







数仓管理
HENGSHI 3.0 中添加了数仓管理,支持开放衡石系统内部的数仓功能,让客户复用衡石的数据集成能力。
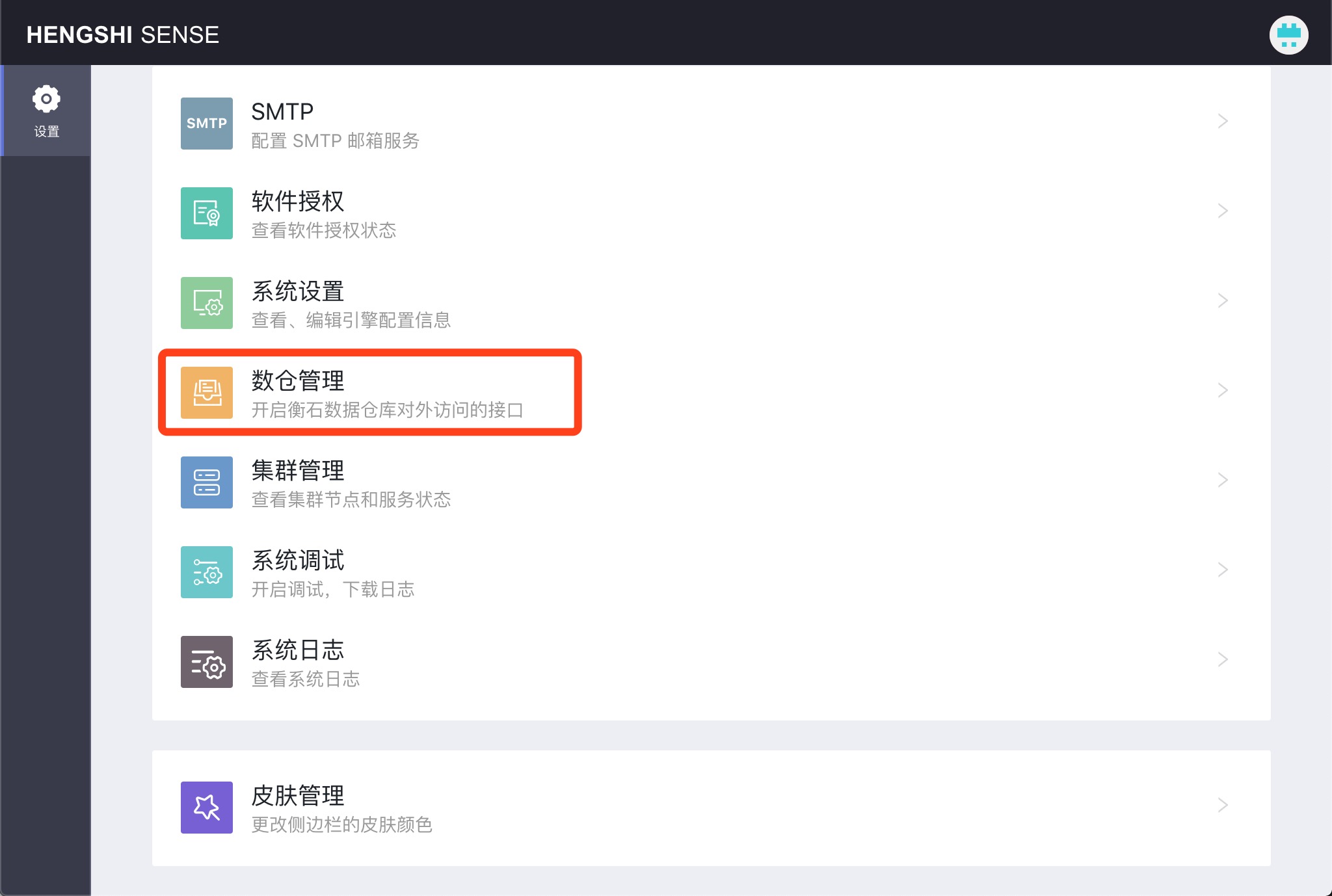
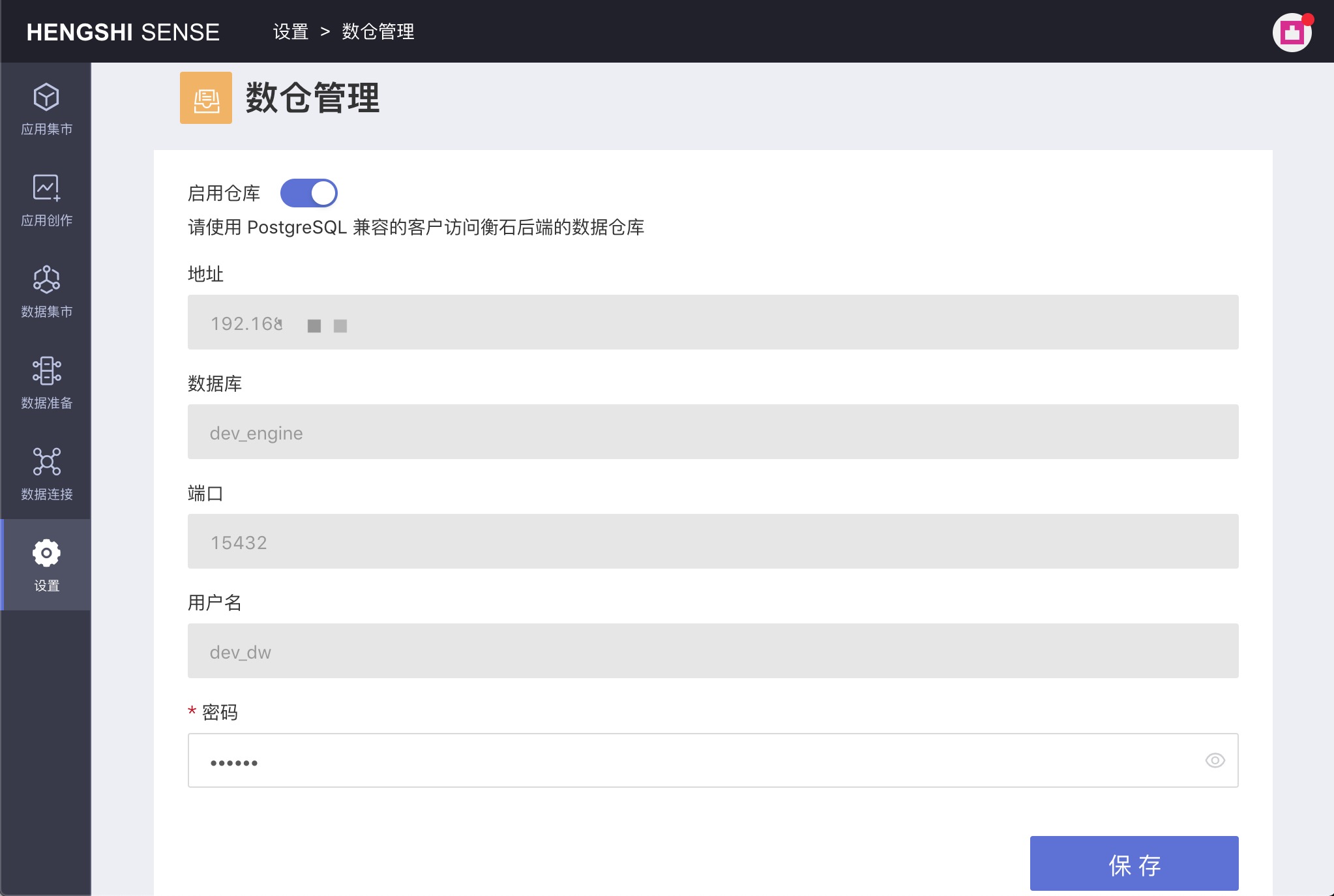
系统管理员打开设置->数仓管理,将打开数仓管理页面。该页面会返回系统使用的数仓的系统信息,包括主机地址、数据库、端口、用户名和密码。
启用数仓
打开启用仓库并点击保存之后,用户可以在外部系统中使用衡石数仓,也可以在 HENGSHI SENSE 中使用衡石数仓创建数据连接,作为普通数据库来使用,进行读写。创建连接时,连接类型可以选择 postgresql 或者 greenplum。
