 飞桨PaddleSpeech语音合成技术详解
飞桨PaddleSpeech语音合成技术详解





(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码)
『听』和『说』
人类通过听觉获取的信息大约占所有感知信息的 20% ~ 30%。声音存储了丰富的语义以及时序信息,由专门负责听觉的器官接收信号,产生一系列连锁刺激后,在人类大脑的皮层听区进行处理分析,获取语义和知识。近年来,随着深度学习算法上的进步以及不断丰厚的硬件资源条件,文本转语音(Text-to-Speech, TTS) 技术在移动、虚拟娱乐等领域得到了广泛的应用。
"听"书
使用 PaddleOCR 直接获取书籍上的文字。
# download demo sources
!mkdir download
!wget -P download https://paddlespeech.bj.bcebos.com/tutorial/tts/ocr_result.jpg
!wget -P download https://paddlespeech.bj.bcebos.com/tutorial/tts/ocr.wav
!wget -P download https://paddlespeech.bj.bcebos.com/tutorial/tts/tts_lips.mp4
import IPython.display as dp
from PIL import Image
img_path = 'download/ocr_result.jpg'
im = Image.open(img_path)
dp.display(im)
使用 PaddleSpeech,阅读上一步识别出来的文字。
dp.Audio("download/ocr.wav")
具体实现代码详见 Story Talker
偶像开口说话
元宇宙来袭,构造你的虚拟人! 看看 PaddleGAN 怎样合成唇形,让WiFi之母——海蒂·拉玛说话。
from IPython.display import HTML
html_str = '''
<video controls width="600" height="360" src="{}">animation</video>
'''.format("download/tts_lips.mp4")
dp.display(HTML(html_str))
具体实现代码请参考 Metaverse。
下面让我们来系统地学习语音方面的知识,看看怎样使用 PaddleSpeech 实现基本的语音功能,以及怎样结合光学字符识别(Optical Character Recognition,OCR)、自然语言处理(Natural Language Processing,NLP)等技术“听”书、让名人开口说话。
前言
背景知识
为了更好地了解文本转语音任务的要素,我们先简要地回顾一下文本转语音的发展历史。如果你对此已经有所了解,或希望能尽快使用代码实现,请直接跳至实践。
定义
文本转语音,又称语音合成(Speech Sysnthesis),指的是将一段文本按照一定需求转化成对应的音频,这种特性决定了的输出数据比输入输入长得多。文本转语音是一项包含了语义学、声学、数字信号处理以及机器学习的等多项学科的交叉任务。虽然辨识低质量音频文件的内容对人类来说很容易,但这对计算机来说并非易事。
按照不同的应用需求,更广义的语音合成研究包括:语音转换,例如说话人转换、语音到歌唱转换、语音情感转换、口音转换等;歌唱合成,例如歌词到歌唱转换、可视语音合成等。
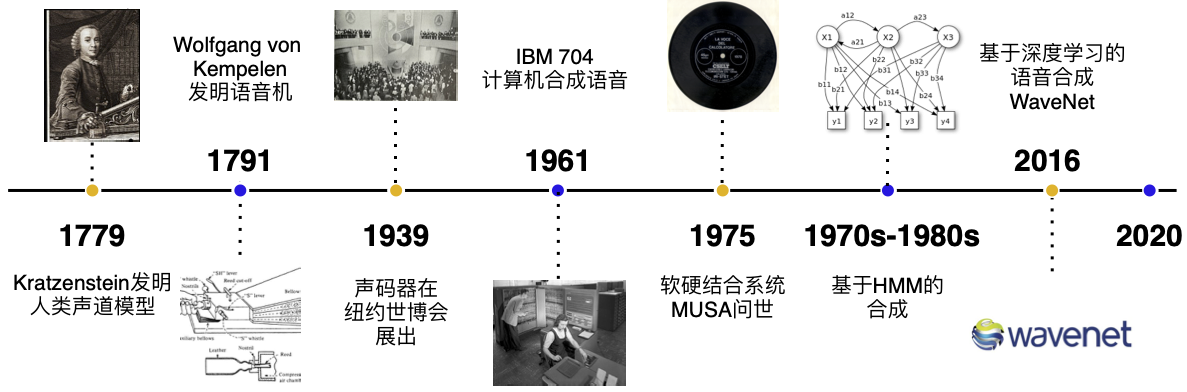
发展历史
在第二次工业革命之前,语音的合成主要以机械式的音素合成为主。1779年,德裔丹麦科学家 Christian Gottlieb Kratzenstein 建造了人类的声道模型,使其可以产生五个长元音。1791年, Wolfgang von Kempelen 添加了唇和舌的模型,使其能够发出辅音和元音。贝尔实验室于20世纪30年代发明了声码器(Vocoder),将语音自动分解为音调和共振,此项技术由 Homer Dudley 改进为键盘式合成器并于 1939年纽约世界博览会展出。
