







在Lattice-BiLSTM,或者LeBert等等进行中文命名实体识别的模型中,需要用到词汇信息。特别的,需要知道以某个词语开头的所有词语,是否在一个预训练的词表、词向量库中出现。因此,查找词语变得非常重要。
依托于LEBert的中文平坦NER识别项目(本博客的【Transformers-实践3】),这里将其中用到的数据结构Trie树的python实现学习一下。
1. 数据背景
数据集语料以及标注为json文件,内部的格式具体如下,已经将句子切分为字(character),以及对应的各个label。
{"text": ["上", "海", "浦", "东", "开", "发", "与", "法", "制", "建", "设", "同", "步"], "label": ["B-GPE", "I-GPE", "B-GPE", "I-GPE", "O", "O", "O", "O", "O", "O", "O", "O", "O"]}
{"text": ["新", "华", "社", "上", "海", "二", "月", "十", "日", "电", "(", "记", "者", "谢", "金", "虎", "、", "张", "持", "坚", ")"], "label": ["B-ORG", "I-ORG", "I-ORG", "B-GPE", "I-GPE", "O", "O", "O", "O", "O", "O", "O", "O", "B-PER", "I-PER", "I-PER", "O", "B-PER", "I-PER", "I-PER", "O"]}
此外,我们使用一个词表,具体信息请见【Transfoemers-实践3】一文中的头部链接。这里我们就简单展示一下内容格式,除了第一行标注了数据集的元信息,其后都是词语和词向量。其第一个元素是词语,包括标点符号,随后是100或者200维的预训练向量。
第一行元信息为:2000000 200。


我们需要对词表构建Trie树,以确定语料中的所有词语。
从查找的角度,我们可以想到几个常见的数据结构:
- 哈希表
- 排序的线性表,可以二分查找;
- Trie树
Trie树和其它结构,例如哈希表比起来,其存储空间更小,并且具备较为快速的查找好处。
2.原理简介
Trie树其实结构上很简单,之前学c语言的时候,大家估计也都写过。这里简单回顾一下。
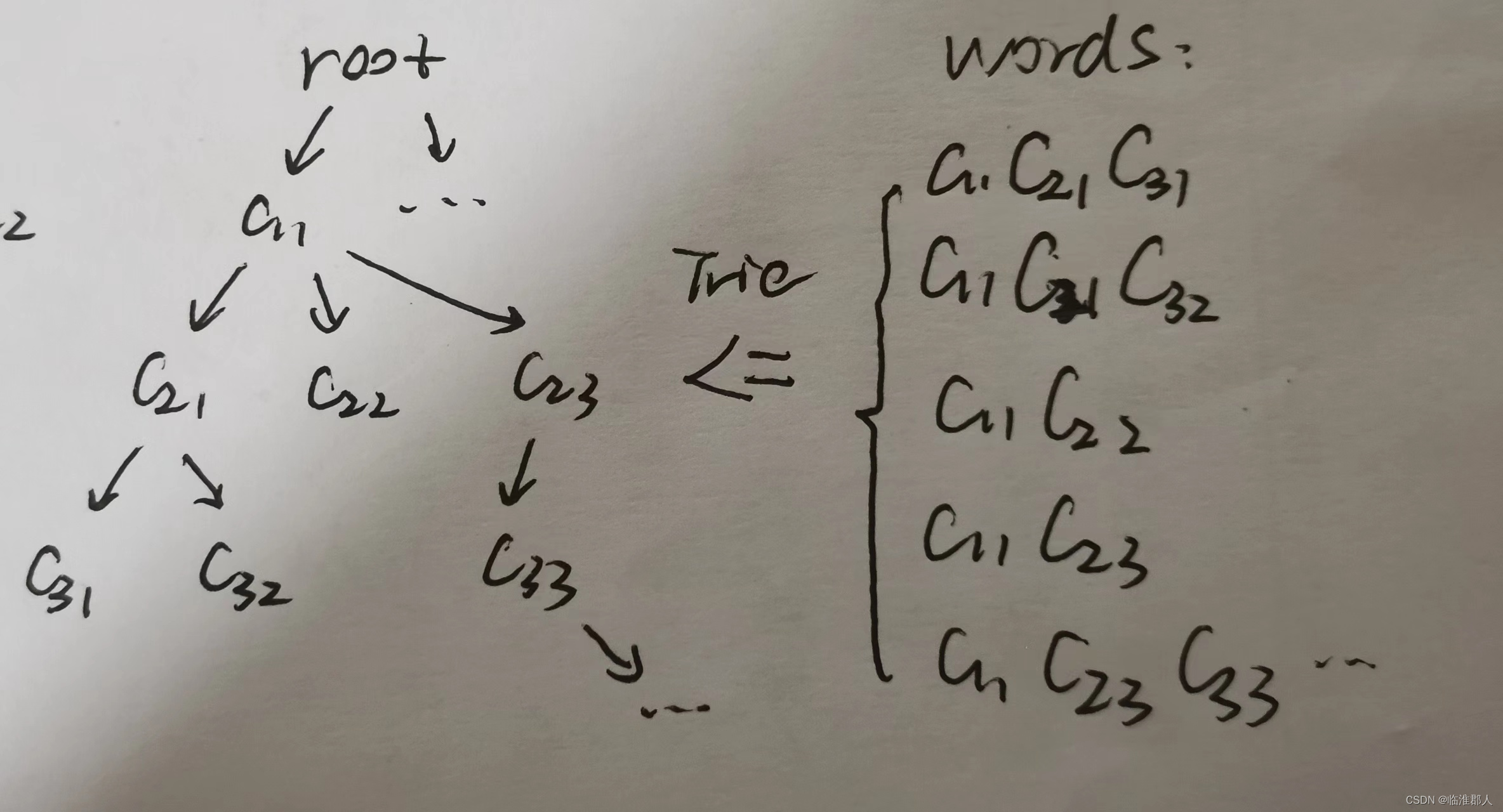
其中word中的
c
i
j
c_{ij}
cij表示词语中的字符。一般Trie树的头部
r
o
o
t
root
root是一个空节点,不包含任何字符。
一般结构如下所示:

