







目录
1、压缩过程——categoryIdList转换为categoryIdBitSet
2、解析过程——判断文档的categoryId记录是否落在bitset中
背景
电商平台按照单位区分可以搜索的采购品类,还有对应的入驻供应商。平台需求是控制客户只能查看允许采购的商品品类,还有只能查看入驻供应商的商品。但每个单位配置的品类和入驻供应商成千上万,直接传输的话,无论传输速度还是解析速度慢,因此需要对参数进行压缩。
原理
使用BitSet的方法对参数进行压缩。业务上是只需要判断CategoryId是否存在,不需要理会具体的值,因此可以以0,1判断此值是否存在。
计算机存储时:
int 占 32位,1000个int,就要有1000个32位的存储;
如果直接用位数存储,判断1000个int是否存在,直接用对应的位存储,就只需要1000个位,比原本1000个32位少了很多。
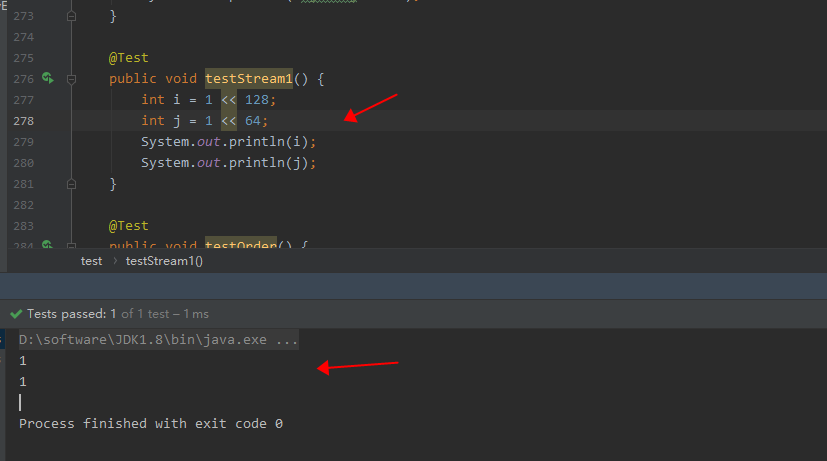
java里面的BitSet压缩是按照64位压缩的,以long型的存储大小为准。因为java里面,int位数限制的缘故,1<<128和1<<64(此类的1<<n = 1<<(n+64))得到都是相同的结果,都是1(java位运算结果使用int接收的),因此以 一个“64个二进制位” 为BitSet里面的一个元素,其中位数置为1或0表示categoryId是否存在。
上述做法既可以表示一个categoryId是否存在,又可以简化代码编写。(注意同样的操作在python是不适用的!python已经帮忙封装好了,1<<128和1<<64是不一样的结果,64位是JDK默认的设置);
JAVA
Python
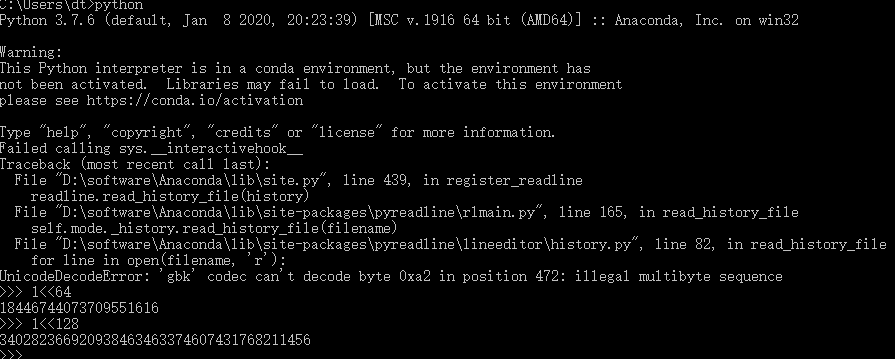
综上,在JAVA中,用BitSet来压缩判断categoryId是否存在,能够直接将数据压缩64倍;
案例
入参是:约1500个CategoryId的列表,如
[1,2,3,7,10,500,......10067]初始化的BitSet是全0的:
[000000000000...000,
000000000000...000
...
000000000000...000]即将要生成的BitSet类似于:
[101010101001...001,
000001100011....100,
101010010010....001,
...
000001100011....100]单个元素的位数 = 64
BitSet总长度 = Max(categoryIdList) / 64 + 1(也即向上取整)
元素中标识1的表示此位置有Id,
如第一个元素:
101010101001...001
(63->...)
表示 63,61,59,57,55,52,......,0 这些categoryId是存在于上传的列表中的;
第二个元素:
000001100011....100
(127->...)
表示64+index的元素122,121,117,116,......,66这些categoryId是存在于上传的列表中的;
计算流程
1、压缩过程——categoryIdList转换为categoryIdBitSet
private final static int ADDRESS_BITS_PER_WORD = 6;
/**
* Sets the bit at the specified index to {@code true}.
