







 本文介绍了ChatGPT模型,它是InstructGPT的兄弟模型,专为对话设计。ChatGPT通过改进的人类反馈强化学习(RLHF)进行训练,能够理解和生成复杂的对话。基于GPT-3.5系列,ChatGPT支持编写程序。尽管如此,模型仍存在局限性,如可能产生不准确的回答等。
本文介绍了ChatGPT模型,它是InstructGPT的兄弟模型,专为对话设计。ChatGPT通过改进的人类反馈强化学习(RLHF)进行训练,能够理解和生成复杂的对话。基于GPT-3.5系列,ChatGPT支持编写程序。尽管如此,模型仍存在局限性,如可能产生不准确的回答等。
1.简介
最近ChatGPT很好,本文根据https://openai.com/blog/chatgpt/翻译总结的。
ChatGPT: Optimizing Language Models for Dialogue。如标题,ChatGPT为了对话使用的。
ChatGPT是InstructGPT的兄弟模型,它被训练为以提示prompt的方式遵循指令并提供详细的响应。
2.方法
采用同InstructGPT一样的训练方法,使用Reinforcement Learning from Human Feedback (RLHF)。也是三步,如下图。ChatGPT和InstructGPT不同的,只是数据收集上有轻微的不同。人类AI训练者在对话中扮演两个角色,用户和AI助手。
InstructGPT的介绍详见:https://blog.youkuaiyun.com/zephyr_wang/article/details/128333153。
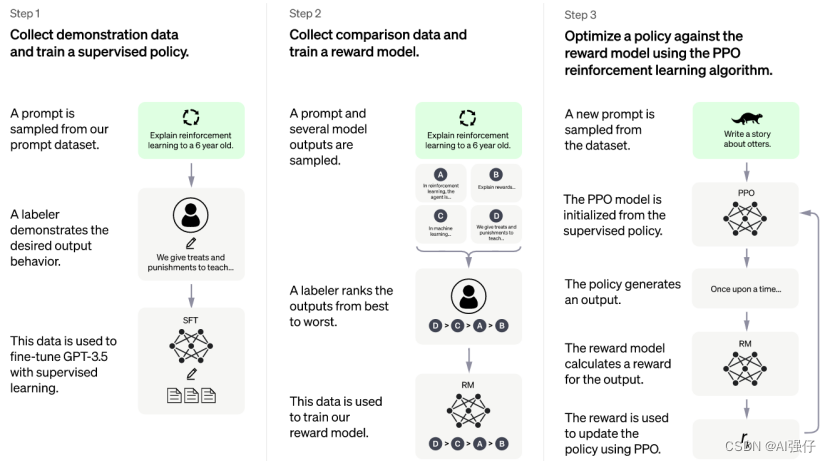
ChatGPT基于GPT-3.5 系列微调。
GPT-3.5 系列模型如下,可以看到有code模型,所以支持写程序:

3.ChatGPT不足
1)ChatGPT有时会写出看似合理但不正确或荒谬的答案。
2)ChatGPT对输入短语很敏感。例如,给定一个问题的一个短语,模型可以声称不知道答案,但稍微重新措辞,可以正确回答。
3)该模型通常过于冗长,过度使用某些短语。
4)理想情况下,当用户提供不明确的查询时,模型会提出明确的问题。相反,我们当前的模型通常猜测用户的意图。
5)虽然我们努力让模型拒绝不适当的请求,但它有时会响应有害的指令或表现出有偏见的行为。
4.使用
可惜OpenAI不支持在中国使用。


















 4037
4037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









