 C++实现组平均凝聚式层次聚类算法
C++实现组平均凝聚式层次聚类算法





 本文介绍了凝聚式层次聚类的概念,特别是自底向上的聚类方法,也称为HAC。讨论了单链接、全链接、质心和组平均四种聚类算法。重点讲解了在信息检索任务中,如何使用C++实现组平均方法,虽然实际代码可能因理解错误而采用了质心法,且效率不高。文章提供了相关代码和效果预览。
本文介绍了凝聚式层次聚类的概念,特别是自底向上的聚类方法,也称为HAC。讨论了单链接、全链接、质心和组平均四种聚类算法。重点讲解了在信息检索任务中,如何使用C++实现组平均方法,虽然实际代码可能因理解错误而采用了质心法,且效率不高。文章提供了相关代码和效果预览。
凝聚式层次聚类
层次聚类可以是自顶向下或自底向上的一个过程。自底向上的算法一开始将每篇文档都看成是一个簇,然后不断地对簇进行两两合并(或称凝聚(agglomerate)),直到所有文档都聚成一类为止。自底向上的聚类方法也因此被称为 HAC。
根据簇的相似度计算方式可以分为单链接,全链接,质心,组平均四种HAC聚类算法。
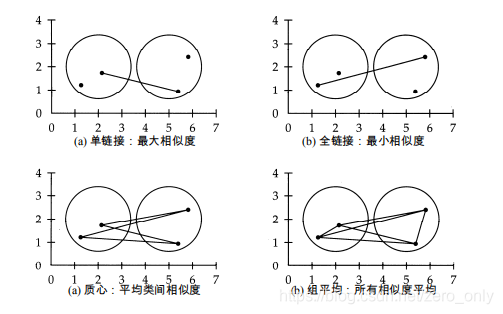
例如:簇1有点a(1,2)和b(5,3),簇2有点x(2,3)和y(7,4)
有距离矩阵dis【2】【2】;
则根据单链接:簇相似度=min(dis[a,x],dis[a][y],dis[b][x],dis[b][y])
全链接:簇相似度=max(dis[a,x],dis[a][y],dis[b][x],dis[b][y])
质心:簇相似度=ave(dis[a,x],dis[a][y],dis[b][x],dis[b][y])
组平均:簇相似度=ave(dis[a,x],dis[a][y],dis[b][x],dis[b][y],dis[a][b],dis[x][y])
这次信息检索让用组平均做hac,但时间紧匆忙赶出来的情况下,理解错了组平均的计算方式,现在看来,是按照质心法做的,而且是最笨的方式,效率极低。现在暂时也懒得改了。附上组平均HAC的高效计算公式

代码
//
HAC.h
#pragma once
#include<vector>
using namespace std;
struct Position
{
double a;
double b;
double c;
double d;
double e;
};
struct Cluster
{
vector<int> pointindex;
int clusterID;
vector<double> avedistance;
};
struct Point
{
Position position;
int pointID;
};
class HAC
{
private:
vector<Point> point;
vector< Cluster> cluster;
double distance[20][20]; //点对距离矩阵
int minindex[2]; //最小组平均的两个簇序号
public:
HAC();
~HAC(){
}
void calave(); //计算组平均距离
void merge(); //求最小组平均,合并簇
void print(); //显示每次合并的情况
};
// HAC.cpp
#include "HAC.h"
#include<time.h>
#include<math.h>
#include<algorithm>
#include <iostream>
#include <iomanip>
HAC::HAC() {
//向量初始化
int a, b, c, d, e;
double sum;
Point pointtemp;
Cluster clustertemp;
srand((unsigned)time(NULL));//time()用系统时间初始化种。为rand()生成不同的随机种子。
cout << "初始随机生成的20个经过归一化的五维向量为:" << endl;
for (int i = 0; i < 20; i++)
{
a = rand() % 100 + 1;//生成1~100随机数
b = rand() % 100 + 1;
c = rand() % 100 + 1;
d = rand 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









