







1、原始数据分析
# 原始散点图显示
def show():
xcord0 = []; ycord0 = []; xcord1 = []; ycord1 = []
fr = open('testSet.txt')
for line in fr.readlines():
# 分析数据集的特点,将每行数据的每列提取出来
lineSplit = line.strip().split('\t')
xPt = float(lineSplit[0])
yPt = float(lineSplit[1])
label = int(lineSplit[2])
# 对不同标签的数据进行区分
if (label == 1):
xcord0.append(xPt)
ycord0.append(yPt)
else:
xcord1.append(xPt)
ycord1.append(yPt)
fr.close()
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord0, ycord0, marker='s', s=90)
ax.scatter(xcord1, ycord1, marker='o', s=50, c='red')
plt.show()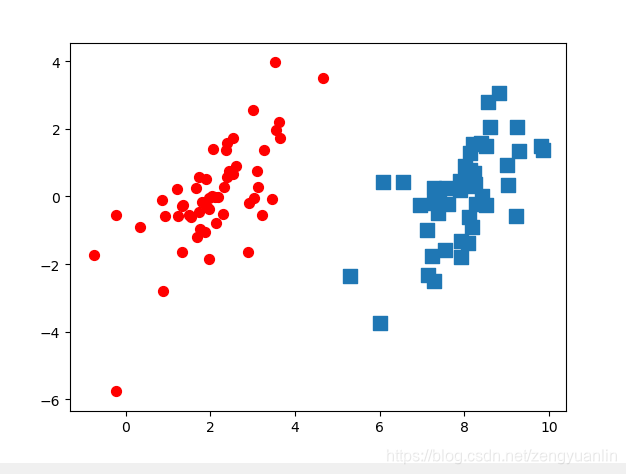
2、SMO算法(Sequential Minimal Optimization)
# 优化的SMO算法
def innerL(i, oS):
# 步骤1:计算误差Ei
Ei = calcEk(oS, i)
# 优化alpha,设定一定的容错率。
if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or (
(oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
# 使用内循环启发方式2选择alpha_j,并计算Ej
j, Ej = selectJ(i, oS, Ei)
# 保存更新前的aplpha值,使用深拷贝
alphaIold = oS.alphas[i].copy();
alphaJold = oS.alphas[j].copy();
# 步骤2:计算上下界L和H
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L == H:
print("L==H")
return 0
# 步骤3:计算eta
eta = 2.0 * oS.X[i, :] * oS.X[j, :].T - oS.X[i, :] * oS.X[i, :].T - oS.X[j, :] * oS.X[j, :].T
if eta >= 0:
print("eta>=0")
return 0
# 步骤4:更新alpha_j
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej) / eta
# 步骤5:修剪alpha_j
oS.alphas[j] = clipAlpha(oS.alphas[j], H, L)
# 更新Ej至误差缓存
updateEk(oS, j)
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
print("alpha_j变化太小")
return 0
# 步骤6:更新alpha_i
oS.alphas[i] += oS.labelMat[j] * oS.labelMat[i] * (alphaJold - oS.alphas[j])
# 更新Ei至误差缓存
updateEk(oS, i)
# 步骤7:更新b_1和b_2
b1 = oS.b - Ei - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[i, :].T - oS.labelMat[j] * (
oS.alphas[j] - alphaJold) * oS.X[i, :] * oS.X[j, :].T
b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[j, :].T - oS.labelMat[j] * (
oS.alphas[j] - alphaJold) * oS.X[j, :] * oS.X[j, :].T
# 步骤8:根据b_1和b_2更新b
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):
oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]):
oS.b = b2
else:
oS.b = (b1 + b2) / 2.0
return 1
else:
return 0
# 完整的线性SMO算法
def smoP(dataMatIn, classLabels, C, toler, maxIter):
oS = optStruct(np.mat(dataMatIn), np.mat(classLabels).transpose(), C, toler) # 初始化数据结构
iter = 0 # 初始化当前迭代次数
entireSet = True;
alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)): # 遍历整个数据集都alpha也没有更新或者超过最大迭代次数,则退出循环
alphaPairsChanged = 0
if entireSet: # 遍历整个数据集
for i in range(oS.m):
alphaPairsChanged += innerL(i, oS) # 使用优化的SMO算法
print("全样本遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter, i, alphaPairsChanged))
iter += 1
else: # 遍历非边界值
nonBoundIs = np.nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0] # 遍历不在边界0和C的alpha
for i in nonBoundIs:
alphaPairsChanged += innerL(i, oS)
print("非边界遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter, i, alphaPairsChanged))
iter += 1
if entireSet: # 遍历一次后改为非边界遍历
entireSet = False
elif (alphaPairsChanged == 0): # 如果alpha没有更新,计算全样本遍历
entireSet = True
print("迭代次数: %d" % iter)
return oS.b, oS.alphas # 返回SMO算法计算的b和alphas


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