3.具体实现
Python没有指针,但是直接使用字典或者列表就行。这里我们不需要额外储存词语,直接使用字典,其键值对为:char:TreeNode就行,就避免储存一个字符列表,一个节点列表,还要查找的繁处了。
其插入操作见insert操作,查找操作见search。其中collections.defaultdict是比较好的工具,使得我们在键不存在的时候能够获取默认值。
考虑到本模型需要查找以某个字符开头的所有词语,因此增加了一个enumerateMatch功能;当然一般的Trie树并不需要这个功能。
import collections
class TrieNode:
def __init__(self):
self.children = collections.defaultdict(TrieNode)
self.is_word = False
class Trie:
"""
In fact, this Trie is a letter tree.
root is a fake node, its function is only the begin of a word, same as <bow>
the first layer is all the word's possible first letter, for example, '中国'
its first letter is '中'
the second the layer is all the word's possible second letter.
and so on
"""
def __init__(self, use_single=True):
self.root = TrieNode()
self.max_depth = 0
if use_single:
self.min_len = 0
else:
self.min_len = 1
def insert(self, word):
current = self.root
deep = 0
for letter in word:
current = current.children[letter] #如果letter不存在于键中,那么返回默认值,这里的默认值是TrieNode。
deep += 1
current.is_word = True
if deep > self.max_depth:
self.max_depth = deep
def search(self, word):
current = self.root
for letter in word:
current = current.children.get(letter)
if current is None:
return False
return current.is_word
def enumerateMatch(self, str, space=""):
"""
Args:
str: 需要匹配的词
Return:
返回匹配的词, 如果存在多字词,则会筛去单字词
"""
matched = []
while len(str) > self.min_len:
if self.search(str):
matched.insert(0, space.join(str[:])) # 短的词总是在最前面
del str[-1]
if len(matched) > 1 and len(matched[0]) == 1: # filter single character word
matched = matched[1:]
return matched

















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









