







 本文介绍了GPT(Generative Pre-Training)模型,这是一种通过非监督预训练和监督训练微调提升语言理解能力的方法。GPT使用Transformer解码器结构,尤其适合大数据任务。在预训练阶段,多层TransformerDecoder用于自注意力和目标token概率分布的生成。在微调阶段,针对不同任务调整输入格式,如Textual Entailment任务、Similarity任务、Multiple-choice任务和Classification任务。实验结果显示,模型层数增加能提高性能。GPT在NLI、问答与常识推理、分类和语义相似任务上表现出色。
本文介绍了GPT(Generative Pre-Training)模型,这是一种通过非监督预训练和监督训练微调提升语言理解能力的方法。GPT使用Transformer解码器结构,尤其适合大数据任务。在预训练阶段,多层TransformerDecoder用于自注意力和目标token概率分布的生成。在微调阶段,针对不同任务调整输入格式,如Textual Entailment任务、Similarity任务、Multiple-choice任务和Classification任务。实验结果显示,模型层数增加能提高性能。GPT在NLI、问答与常识推理、分类和语义相似任务上表现出色。
1 简介
GPT:Generative Pre-Training。
本文根据《Improving Language Understanding by Generative Pre-Training》翻译总结。
GPT:一种半监督方法,首先是非监督的预训练,然后进行监督训练微调。像LSTM结构的模型也使用预训练进行了提升,但是因为LSTM限制其预测能力。
GPT采用的transformer decoder 结构。
监督训练微调,对于大部分任务只需要微调3 epoch就可以了。
GPT更适合大数据的任务识别,尤其是增加的辅助目标函数L3。
2 框架
2.1 非监督预训练
采用的多层transformer decoder。首先在输入context token上使用多头自注意力,然后使用位置敏感的feedforwrd层输出目标token的概率分布。

2.2 监督训练微调

2.3 不同任务的输入转换
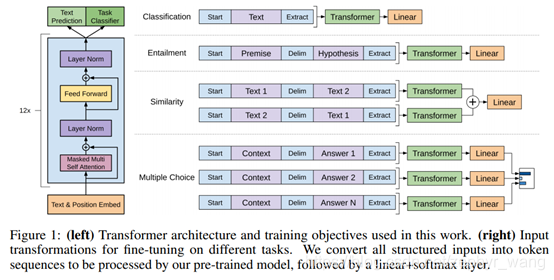
我们主要是修改不同任务的输入格式,来适配不同的任务,对于大部分任务只需要微调3 epoch就可以了。如下图:
比如Textual entailment任务:判断一组句子是矛盾的还是中立的。我们将premise和hypothesis结合在一起,中间增加了界定符(delim)$.
Similarity任务:将text1和text2以及互换的text2和text1分别输入transformer。
Multiple choice任务:格式[z; q; $; α_k]。Z表示document,q表示question,α表示各种可能的answer。
Classification任务:不用变,就是2.2节的。
3 实验结果
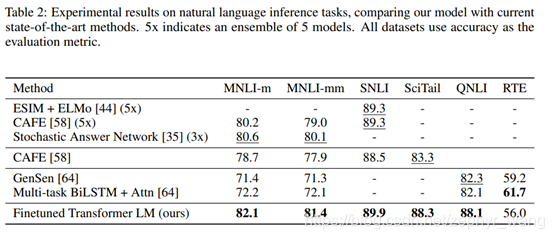
textual entailment任务(natural language inference (NLI))结果如下:
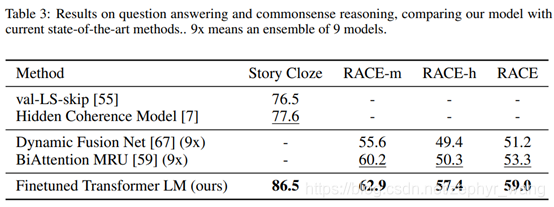
Question answering and commonsense reasoning问答与常识推理:
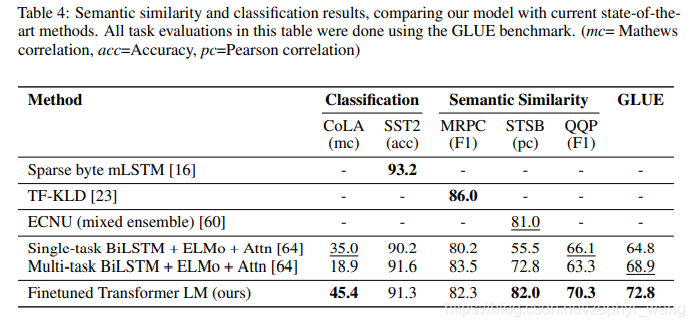
分类和语义相似任务:
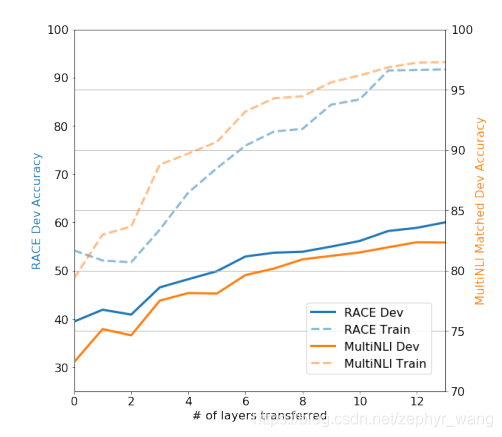
4 层数的影响
可以看到encoder层数越大越好,如下图。

















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









