




目录
进程是操作系统一个核心概念。每个进程都有自己的唯一标识:进程 ID,也有自己的生命周期,一个典型的进程的生命周期如图:

进程 ID
Linux 下每个进程都会有一个非负整数表示的唯一进程 ID,简称 pid。Linux 提供了 getpid 函数来获取进程 pid,同时还提供了 getppid 函数来获取父进程的 pid,这两个函数的接口如下:
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);每个进程都有自己的父进程,父进程又会有自己的父进程,最终都会追溯到 1 号进程,即 init 进程。这就决定了操作系统上所有的进程必然会组成树状结构,就像一个家族的家谱一样。可以通过 pstree 命令来查看进程的家族树:

procfs 文件系统会在 /proc 下为每个进程创建一个目录,名字是该进程的 pid。目录下有很多文件,用于记录进程的运行情况和统计信息等:

因为进程有创建,也有终止,所以 /proc/ 下记录的目录(以及目录中的内容)也会发生变化。
操作系统必须保证在任意时刻都不能出现两个进程有相同 pid 的情况。虽然进程的 ID 是唯一的,但是进程 ID 可以重用。进程退出后,其进程 ID 还可以再次分配给其它的进程使用。那么问题来了,内核是如何分配进程 ID 的?
Linux 分配进程 ID 的算法不同于给进程分配文件描述符的最小可用算法,它采用了延迟重用的算法,即分配给新创建进程的 ID 经量不与最近终止进程的 ID 重复,这样就可以防止将新创建的进程误判为使用相同进程 ID 的已经退出的进程。
内核采用的方法如下:
- 位图记录进程 ID 的分配情况(0 为可用,1 为已占用)
- 将上次分配的进程 ID 记录到 last_pid 中,分配进程 ID 时,从 last_pid+1 开始找起,从位图中寻找可用的 ID
- 如果找到位图集合的最后一位仍不可用,则回滚到位图集合的起始位置,从这里开始找(回绕时并不是从 0 开始找起,而是从 300 开始。内核在 kernal/pid.c 文件中定义了 RESERVED_PIDS,其值是 300,300 以下的 pid 被系统占用,不能分配给用户进程)
既然是位图记录进程 ID 的分配情况,那么位图的大小就必须要考虑周全。位图的大小直接决定了系统允许同时存在的进程的最大个数,这个最大个数在系统中称为 pid_max.
Linux 系统下可以通过 procfs 或 sysctl 命令来查看 pid_max 的值:

此外,这个上限值是可以修改的,系统管理员可以通过如下的方法来修改此上限值:

但是内核自己也设置了硬上限,如果将 pid_max 的值设置成一个大于硬上限的值会失败:

从上面的操作我们可以看出,Linux 系统将系统进程数的硬上限设置为 4194304。那么内核又是如何决定系统个数的硬上限的呢?对此内核定义了如下宏:
#define PID_MAX_LIMIT (CONFIG_BASE_SMALL ? PAGE_SIZE * 8 : \
(sizeof(long) > 4 ? 4 * 1024 * 1024 : PID_MAX_DEFAULT))从上面的代码逻辑中可以看出系统进程个数硬上限的逻辑为:
- 如果选择了 CONFIG_BASE_SMALL 编译选项,则为页面 PAGE_SIZE 的位数
- 如果选择了 CONFIG_BASH_FULL 编译选项,那么:对于 32 位操作系统,系统进程个数硬上限为 32768;对于 64 位操作系统,系统进程个数硬上限为 4194303(这个数字相当庞大,足够应用层使用)
进程的层次
每个进程都有父进程,父进程也有父进程,这就形成了一个以 init 进程为根的家族树。除此之外,进程还有其他层次关系:进程、进程组和会话。
进程组是一组相关进程的集合,会话是一组相关进程组的集合。
因此,一个进程会有如下 ID:
- PID :进程的唯一标识
- PGID :进程组 ID。每个进程都会有进程组 ID,表示该进程所属的进程组。默认情况下新创建的进程会继承父进程的进程组 ID
- SID :会话 ID。每个进程也会有会话 ID。默认情况下,新创建进程会继承父进程会话 ID
可以通过如下指令来查看所有进程的层次关系:


