







 本文介绍了FacebookAIResearch的XLMs模型,它在跨语言学习上取得重大进展。XLMs包括三种语言模型:CLM(因果语言模型)、MLM(遮蔽语言模型)和TLM(翻译语言模型)。TLM尤其创新,通过并行语句进行预训练,提升模型的跨语言理解能力。实验结果显示,XLMs在跨语言分类、机器翻译和低资源语言建模上表现出色。
本文介绍了FacebookAIResearch的XLMs模型,它在跨语言学习上取得重大进展。XLMs包括三种语言模型:CLM(因果语言模型)、MLM(遮蔽语言模型)和TLM(翻译语言模型)。TLM尤其创新,通过并行语句进行预训练,提升模型的跨语言理解能力。实验结果显示,XLMs在跨语言分类、机器翻译和低资源语言建模上表现出色。
1 简介
跨语言模型XLMs。本文根据2019年Facebook AI Research的《Cross-lingual Language Model Pretraining》翻译总结。
XLMs有如下贡献:
1) 我们介绍了一个新的非监督方法,可以使用跨语言模型学习跨语言表述(TLM),同时研究了两个单语言的预训练,CLM和MLM。
2) 当并行数据(双语数据)可以获得时,我们引入了一个监督学习,来改善跨语言预训练。
3) 我们在跨语言分类、非监督机器翻译、监督机器翻译方面,显著超过了以前的优秀模型。
4) 跨语言模型可以显著改善低资源语言的困惑度perplexity。(低资源语言由于缺乏足够的标注数据及相关的专家知识,使得传统的基于大词汇量语音识别系统的关键词检测技术无法使用.)(perplexity是自然语言处理领域NLP中,衡量语言模型好坏的指标。它主要是根据每个词来估计一句话出现的概率,并用句子长度作normalize)。
2 Cross-lingual language models
我们将描述3个语言模型。其中两个仅需要单语言数据(非监督学习),CLM和MLM;第3个模型需要并行语句-双语数据(监督学习),TLM。
2.1 Shared sub-word vocabulary
参考文章:https://blog.youkuaiyun.com/sinat_25394043/article/details/104190431
通常在英文NLP任务中,tokenization(分词)往往以空格为划分方式,但这种传统的分词方法还是存在一些问题,如:
• 传统词表示方法无法很好的处理未知或罕见的词汇(OOV问题)
• 传统词tokenization方法不利于模型学习词缀之间的关系
• E.g. 模型学到的“old”, “older”, and “oldest”之间的关系无法泛化到“smart”, “smarter”, and “smartest”。
• Character embedding作为OOV的解决方法粒度太细
• Subword粒度在词与字符之间,能够较好的平衡OOV问题
针对这些缺点,越来越多人开始使用subword的相关tokenization方法,具体方法主要有BPE,WordPiece等。
XLMs应该是先tokenizer,再BPE。
BPE,(byte pair encoder)字节对编码,也可以叫做digram coding双字母组合编码,主要目的是为了数据压缩,算法描述为字符串里频率最常见的一对字符被一个没有在这个字符中出现的字符代替的层层迭代过程。具体在下面描述。该算法首先被提出是在Philip Gage的C Users Journal的 1994年2月的文章“A New Algorithm for Data Compression”。
