






 本文回顾了2014年的RNNEncoder-Decoder模型,它通过RNN学习可变长度序列间的概率,关注语义和句法特征,用于翻译和序列生成。模型利用GRU单元处理遗忘与更新,实验结果显示其优于依赖词频的传统模型。
本文回顾了2014年的RNNEncoder-Decoder模型,它通过RNN学习可变长度序列间的概率,关注语义和句法特征,用于翻译和序列生成。模型利用GRU单元处理遗忘与更新,实验结果显示其优于依赖词频的传统模型。
1 简介
本文跟进2014年《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》翻译总结。
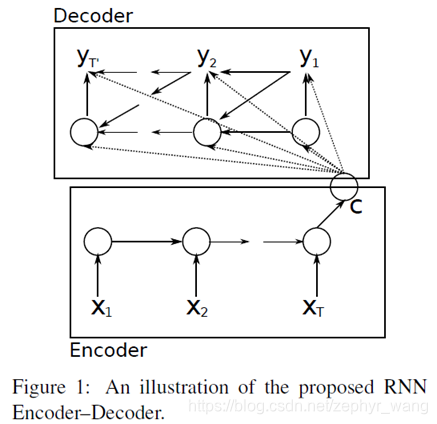
本文提出了RNN Encoder–Decoder模型。Encoder 将一个可变长度的源序列转化成一个固定长度的向量,Decoder将固定长度的向量再转化成一个可变长度的目标序列。
RNN Encoder–Decoder不像以前的模型依赖词频来预测,而是更关注语句的语义和句法特征。
2 RNN Encoder–Decoder
2.1 预备知识:Recurrent Neural Networks
一个RNN包括隐藏状态h、一个可选的输出y,可变长度输入序列x, 。
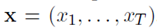
主要是下面3个公式:
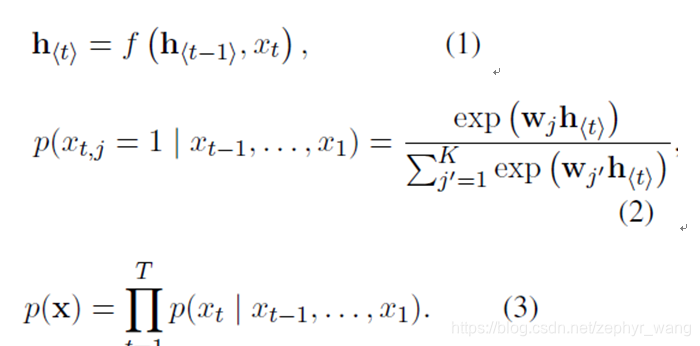
其中t表示时间步长(timestep),K个多项式分布,j=1…K。
2.2 RNN Encoder–Decoder
该模型主要学习基于一个可变长度的序列条件下另一个可变长度序列的概率,如 
。
RNN Encoder–Decoder可用于两个场景,一种方式是在给定输入序列下,生成目标序列;另一种方式是,模型可以用来对输入输出序列对进行打分排序,其中分数是下面公式3或公式4的概率p_θ (y|x).
公式如下,增加了y1…yt:
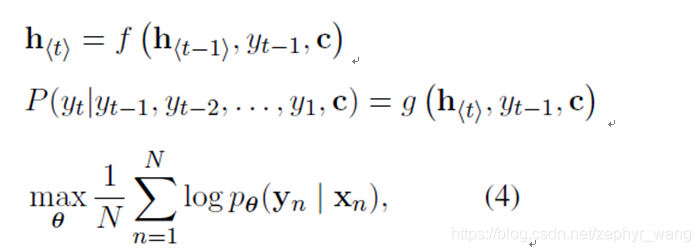
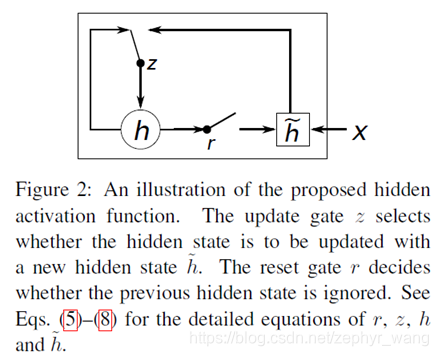
2.3 GRU(Gate Recurrent Unit)
当重置门(reset gate)r接近0时,隐藏状态将会忽略上一个隐藏状态,只是用当前的输入进行重置。这将有效的容许隐藏状态丢弃一些和未来无关的信息。捕捉短期依赖的单元更倾向于拥有更多的reset gate。
更新门(update gate)控制上一个隐藏状态的信息有多少会传递到当前隐藏状态。捕捉短期依赖的单元更倾向于拥有更多的update gate。
公式如下:
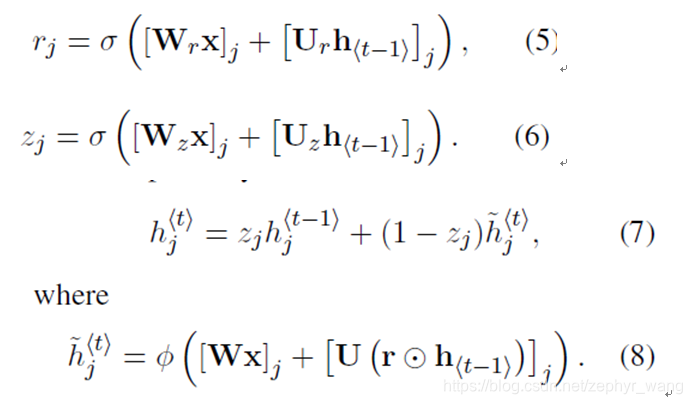
3 实验结果
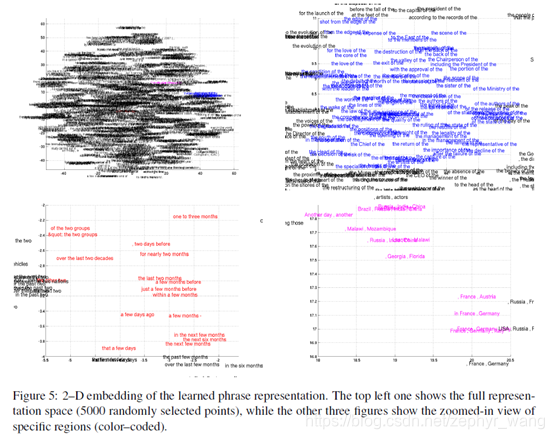
RNN Encoder–Decoder不像以前的模型依赖词频来预测,而是更关注语句的语义和句法特征。可以看到下图的几个embedding空间,红色部分,大部分短语是时间方面的,他们在句法上相似;粉色部分是语义相似的,都是国家或者区域;蓝色部分也是句法相似。


















 456
456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