对于进程而言,可以通过如下函数调用来获取其进程组 ID 和会话 ID:
#include<unistd.h>
pid_t getpgrp(void); //获取进程组 ID
pid_t getsid(pid_t pid); //获取进程所属会话 ID前面起到过,新创建的进程默认继承父进程的进程组 ID 和 会话 ID,如果都是默认情况的话,那么所有的进程应该有共同的进程组 ID 和会话 ID。事实并不是如此,系统中存在很多不同的会话,每个会话下有不同的进程组。
系统有改变和设置进程组 ID 和会话 ID 的函数接口。。。
进程组和会话是为了支持 shell 作业控制而引入的概念。
当有新的用户登录 Linux 时,登录进程会为这个用户创建一个会话。用户登录的 shell 就是会话的首进程。会话的首进程 ID 会作为整个会话的 ID。会话是一个或多个进程组的集合,囊括了用户的所有活动。
在登录 shell 时,用户可能会使用管道,让多个进程互相配合完成一项工作,这一组进程属于同一个进程组。
当用户通过 SSH 客户端工具(xshell 等)进入 Linux 时,与上述登录情况是类似的。
进程组
修改进程组 ID:
#include <unistd.h>
int setpgid(pid_t pid, pid_t pgid);
该函数的含义是,找到进程 ID 为 pid 的进程,将其进程组 ID 修改为 pgid,如果 pid 的值为 0,则表示要修改调用进程的进程组 ID。该接口一般用来创建一个新的进程组。
下面三个接口含义一致,都是创立新的进程组,并且指定的进程会成为进程组的首进程。如果参数 pid 和 pgid 的值不匹配,那么该函数会将一个进程从原来所属的进程组迁移到 pgid 所属的进程组。
setpgid(0,0);
setpgid(getpid(),0);
setpgid(getpid(),getpid());使用 setpgid 函数需要注意:
- pid 参数必须指定为调用 setpgid 函数的进程或其子进程,不能随意修改不相关进程的进程组 ID,如果违反此条规则,则返回 -1,并置 error 为 ESRCH
- pid 参数可以指定为调用 setpgid 进程的子进程,但是如果子进程执行了 exec 系列函数,则不能修改子进程的进程组 ID。如果违反此条规则,则返回 -1,并置 error 为 EACCESS
- 在进程组间移动,调用进程,pid 指定的进程及目标进程组必须属于同一个会话。如果违反此条规则,则返回 -1,并置 error 为 EPERM
- pid 制定的进程,不能是会话的首进程。如果违反此条规则,则返回 -1,并置 error 为 EPERM
有了创建进程组的接口,子进程就不必继承父进程的进程组 ID 了。最常见的创建进程组的场景就是 shell 中执行管道命令:
ps ax | grep nfsd
ps 进程和 grep 进程都是 bash 创建的子进程,两者通过管道协同完成一项工作,他们属于同一个进程组,其中 ps 进程是进程组的组长。
shell 中协同工作的进程属于同一个进程组,就如同协同工作的人属于同一个部门一样。
引入进程组的概念,可以更方便的管理这一组进程了。比如某项工作放弃了,就不必向每个进程一一发送信号,可以直接将信号发送给进程组,进程组内的所有进程都会收到该信号。
子进程一旦执行 exec 系列函数,父进程就无法调用 setpgid 函数来设置子进程的进程组 ID,这条规则会影响 shell 的作业控制。处于保险的考虑,一般父进程在调用 fork 创建子进程后,会调用 setpgid 函数设置子进程的进程组 ID,同时子进程也会调用 setpgid 函数来设置自身的进程组 ID。这两次调用有一次是多余的,但是这样可以保证 fork 之后,无论是父进程先执行,还是子进程先执行,子进程已经进入了指定的进程组当中。由于 fork 之后,父子进程的执行顺序是不确定的,因此如果不这样做,就会造成一定时间窗口内,无法确定子进程是否进入了相应的进程组。
会话
会话是一个或多个进程组的集合,以用户登录系统为例,可能存在如图所示的情况:

