







 本文探讨了在机器翻译中优化汉字分割的重要性。研究发现,使用基于特征的方法如支持向量机和条件随机场(CRF)进行汉字分割能提高翻译质量,尤其是结合词典和专业名词处理。CRF+词典+专业名词的模型表现最佳。同时,分析表明,字符分割和单纯词语分割可能不如中间粒度分割有效,因为它们无法捕捉到上下文含义和处理OOV词语。通过引入条件熵,可以评估不同分割方法的一致性,并优化平均token长度。专有名词的处理对翻译效果有积极影响。
本文探讨了在机器翻译中优化汉字分割的重要性。研究发现,使用基于特征的方法如支持向量机和条件随机场(CRF)进行汉字分割能提高翻译质量,尤其是结合词典和专业名词处理。CRF+词典+专业名词的模型表现最佳。同时,分析表明,字符分割和单纯词语分割可能不如中间粒度分割有效,因为它们无法捕捉到上下文含义和处理OOV词语。通过引入条件熵,可以评估不同分割方法的一致性,并优化平均token长度。专有名词的处理对翻译效果有积极影响。
1 简介
本文主要讲机器翻译时如何更好的进行汉字分割。本文参考2008年《Optimizing Chinese Word Segmentation for Machine Translation Performance》翻译总结。
基于基本的机器翻译结果分析,我们发现下面文字分割有利于机器翻译:
1)基于特征的分割,比如支持向量机、条件随机场(CRF),有非常好的表现。主要是其一致性。而上下文分割方法可能存在不一致性。单纯的字符分割(即每个汉字当作一个词),或者标准的词语分割对于机器翻译都不是最佳的,可以使用它们之间的中间分割粒度,比如CRF。
2)基于特征分割的优势是它们可以处理out-of-vocabulary (OOV) 词语,但这有可能伤害MT(Machine Translation)表现,因为这些OOV词语会被分割成子部分,然后这些子部分组合起来表达完整的意思。比如专有名词不适合被分割。
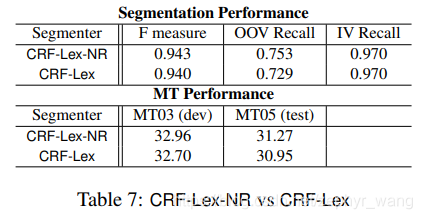
CRF再加上基于词典的分割,就会取得更好的结果。
CRF+基于词典+基于专业名称,效果最佳。
2 理解汉语分割
2.1 假说1
CharBased:字符分割,每个汉字当作一个词。
MaxMatch: 一种简单的词语分割方法,将词语在字典中贪婪的匹配,找到最长的词语。
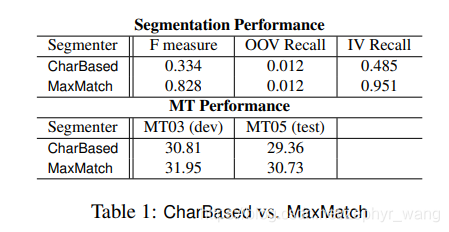
发现:基于字符分割的MT效果比基于词语分割的效果差。如下表。
原因:(1)基于词典,可以识别一个汉字在不同上下文中的意思,比如智利和失智症,其中的“智”;(2)将词语作为一个整体,有利于重排序的模型。
2.2 假说2
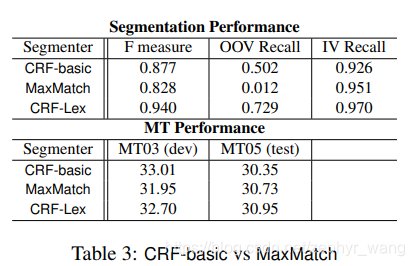
发现:更好的分割并不一定有利于MT效果,在下一节引入了conditional entropy。如下表的CRF-basic在Segmentation Performance上分数高于MaxMatch,但在MT05上的 MT Performance差于MaxMatch。
CRF-Lex:CRF-basic 加上外部词典。
CFR-basic模型看来要单独写篇文章写下,公式如下:

2.3 不同分割的一致性分析
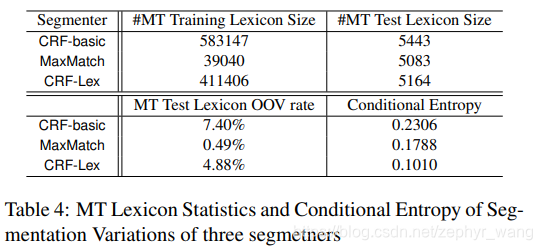
引入了conditional entropy来判断,如下表,CRF-basic与MaxMatch相比conditional entropy是递减的,比F measure评估有效。
conditional entropy公式:

2.4 优化平均token长度



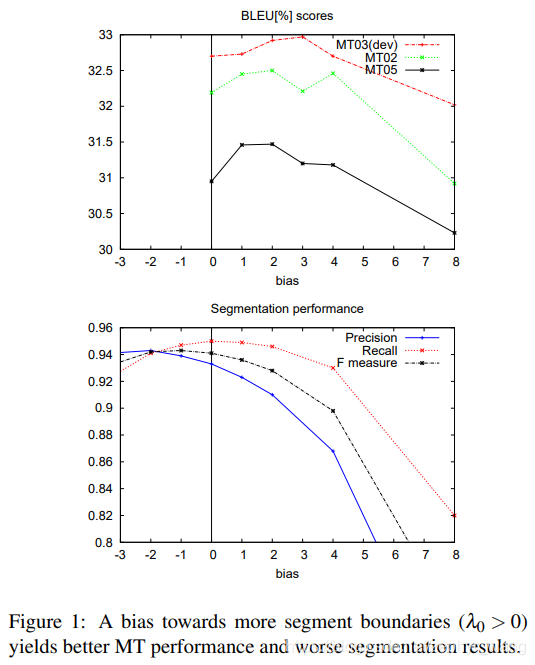
2.5 引入专有名词
proper noun(NR):专有名词(人、地、机构等的名称)。
可以看到带有NR的模型更好。

















 2514
2514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









