






 介绍SCKKRS自监督方法,用于提取文本中的关键词和关键短语。该方法通过双向Transformer自动生成标签,并利用双向LSTM进行训练,提高了关键词提取的准确性。
介绍SCKKRS自监督方法,用于提取文本中的关键词和关键短语。该方法通过双向Transformer自动生成标签,并利用双向LSTM进行训练,提高了关键词提取的准确性。
1 简介
SCKKRS (Self-supervised Contextual Keyword and Keyphrase Retrieval with Self-Labelling)
本文根据2019年《Self-supervised Contextual Keyword and Keyphrase Retrieval with Self-Labelling》翻译总结。
SCKKRS,通过名称可以看出来,是进行关键词、关键短语提取的。而且是自监督方法,不需要标签数据的,模型自己进行标注、提取关键词。
关键词、关键短语提取的方法有统计方法、图方法、语言学方法、机器学习方法、混合方法等。其中统计方法主要是统计频率之类的,如Rapid Automatic Keyword Extraction (RAKE)、TF-IDF;图方法采用单词表示成顶点,而边表示相似性,如PageRank、textrank等方法;语音学方法利用语音的特征,所以该方法依赖于语言,如Adjective+Noun(linear algebra)和Noun+Noun(Computer Virus.)等方法;机器学习方法有HMM, Naive Bayes, Support Vector Machine等;混合方法就是多种方法的组合,SCKKRS是这种的。
2 具体方法
如下图,是端到端的(end-to-end),即模型可以自己对没有标注的数据进行标注,减少人工操作,进行关键词提取。在self-labelling这步,是使用Bidirectional Transformers从非标注的语库中自己标注(提取)关键词、关键短语,提取的关键词embedding越和语句的embedding相近,则认为提取的关键词越好;然后再采用Bidirectional LSTM进行训练识别。
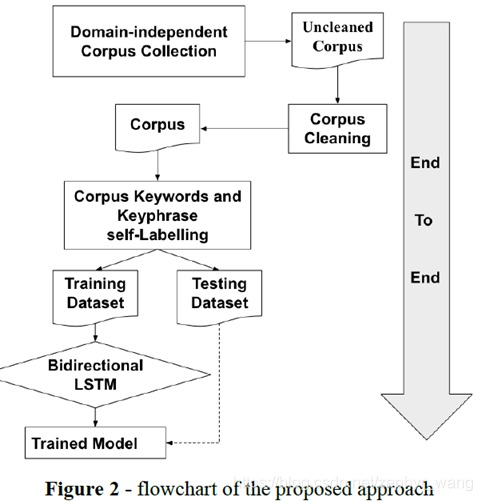
self-labelling
如下面公式所示,提取的关键词embedding越和语句的embedding相近,则认为提取的关键词越好,采用的cosine相似计算公式。

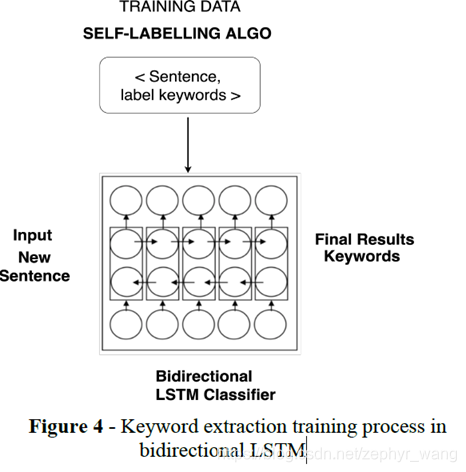
bidirectional LSTM
self-labelling获得的<sentence、label keywords>输入到bidirectional LSTM。bidirectional LSTM采用的二分类。当word是关键词时,label keywords=1;当word不是关键词时,label keywords=0.
3 实验结果
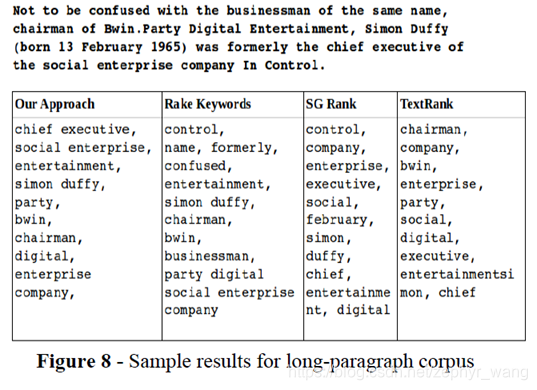
从下表可以看出来,我们提取的关键词更加准确。
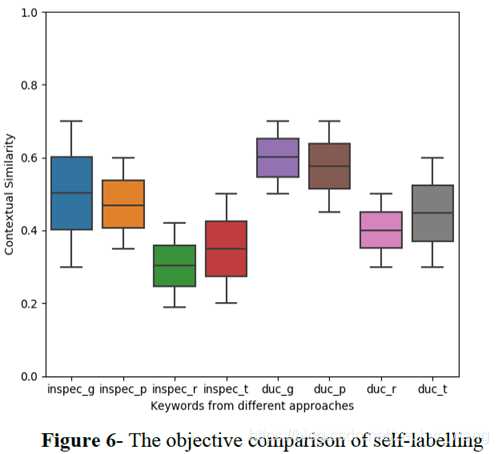
从下图可以看出来,我们提取的关键词和真实的相近。
g 表示ground truth keywords, r 表示RAKE generated keywords,t 表示TextRank generated keywords ,p 表示我们的 self-labelled keywords.

















 63
63

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