系统提供 setsid 函数来创建会话:
#include <unistd.h>
pid_t setsid(void);
如果调用这个函数的进程不是进程组的组长,那么调用该函数会发生以下事情:
- 创建一个会话,会话 ID 等于进程 ID,调用进程成为会话的首进程
- 创建一个进程组,进程组 ID 等于进程 ID,调用进程成为进程组的组长
- 该进程没有控制终端,如果调用 setsid 函数前,该进程有控制终端,这种联系就会断掉
调用 setsid 函数的进程不能是进程组的组长,否则调用会失败,返回 -1,并置 error 为 EPERM。
这个限制是比较合理的。如果允许进程组组长迁移到新的会话,而进程组的其他成员还在老的会话中,那么,就会出现同一个进程组的成员分属不同的会话之中的情况,这就破坏了进程组和会话的严格的层次关系了。
Linux 提供 setsid 命令,可以在新的会话中执行命令,通过该命令可以很容易的验证上面提到的三点:

系统创建了新的会话 10446,新的会话下又创建了新的进程组,会话 ID 和进程组 ID 都等于进程 ID,而该进程已经没有任何控制终端了(TTY 对应的值为 '?',表示进程没有控制终端)
常用的调用 setsid 函数的场景是 login 和 shell。除此以外创建 deamon 也要调用 setsid 函数。
进程创建之 fork
Linux 系统下,进程可以调用 fork 函数来创建新的进程。调用进成为父进程,被创建进成为子进程。
#include <unistd.h>
pid_t fork(void);
与普通函数不同。fork 函数会返回两次。一般来说,创建两个完全相同的进程并没有太多的价值。大部分情况下,父子进程会执行不同的代码分支。fork 函数的返回值就成了区分父子进程的关键。fork 函数向子进程返回 0,并将子进程的 ID 返回给父进程。调用失败,fork 返回 -1,并设置 error。
fork 函数可能的 error:
- EAGAIN :超出了容许用户创建进程的上限,也可能是超出了系统容许创建进程的硬上限值
- ENOMEM :无法分配相应的内核结构,内存紧张的情况下,可能发生这种情况
- ENOSYS :平台不支持 fork
fork 之后,对于父子进程,谁先获得 CPU 资源,谁先被执行呢?
从内核 2.6.32 开始,在默认情况下,fork 之后父进程率先被执行。采取这种策略的原因是:fork 之后父进程在 CPU 中处于活跃状态,并且其内存管理信息也被置于硬件内存管理单元的转译后备缓冲器(TLB),所以先调度父进程能提升性能。
从 2.6.24 开始,Linux 采取完全公平调度(CFS)。用户创建的普通进程都采取 CFS 调度策略。
POSIX 和 Linux 都没有规定谁先被调度。因此在应用中绝不能对父子进程的执行顺序有任何的假设。如果确实需要某一特定执行顺序,那么需要使用进程间同步的知识。。。
fork 之后父子进程的内存关系
子进程和父进程执行一模一样的代码的情形比较少见。Linux 提供 execve 系统调用,构建在该系统调用之上。glibc 提供了 exec 系列函数,这些系列函数会替换现存的程序代码段,并构建新的数据段、栈及堆。调用 fork 函数之后,子进程几乎总是通过调用 exec 系列函数,来执行新的程序。
在这种背景下,fork 时子进程完全拷贝父进程的数据段、栈及堆的做法是不明智的,因为接下来的 exec 系列函数会毫不留情地抛弃刚刚辛苦拷贝的内存。为了解决这个问题,Linux 引入了写时拷贝技术。
写时拷贝是指子进程的页表项指向与父进程相同的物理内存页,这样 fork 时只拷贝父进程的页表项就可以了,当然要把这些页表项标记为只读。如果父子进程都不修改内存的内容,便相安无事,父子进程公用一份物理内存页。但是一旦父子进程中有任何一方尝试修改某一页表项,就会引发缺页异常。此时,内核会尝试为该页表项创建一个新的物理页面,并将相应内容复制到物理页面中,让父子进程真正地各自拥有自己的物理内存页,然后将页表中相应的页表项标记为可读。

