




做业务开发的java程序员在工作中其实很少有机会接触到算法,原因有二:
1.jdk 里面对常用的数据结构和算法都有封装,直接拿来用即可
2. 普通业务开发基本上不存在算法优化等需求,性能优化基本上都是储存(sql redis、es等中间件层面的),对应到java代码里面就是jdbc sql 优化,不合理的for循环、和不合理的接口调用等。
所以这就造就了一个尴尬局面:
1.jdk 里面封装的类库众多,因为是通用类库,代码作者考虑的点非常全面,方法参数和细节逻辑众多,学习曲线大,能够熟练使用就很难,弄清楚源代码原理更是难上加难。
2.因为用不到,加上学起来比较难,最后导致的结果就是很多工作很多年的java程序员都只用jdbc做增删查改。
偶尔学一下jdk 源码,哪怕只是一个方法,都能受益匪浅的。
java.util.Collections#iteratorBinarySearch(list,key)
方法使用注意点:
1. 入参list必须是升序排列的
2. 返回值>=0, 则表示key 存在list 中, 返回值是key在list中的下标;返回值<0则表示key不存在list中,返回值= -(应该插入下标+1)

二分查找,也叫折半查找 , 时间复杂度是 log(n)
二分查找比较容易理解,如果第一次接触,可以看一下动画演示:
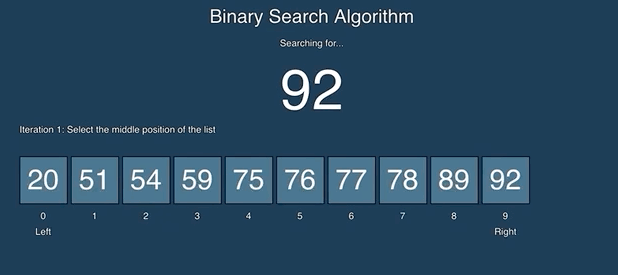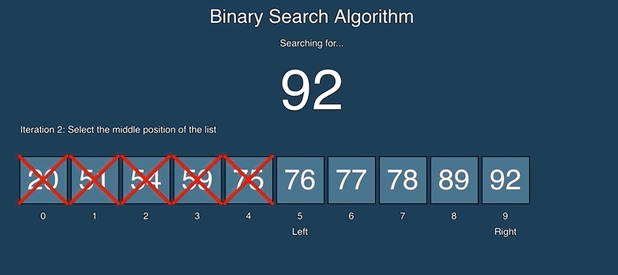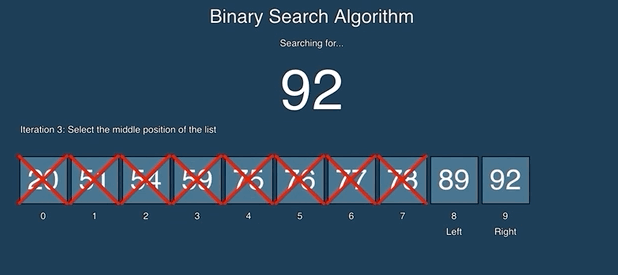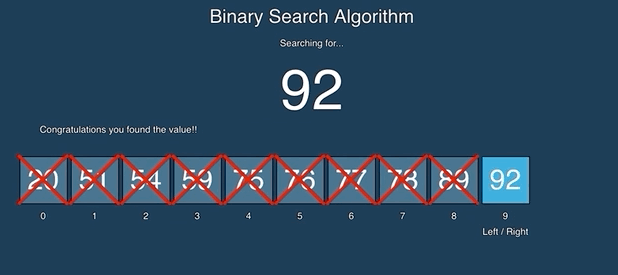
源码:
int indexedBinarySearch(List<? extends Comparable<? super T>> list, T key) {
int low = 0;
int high = list.size()-1;
while (low <= high) {
int mid = (low + high) >>> 1;
Comparable<? super T> midVal = list.get(mid);
int cmp = midVal.compareTo(key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found
}
关键源码讲解:
1. int mid = (low + high) >>> 1;
mid 就是求公差为1(下标连续)的等差数列的平均数
>>> 无符号右移,相当于除以2,性能比除法好 , 除不尽向下取整, 比如 0,1,2,3,4,5,6,7 第一次二分mid是3,所以当有偶数个元素时,mid不是正中间位置。
2. while (low <= high) 多次重试二分过程
3. return -(low + 1);
这一句为什么要+1,我没看明白,通过网络搜索,发现原因如下:当low=0(待插入的位置是0)的时候无法区分是已匹配还是未匹配(0不分正负) , 加1就保证没有匹配到永远返回的是负数 。
这里我们可以深刻领会到代码严谨的重要性,哪怕是写业务代码,也需要考虑好各种边界值和极端情况。

















 5305
5305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









