







1. F1
- Precision(精确率):被预测为离群点的实例中,实际为离群点的比例。
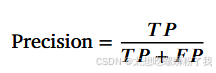
- Recall(召回率):实际为离群点的实例中,被正确预测为离群点的比例。

- F1综合了以上两者:F1分数同时考虑了模型的精确率和召回率,通过调和平均的方式将两者合并成一个单一的分数,以便在不同类别的样本不平衡时也能公平地评估模型性能。
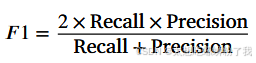
ps:其中第一个字母T(预测正确)/F(预测错误)
第二个字母表示预测结果,P(离群点)/N(正常点)
TP——本身为离群点预测(正确)为离群点
FP——本身为正常点预测(错误)为离群点
取值范围为[0,1]
2. ACC(Accuracy准确率)
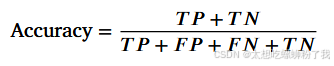
ps:分子为预测正确的样本数
分母为总样本数
取值范围为[0,1]
3. 排名能力RP(Rank-Power)
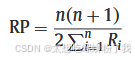
n表示在前N个最可疑实例的检测到的真实异常点
Ri表示第i个离群点在检测结果中的排名位置
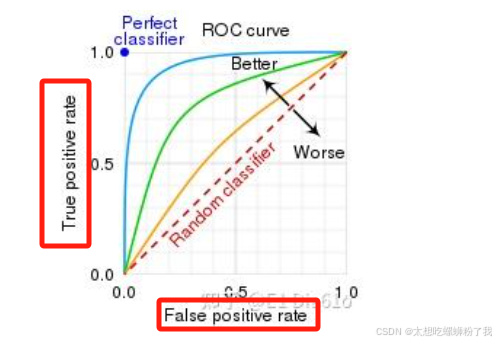
4.ROC曲线(Receiver Operating Characteristic)
- 定义:ROC曲线是一种描绘分类器性能的图形工具,它显示了在不同阈值下分类器的真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)之间的关系。
- 意义:ROC曲线是一种用于表示分类模型性能的图形工具。在机器学习和统计分析中,它通过将真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)作为横纵坐标来评估分类模型的性能。(其中,FPR为横坐标,TPR为纵坐标。)
- 真阳性率 (True Positive Rate, TPR)通常也被称为敏感性(Sensitivity)或召回率(Recall)。它是指分类器正确识别正例的能力。真阳性率可以理解为所有阳性群体中被检测出来的比率(1-漏诊率),因此TPR越接近1越好。它的计算公式如下:
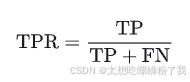
其中,TP(True Positive)表示正确识别的正例数量,FN(False Negative)表示错误地将正例识别为负例的数量。 - 假阳性率 (False Positive Rate, FPR)是指在所有实际为负例的样本中,模型错误地预测为正例的样本比例。假阳性率可以理解为所有阴性群体中被检测出来阳性的比率(误诊率),因此FPR越接近0越好。它的计算公式如下:

其中,FP(False Positive)表示错误地将负例识别为正例的数量,TN(True Negative)表示正确识别的负例数量。 - 理想情况:ROC 曲线越接近左上角,表示模型的性能越好。理想情况下,曲线会经过点 (0, 1),表示 FPR 为 0,TPR 为 1,即模型能够完美地识别所有离群点和正常点。
- 随机猜测:如果 ROC 曲线接近对角线(即 FPR = TPR),表示模型的性能与随机猜测相当。
5.AUC(Area Under the Curve)
AUC(ROC曲线下面积)是ROC曲线下的面积,用于衡量分类器性能。AUC值越接近1,表示分类器性能越好;反之,AUC值越接近0,表示分类器性能越差。在实际应用中,我们常常通过计算AUC值来评估分类器的性能。
- ROC曲线和AUC对比:通过ROC曲线,我们可以直观地了解分类器在不同阈值下的性能;而通过AUC值,我们可以对分类器的整体性能进行量化评估。

















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