这种机制的引入提升了 fork 的性能,从而使内核可以快速的创建一个进程。
Linux 内存管理使用的是四级页表。。。
fork 之后父子进程与文件的关系
执行 fork 函数,内核会复制父进程所有的文件描述符。对于父进程打开的文件,子进程也是可以操作的。那么父子进程同时操作一个文件会不会相互影响是值得去关注的一个问题。。。
先看下面这个简单的程序:父子进程都会去读文件 in.txt。该文件的内容是:

#include<stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd_in = open("in.txt", O_RDONLY);
if(fd_in < 0){
printf("open failed!\n");
return 1;
}
int fd_out = open("out.txt",O_WRONLY | O_CREAT);
if(fd_out < 0){
printf("open failed!\n");
return 2;
}
int ret = fork();
if(ret < 0){
printf("fork error!\n");
return 3;
}
int buf[1024];
memset(buf,0,1024);
while(read(fd_in,buf,1) > 0){
write(fd_out,buf,strlen(buf));
sleep(1);
memset(buf,0,strlen(buf));
}
return 0;
}
从程序中很容易看出,我们是将父子进程读取到的内容写到文件 out.txt 中,该文件内容如下:

如果父子进程各自维护自己的文件偏移量,那么一定会输出两套 1~5,但事实并非如此。无论父进程还是子进程调用 read 函数导致文件偏移量后移都会被对方获知,这表明父子进程共用了一套文件偏移量。
写文件也是一样的,如果 fork 之前打开了某文件,fork 之后父子进程对该文件同时进行写操作而又不采取任何同步手段,那么就会因为共享文件偏移量使输入相互混合。
这里简单的了解到父子进程共享文件偏移量这一事实,内核究竟是如何实现的呢?
文件描述符复制的内核实现
在内核的进程描述符 task_struct 结构体中,与打开文件相关的变量如下所示:
struct task_struct{
...
struct files_struct *files;
...
}调用 fork 时,内核会在 copy_files 函数中处理 ☞ 拷贝父进程打开的文件相关的事宜:
该函数中有一个标志位 CLONE_FILES,用来控制是否共享父进程的文件描述符。如果该标志位置位,则表示不必复制父进程的文件描述符了,增加引用计数,直接公用一份就可以了。对于 vfork 和创建线程的 pthread_create 函数来说都是如此。但是 fork 函数却不同,调用 fork 函数时,该标志位为 0,表示需要为子进程拷贝一份父进程的文件描述符。
文件描述的拷贝是通过内核的 dup_fd 函数来完成的:
dup_fd 函数首先会给子进程分配一个 files_struct 结构体,然后做一些赋值操作。这个结构体是与打开文件相关的结构体,每一个打开的文件都会记录在该结构体中。其定义的代码如下:
struct files_struct{
atomic_t count;
struct fdtable __rcu *fdt;
struct fdtable fdtable;
spinlock_t file_lock ____cacheline_aligned_in_smp;
int next_fd;
struct embedded_fd_set close_on_exec_init; //位图
struct embedded_fd_set open_fds_init; //位图
struct file __rcu *fd_array[NR_OPEN_DEFAULT];
}
struct fdtable{
unsigned int max_fds;
struct file __rcu **fd;
fd_set *close_on_exec;
fd_set *open_fds;
struct rcu_head rcu;
struct fdtable *next;
}
struct embedded_fd_set{
unsigned long fds_bits[1];
}初看之下 struct fdtable 的内容与 struct files_struct 的内容有好多重复之处,包括 close_on_exec 文件描述符位图、打开文件文件描述符位图及 file 指针数组等,但事实并非如此。struct files_struct 中的成员是相应数据结构的实例,而 struct fdtable 中的成员是相应的指针。
Linux 系统假设大多数进程打开的文件不会太多。于是 Linux 选择了一个 long 类型的位数作为经验值。
以 64 位操作系统为例,file_struct 结构体自带了可以容纳 64 个 struct file 类型指针的数组 fd_array,也自带了两个大小为 64 的位图,其中 close_on_exec_init 位图用于记录文件描述符的 FD_CLOSEXCE 标志位是否置位。只要进程打开的文件描述符个数小于 64,files_struct 自带的指针数组和两个位图就足以满足需要。因此在分配了 files_struct 结构体后,内核会初始化 files_struct 自带的 fdtable。
初始化之后,子进程的 files_struct 的情况如下:

注意此时 files_struct 结构体中的 fdt 指针并未指向 files_struct 自带的 struct fdtable 类型的 fdtable 变量。原因很简单,因为此时内核还没有检查父进程打开的文件的个数,因此并不能确定自带的结构体能否满足需要。
接下来内核会检查父进程打开的文件的个数。如果父进程打开的文件超过了 64 个,struct files_struct 中自带的数组和位图就不能满足需要了。这种情况下内核会分配一个新的 struct fdtable:
内核分配一个新的 struct fdtable 结构体、分配一个指针数组和两个位图是由 alloc_fdtable 函数来完成的。分配之前会根据父进程打开文件的数目,计算出一个合理的值 nr,以确保分配的数组和位图能够满足需要

无论是使用 files_struct 结构体自带的 fdtable,还是使用 alloc_fdtable 分配的 fdtable,接下来要做的事情都一样,就是将父进程的两个位图信息和打开文件的 struct file 类型指针拷贝到子进程的对应数据结构中。
通过上面的流程梳理,我们发现,父子进程之间拷贝的是 struct file 指针,而不是 struct file 的实例,父子进程的 struct file 类型的指针,都指向同一个 struct file 实例。fork 之后,父子进程的文件描述符关系如下:

现在来看看 struct file 结构体:
struct file{
...
unsigned int f_flags;
fmode_t f_mode;
loff_t f_pos; //文件偏移量
}说到这里,就不难理解父子进程是如何共享文件偏移量的了吧。因为父子进程的文件指针都指向了同一个 struct file 结构体,而该结构体中记录了文件的偏移量。
进程创建之 vfork
在早期的实现中,fork 没有实现写时拷贝机制,而是直接对父进程的数据段、堆和栈进行完全拷贝,效率十分低下。很多程序在 fork 后,会紧接着执行 exec 系列函数,这更是一种浪费。所以 BSD 引入 vfork,既然 fork 之后会执行 exec 系列函数,拷贝父进程的数据就变成一种无意义的行为,所以引入的 vfork 压根不会拷贝父进程的内存数据,而是直接共享。再后来 Linux 引入了写时拷贝技术,其效率提高了很多,这样一来 vfork 就基本可以退出历史舞台了。除了一些将性能优化到极致的场景,大部分情况下不再需要使用 vfork 函数了。
vfork 会创建一个子进程,该子进程会共享父进程的内存数据,而且系统将保证子进程先于父进程获得调度。子进程也会共享父进程的地址空间,而父进程将一直挂起,至到子进程退出或执行 exec 系列函数。
注意,vfork 之后,子进程如果返回,则不要调用 return,而应该使用 _exit 函数。。。
daemon 进程的创建
进程的终止
在不考虑线程的情况下,进程的退出有以下五种方式:
正常退出有三种:
- 从 main 函数 return 返回
- 调用 _exit
- 调用 exit
异常退出有两种:
- 调用 abort
- 接收到信号,由信号终止
_exit 函数
函数原型:
#include <unistd.h>
void _exit(int status);status 参数定义了进程的终止状态,父进程可以通过 wait() 来获取该状态值。需要注意的是,虽然 ststus 是 int 型,但是只有低 8 位可以被父进程所用。
exit 函数
函数原型:
#include <stdlib.h>
void exit(int status);
exit 函数最后也会调用 _exit 函数,但在调用 _exit 函数之前,还做了其他工作:
- 执行用户通过 atexit 函数或 on_exit 定义的清理函数
- 关闭所有打开的流(stream),所有缓冲的数据均被写入,通过 tmpfile 创建的临时文件都会被删除。
- 调用 _exit