第一台基于计算机的语音合成系统起源于20世纪50年代。1961年,IBM 的 John Larry Kelly,以及 Louis Gerstman 使用 IBM 704 计算机合成语音,成为贝尔实验室最著名的成就之一。1975年,第一代语音合成系统之一 —— MUSA(MUltichannel Speaking Automation)问世,其由一个独立的硬件和配套的软件组成。1978年发行的第二个版本也可以进行无伴奏演唱。90 年代的主流是采用 MIT 和贝尔实验室的系统,并结合自然语言处理模型。
主流方法
当前的主流方法分为基于统计参数的语音合成、波形拼接语音合成、混合方法以及端到端神经网络语音合成。基于参数的语音合成包含隐马尔可夫模型(Hidden Markov Model,HMM)以及深度学习网络(Deep Neural Network,DNN)。端到端的方法保函声学模型+声码器以及“完全”端到端方法。
基于深度学习的语音合成技术
语音合成基本知识
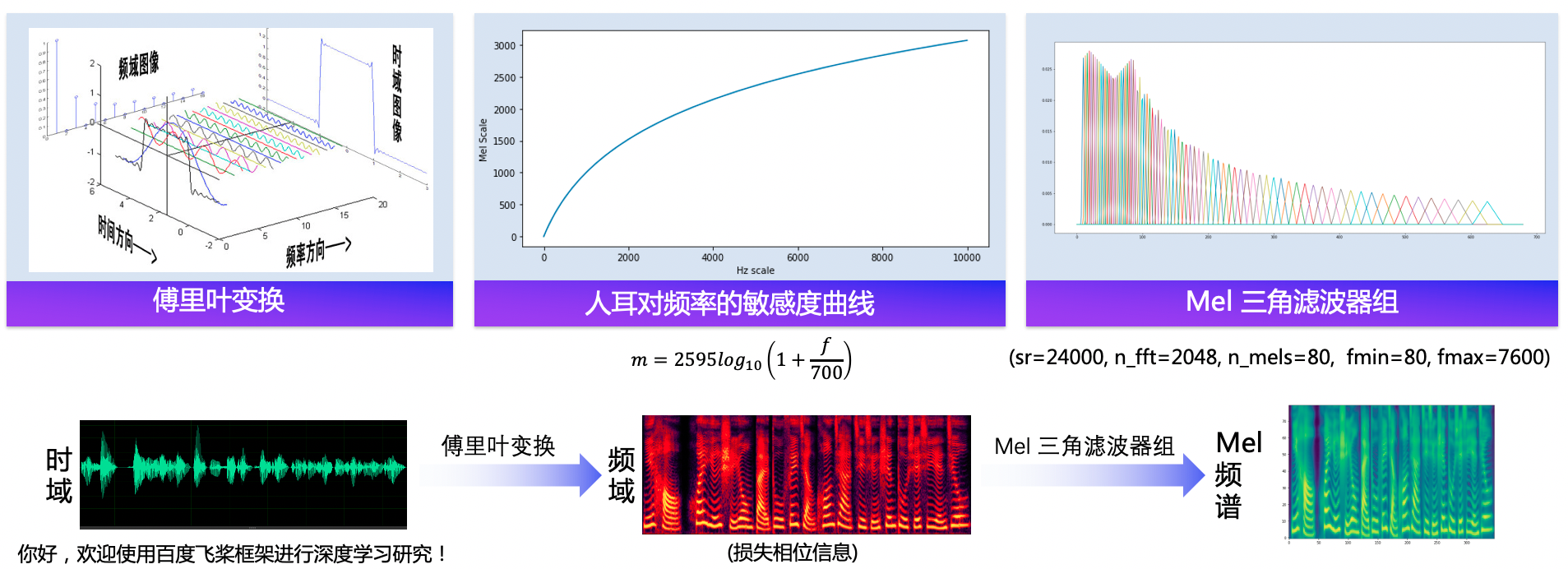
语音合成流水线包含 文本前端(Text Frontend) 、声学模型(Acoustic Model) 和 声码器(Vocoder) 三个主要模块:
- 通过文本前端模块将原始文本转换为字符/音素。
- 通过声学模型将字符/音素转换为声学特征,如线性频谱图、mel 频谱图、LPC 特征等。
- 通过声码器将声学特征转换为波形。
实践
安装 paddlespeech
!pip install paddlespeech
数据及模型准备
获取PaddlePaddle预训练模型
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_ckpt_0.4.zip
!unzip -o -d download download/pwg_baker_ckpt_0.4.zip
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_ckpt_0.4.zip
!unzip -o -d download download/fastspeech2_nosil_baker_ckpt_0.4.zip
!tree download/pwg_baker_ckpt_0.4
!tree download/fastspeech2_nosil_baker_ckpt_0.4
导入 Python 包
# 本项目的依赖需要用到 nltk 包,但是有时会因为网络原因导致不好下载,此处手动下载一下放到百度服务器的包
!wget https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
!tar zxvf nltk_data.tar.gz
# 设置 gpu 环境
%env CUDA_VISIBLE_DEVICES=0
import logging
import sys
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
import argparse
import os
from pathlib import Path
import IPython.display as dp
import matplotlib.pyplot as plt
import numpy as np
import paddle
import soundfile as sf
import yaml
from paddlespeech.t2s.frontend.zh_frontend import Frontend
from paddlespeech.t2s.models.fastspeech2 import FastSpeech2
from paddlespeech.t2s.models.fastspeech2 import FastSpeech2Inference
from paddlespeech.t2s.models.parallel_wavegan import PWGGenerator
from 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2217
2217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