*
* @param bitIndex a bit index
* @throws IndexOutOfBoundsException if the specified index is negative
* @since JDK1.0
*/
public void set(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
int wordIndex = wordIndex(bitIndex);
expandTo(wordIndex);
words[wordIndex] |= (1L << bitIndex); // Restores invariants
checkInvariants();
}
/**
* Given a bit index, return word index containing it.
*/
private static int wordIndex(int bitIndex) {
return bitIndex >> ADDRESS_BITS_PER_WORD;
}解析:
wordIndex:categoryId>>6,先将category压缩在 Max(categoryId)/64 个格子范围里面,也即BitSet中第几个元素(0-base的index);
words[wordIndex] |= (1L << bitIndex):拆分成
(1)res = 1L<<bitIndex 和
(2)words[wordIndex] | res
(1)结合前述,1<< n 和 1<< (n+64)是同一个结果,因此此式可理解为,在bitset的第wordIndex个元素中,第n位的值是存在的;
(2)或运算,表示原本有值我们就还是保持原本的1;原本无值,此时我们将对应位从0变为1;
2、解析过程——判断文档的categoryId记录是否落在bitset中
int category_id =(int)doc['category_id'].value;
int index_1 = category_id>>>6;
if(index_1>=params.categoryIds.length) {
return -100000;
}
if(((params.categoryIds[index_1]>>>(category_id & 63))&1)==0){
return -100000;
}行1:获取文档中的categoryId值;
行2:同前述压缩过程中,判断此categoryId是落在bitset的第几个元素;
行3-5:如果长度超出了范围,说明此文档中的categoryId铁定不在我们输入的列表中,直接返回(-10000是用来做业务算分的,表示分值很低,当做是false就行);
行6-8:重点介绍
一个大前提,我们要判断的是,文档条目的categoryId是否落在bitset某个元素的某一位;
某个元素可以用category_id/64向下取整来获得。某一位,压缩的时候是1左移了传入的category_id除以64后的余数位(同样是因为Java里面 1<<n = 1<< (n+64))
(1)category_id & 63:其实就是相当于取category_id除以64的余数;
(2)params.categoryIds[index_1]:取bitset中,这个category_id可能存在的元素;
(3) (2)的结果 >>> (1)的结果,判断位数从右往左数,获取第 余数 个位置的结果;
(4)(3)结果与1的位运算,如果结果是1,表示此值存在需要筛选的列表,如果结果是0,表示值不存在。
解析的步骤都需要结合压缩步骤进行理解;
脚本案例——解析es 打印出来的 bitset
(java自动将二进制数转成了long型)
/**
* 输入一个字符串的列表(因为这个是展示到es dsl里面的脚本,用这种格式传入的时候复制粘贴更简洁)
* @param bitSetList
* @return
*/
public List<Integer> parseBitSetToIntList(List<String> bitSetList) {
Integer maxLen = 64;
List<Integer> resList = this.newList();
for (int index = 0; index < bitSetList.size(); index++) {
Long input = Long.valueOf(bitSetList.get(index));
int start = maxLen * index;
String binarySimple = Long.toBinaryString(input);
// 补齐到64位
int binStrLen = binarySimple.length();
int lackZero = maxLen - binStrLen;
StringBuilder zeroStringBuilder = new StringBuilder();
for (int i = 0; i < lackZero; i++) {
zeroStringBuilder.append("0");
}
zeroStringBuilder.append(binarySimple);
String binString = zeroStringBuilder.toString();
// 解析
for (int i = 0; i < maxLen; i++) {
char c = binString.charAt(i);
if (Objects.equals(c, '1')) {
resList.add(start + 63 - i);
}
}
}
return resList;
}
/**
* 生成新泛型列表
* @param t
* @param <T>
* @return
*/
private <T> List<T> newList(T... t) {
List<T> ll = new ArrayList<>();
for (int i = 0; i < t.length; i++) {
ll.add(t[i]);
}
return ll;
}
public static void main(String[] args) {
someImpl some = new someImpl();
String[] m = new String[]{"-1152918206071963648","10466113745846340","0","4037776047994822400","351843720888321","0","-67556055994990592","4095","-128","-72057594037927937","-8070450532382146561","140737488355327","384","0","0","0","0","0","0","0","0","422212465065984","-16","-1","-1","-565201754310819841","-1","-1","-1","-1","-1","-1","-1","9223372036854775807","-1","-1","-1","-1","536870911","0"};
List<String> inputList = some.newList(m);
List<Integer> resList = some.parseBitSetToIntList(inputList);
System.out.println(resList);
}
















 1284
1284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