下面介绍 exit 函数和 _exit 函数的不同之处:
exit 函数会执行用户定义的清理函数。用户可以通过 atexit() 函数或 on_exit() 函数来定义清理函数。这些清理函数在调用 return 或 exit 时会被执行。执行的顺序与函数注册的顺序相反。当进程收到致命信号而退出时,注册的清理函数不会被执行。当进程调用 _exit 退出时,注册的清理函数不会被执行;当执行到某个清理函数时,若收到致命信号或清理函数执行了 _exit 函数时,该清理函数不会返回,从而导致排在后面的需要执行的清理函数都会被丢弃。
exit 函数会冲刷标准 I/O 库的缓冲并关闭流。glibc 提供的很多与 I/O 相关的函数都提供了缓冲区,用于缓存大块数据。
缓冲有三种:
- 无缓冲 :就是没有缓冲区,每次调用 stdio 库函数都会立即调用 read/write 系统调用
- 行缓冲 :对于输出流,收到换行符之前,一律缓冲数据,除非缓冲区满了。对于输入流,每次读取一行数据
- 全缓冲 :就是缓冲区满之前,不会调用 read/write 系统调用来进行读写操作
对于后两种缓冲,可能会出现这种情况:进程退出时,缓冲区里面可能还有未冲刷的数据。如果不冲刷缓冲区,缓冲区里面的数据就会丢弃。比如行缓冲迟迟没有等到换行符,又或者全缓冲没有等到缓冲区满。尤其是后者很容易出现,因为 glibc 的缓冲区默认是 8192 字节。exit 函数在关闭流之前,会冲刷缓冲区的数据,确保缓冲区里面的数据不会丢失。
关于这一点,看下面的例子:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void fun1(){
fprintf(stdout,"111\n");
}
void fun2(){
fprintf(stdout,"222\n");
}
int main(int argc,char **argv){
atexit(fun1);
atexit(fun2);
fprintf(stdout,"666");
sleep(1);
if(argc > 1 && strcmp(argv[1],"exit") == 0)
exit(0);
if(argc > 1 && strcmp(argv[1],"_exit") == 0)
_exit(0);
return 0;
}
注意上面的代码,fprintf 函数打印的字符串是没有换行符的,对于标准输出流 stdout 采用的是行缓冲,收到换行符之前是不会输出的。
输出情况:

尽管缓冲区里面的数据没有等到换行符,但是调用 exit 函数返回时(return 也一样),缓冲区里面的数据都会被冲刷。从输出情况来看,exit 函数先执行缓冲区的冲刷,再执行用户注册的清理函数。。。
存在临时文件,exit 函数会负责将临时文件删除。
exit 函数最后调用 _exit 函数,最终属兔同归,走向内核清理。。。
return 退出
return 是一种更常见的终止进程的方法。执行 return n 等同于执行 exit(n),因为调用 main 函数运行时函数会将 main 函数的返回值当作 exit 的参数。
等待子进程
僵尸进程
进程退出时会进行内核清理,基本就是释放进程资源或者引用计数减一,这里的资源包括内存资源、文件资源、信号量资源、共享内存资源。不过,进程的退出并没有将所有的资源释放,比如进程的 PID 依然被占用着,不可被系统分配。此时的进程不可运行,事实上没有地址空间让其运行,进程进入僵尸状态。
那么为什么进程退出之后不将所有的资源都释放掉,非要保留少量资源,进入僵尸状态呢?
看看僵尸进程占有的系统资源,我们就能获得答案。这些资源不释放是为了提供一些重要的信息,比如进程为何退出、是收到信号退出还是正常退出、进程退出码是多少、进程一共消耗了多少 CPU 时间、多少用户 CPU 时间、收到了多少信号、发生了多少次上下文切换、最大内存驻留集是多少、产生多少缺页中断等等。这些信息,总结了进程的一生。如果没有这个僵尸状态,进程的这些信息也会随之流失,系统也就没有机会获取这个进程的相关信息了。因此进程退出后,会保留少量的资源,等待父进程前来收集这些信息。一旦父进程收集了这些信息之后,这些残存的资源完成了它的使命,就可以释放了,进程就脱离僵尸状态,彻底消失了。
从上面的讨论可以看出,构造一个僵尸进程是很容易的事情,只要父进程调用 fork 创建子进程,子进程退出后,父进程如果不调用 wait 或 waitpid 来获取子进程的退出信息,子进程就会沦为僵尸进程。
#include <stdio.h>
#include <unistd.h>
int main(){
int pid = fork();
if(pid < 0){
printf("fork error!\n");
}
else if(pid == 0){
exit(1);
}
else{
sleep(200);
wait(NULL);
}
return 0;
}
该程序中父进程休眠 200 秒后才调用 wait 函数来获取子进程的退出信息。在这 200 秒左右的时间内,子进程就是一个僵尸进程。
查看进程是否处于僵尸状态:

