







 PaddleSpeech是由百度开发的一站式语音工具包,旨在简化语音识别与合成任务。该工具包支持多种语言,包括中文和英文,并提供了易于使用的接口。它集成了多种先进模型,如Deepspeech2、Conformer、Transformer以及Tacotron2等,适用于语音识别和语音合成应用。
PaddleSpeech是由百度开发的一站式语音工具包,旨在简化语音识别与合成任务。该工具包支持多种语言,包括中文和英文,并提供了易于使用的接口。它集成了多种先进模型,如Deepspeech2、Conformer、Transformer以及Tacotron2等,适用于语音识别和语音合成应用。
1.简介
本文根据2022年《PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit》翻译总结。百度开发的PaddleSpeech。不知道是否有中文版,我是根据这个英文版翻译总结的。
语音识别的以前一些工具集,如Kaldi、Fairseq S2T等都太复杂,比如Kaldi还得熟悉Perl、C++。由此,我们提出了PaddleSpeech,提供命令接口和便携式方法,方便语音相关开发应用。
此外,以前中文语音识别社区较少,PaddleSpeech既支持英文又支持中文。
PaddleSpeech不仅支持语音识别还支持语音合成。支持模型如下:
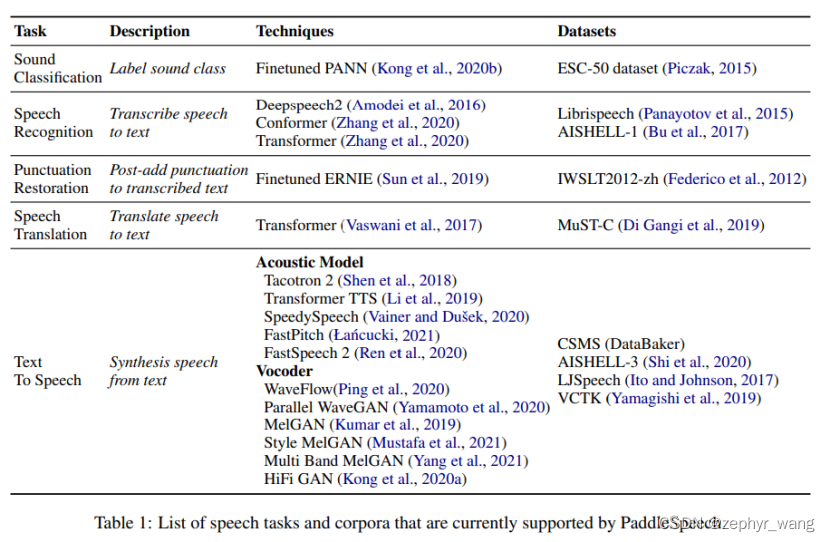
开源地址:https://github.com/PaddlePaddle/PaddleSpeech
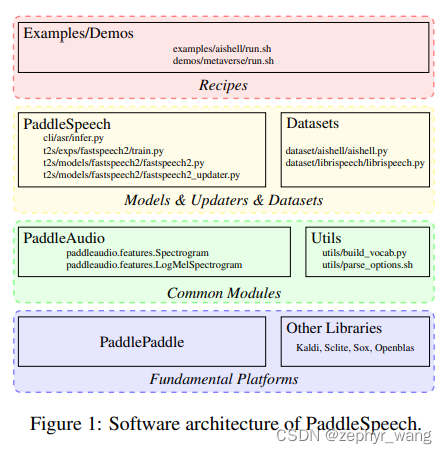
2.PaddleSpeech的设计
PaddleSpeech设计大体如下。其中模型都在method文件,对应的训练、验证在updater文件。底层基于百度的PaddlePaddle。
3.实验
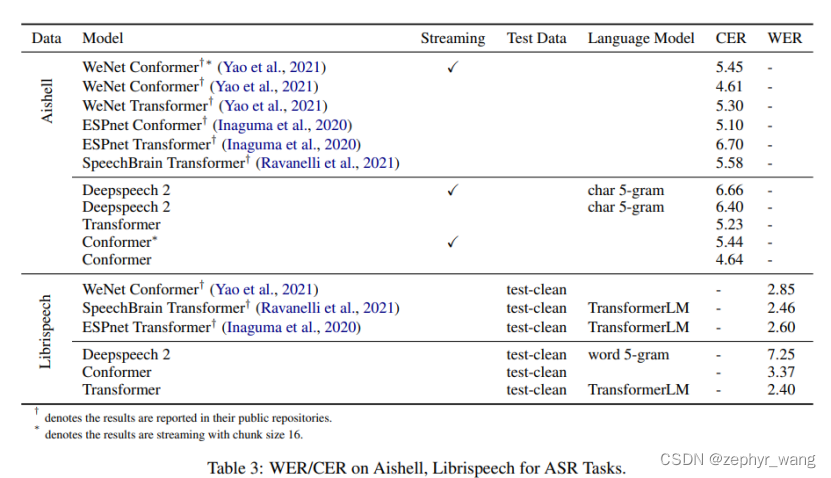
3.1.语音识别
语音识别任务效果如下,我们集成了Deepspeech 2、Conformer、Transformer模型:
3.2.语音合成
Text-To-Speech (TTS)将语音文本转换成语音。PaddleSpeech的TTS包括3步,首先将原始的文本通过 text前端模块转换成字符或者音素,然后通过声学模型,将字符或者音素转换成声学特征,例如mel spectrogram,最后,我们通过声码器(Vocoder)利用声学特征生成声波。其中 text前端模块是一个规则模型,基于专家知识。声学模型和声码器是可以训练的。
text前端模块采用的G2P,如下表格所示

声学模型主要分为自回归模型和非自回归模型。自回归模型的解码依赖上一步的预测,故而预测时间较长,但效果好;而非自回归模型可以并行输出,预测速度较快,但质量一般。
PaddleSpeech中,声学自回归模型有Tacotron 2 和Transformer TTS,非自回归模型有: SpeedySpeech, FastPitch 和FastSpeech 2。


















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