修改数仓密码
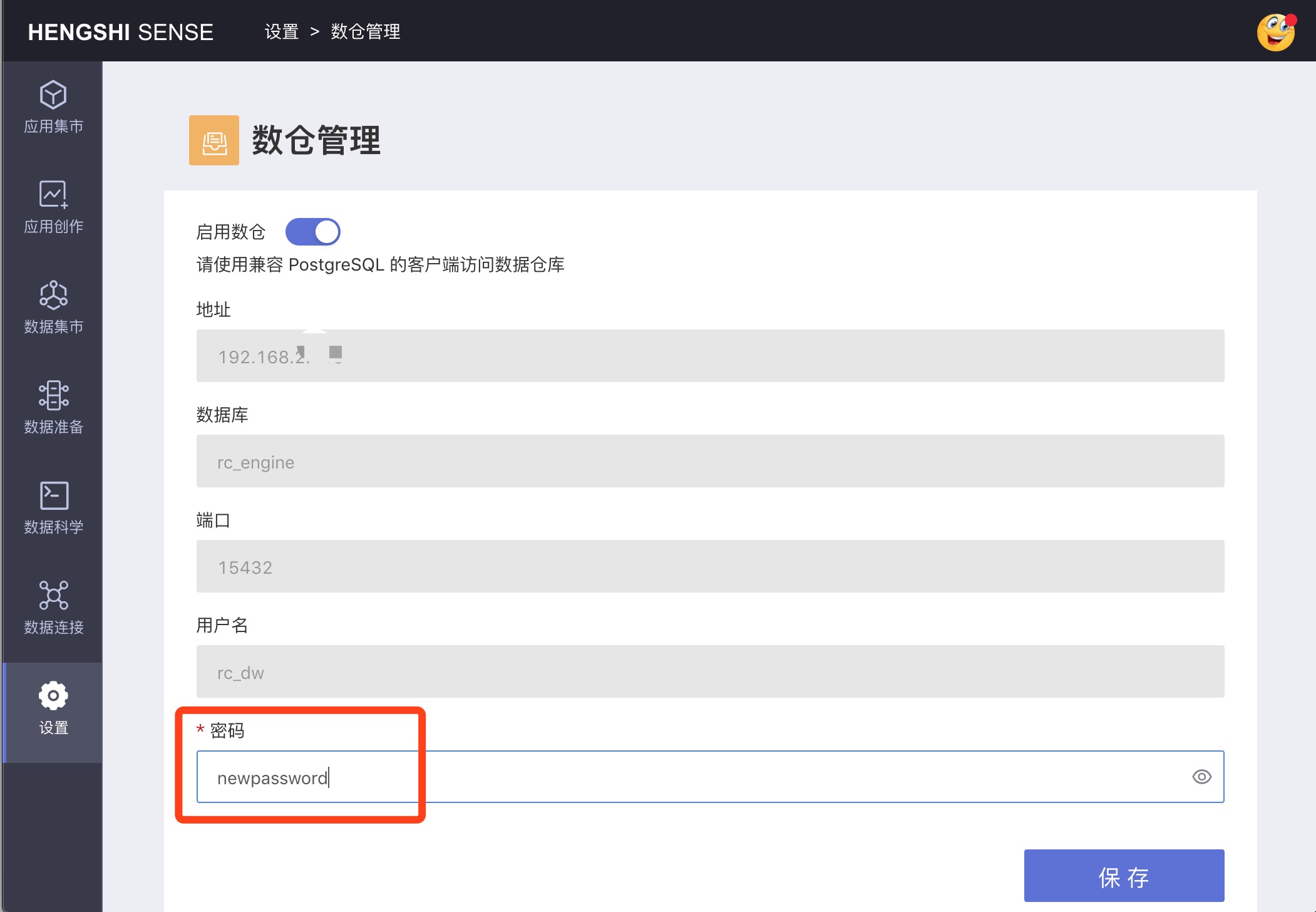
在数仓管理页面,可以在密码文本框中输入新密码来修改数仓密码,这是为了便于在衡石中管理数仓。
关闭数仓
关闭启用数仓并点击保存之后,即使已经用衡石数仓创建了数据连接,打开之后,会提示“连不上”,看不到任何数据。
连接数仓注意事项
数仓管理返回的主机地址受 HS_ENGINE_HOST 参数控制,参数配置方式请参见加速引擎配置方式。用户必须正确配置此参数,开放数仓之后,才能使用系统返回的主机地址连接到数仓。
如果使用数仓返回的信息在数据连接处连不上数仓,请登录安装 HENGSHI SENSE 的主机上执行如下命令检查问题出在哪里,其中,<ip> 和 <port> 要替换为数仓返回的主机地址和端口:
sh
timeout 1 bash -c "cat < /dev/null > /dev/tcp/<ip>/<port>" &> /dev/null; echo $?如果返回 0 ,则说明本地连接端口没有问题,然后执行下列命令检查本地是否可以连上引擎数据库:
sh
/opt/hengshi/lib/pgsql/bin/psql -Udwguest -h<ip> -p<port> <database>如果在外部系统中连接数仓,需要检查端口是否对外开放:
sh
telnet <ip> <port>
















 2006
2006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









