进程。每个Worker进程然后进行扫描处理,并将结果按顺序返回给Leader进程。Leader进程聚合从Worker进程中返回的结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