在XLMs所有的实验中,我们使用Byte Pair Encoding (BPE)创建的共享的词汇表。当跨语言间共享相同的字母表、数字、专有名称时,BPE会显著改善跨语言embedding空间的对齐,
我们通过在单语言库中随机采样的语句的级联来学习BPE分割。语句是通过一个概率的多项式分布采样的,其中每个概率q公式如下:
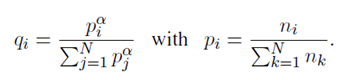
比如在α=0.5时,采样会增加低资源语言的token数量,而减轻向高资源语言的偏差。实际上,这防止了低资源语言被分割到字符级水平。
2.2 Causal Language Modeling (CLM)
非监督学习、单语言。
CLM采用Transformer,预测给定前面单词情况下预测下一个单词的概率。
2.3 Masked Language Modeling (MLM)
非监督学习、单语言。
将BPE tokens的15%随机替换掉,其中80%采用[MASK]替换,10%采用一个随机的token,10%保持不变。
2.4 Translation Language Modeling (TLM)
TLM是MLM的扩展,将单语文本流替换成concatenate的并行语句。在源语句和目标语句都采用随机mask。比如英语-法语翻译,为了预测一个英语语句中被mask的单词,模型会既利用已有的英语单词,也会利用输入的法语(尤其是当英语上下文不足时)。模型会尝试对齐英语和法语的表述。
MLM和TLM模型如下图:
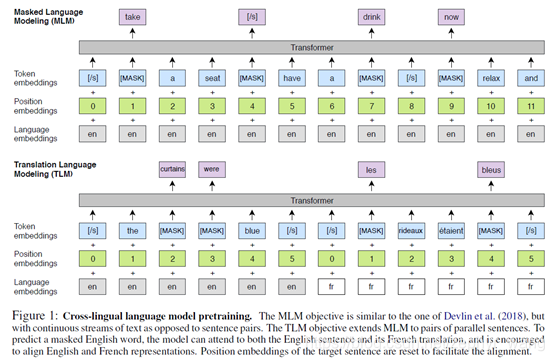
3 实验结果
对于汉语、日语、泰语,我们分别使用的tokenizer of Chang et al. (2008)、the Kytea4 tokenizer,
and the PyThaiNLP5 tokenizer。其他语言使用的the tokenizer provided by Moses (Koehn et al., 2007),当必要时,会使用默认的English tokenizer。
然后使用fastBPE(https://github.com/glample/fastBPE)学习BPE,分割单词到subword 单元。
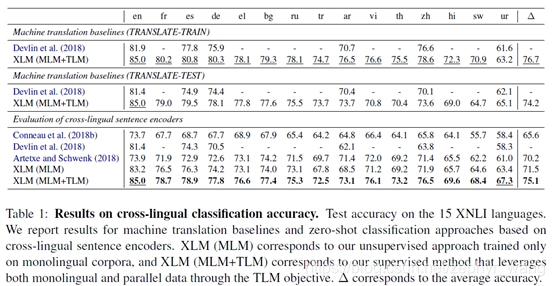
3.1 Cross-lingual classification
在预训练的Transformer的第一个隐藏单元的顶部,增加一个线性分类器,然后微调所有参数。
实验结果如下,可以看到XLM成绩最优。
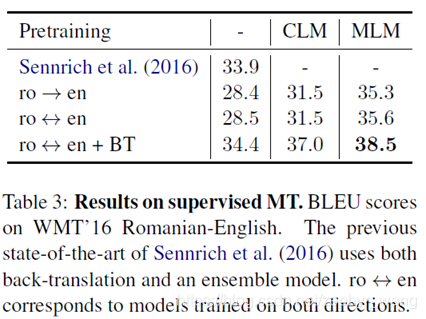
3.2 Supervised machine translation
BT:back translation,反译。
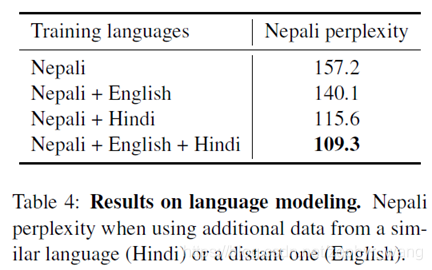
3.3 Low-resource language model
Nepali:尼泊尔语,Hindi:印地语。
不同语言间可能有些类似的锚定点(n-grams anchor points),所以跨语言模型可以利用英语、印地语的这些,来改善尼泊尔语。实验结果如下:

















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