另外,procfs 提供的 status 信息中的 State 给出的值是 Z(zombie),也表明进程处于僵尸状态:

进程一旦处于僵尸状态,就进入了一种刀枪不入的状态,“杀人不眨眼”的 kill -9 也无能为力,因为谁也没有办法杀死一个已近死去的进程。
一般而言,系统不希望大量进程长期处于僵尸状态,因为会浪费系统资源。除了少量的内存资源外,比较重要的是进程 ID。僵尸进程并没有将自己的进程 ID 归还给系统,而是依然占有这个进程 ID,因此系统不能将该 ID 分配给其他进程。
对于编程来说,如何防范僵尸进程的产生呢?
如果父进程关心子进程的退出信息,则应该在流程上妥善设计,能够及时地调用 wait 函数,使子进程处于僵尸状态的时间不要太久。
如果我们不关心子进程的退出状态,就应该将父进程对 SIGCHLD 信号的处理函数设置为 SIG_IGN,或者在调用 sigaction 函数时设置 SA_NOCLDWAIT 标志位。这两者都会明确的告诉子进程,父进程很“绝情”,不会为子进程“收尸”。子进程退出的时候,内核会检查父进程是否将 SIGCHLD 信号的处理函数显示地设置为 SIG_IGN,或者父进程的 SIGCHLD 信号处理结构体是否设置了 SA_NOCLDWAIT 标志位。如果是,子进程不会进入僵尸状态,而是调用 release_task 函数“自行了断”了。
等待子进程 ☞ wait()
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
成功时返回子进程 ID,失败时返回 -1,并设置 error 的值,常见的 error 有:
- ECHLD :进程调用该函数时发现并没有子进程需要等待
- EINTR :函数被信号中断
父子进程是两个进程,子进程退出和父进程调用 wait 函数来获取子进程的退出信息在时间上是独立的事件,因此会出现以下两种情况:
- 子进程先退出,父进程后调用 wait 函数。这种情况下,子进程几乎已经销毁了自己所有的资源,只留下少量信息,等待父进程来“收尸”。当父进程调用 wait 函数,获取到子进程的退出信息,wait 函数立即返回
- 父进程先调用 wait 函数,子进程后退出。这种情况下,函数调用会陷入阻塞状态,至到某个子进程退出
wait 函数等待的是任意一个子进程,任何一个子进程退出,都可以让其返回。当多个子进程都处于僵尸状态,wait 函数获取到其中一个子进程的退出信息后立即返回。由于 wait 函数不接受 pid_t 类型的参数,所以它无法明确的等待特定的子进程。
一个进程如何等待所有的子进程退出呢?wait 函数返回有三种可能性:
- 等到了子进程退出,获取其退出信息,返回子进程的进程 ID
- 等待过程中收到了信号,信号打断了系统调用,并且注册信号处理函数时并没有设置 SA_RESTART 标志位,系统调用不会被重启,wait 函数返回 -1,并将 error 设置为 EINHLD
- 已经成功的等待了所有子进程,没有子进程的退出信息需要获取,在这种情况下 wait 函数返回 -1,并将 error 设置为 EINTR
有人给出下面的代码来等待所有子进程退出:
while((pid = wait(NULL)) != -1)
continue;
if(error != ECHLD)
errExit("wait");这种方法并不完全,因为这里忽略了 wait 函数被信号中断的这种情况,如果 wait 函数被信号中断,上面的代码并不能成功地等待所有子进程退出。
若将上面的 wait 函数封装一下,使其在信号中断后,自动重启 wait 就完备了:
pid_t _wait(int *status)
{
int ret;
while((ret = wait(status)) == -1 && error == EINTR)
continue;
return ret;
}
while((pid = _wait(NULL)) != -1)
continue;
if(error == ECHILD){
errExit("wait");
}如果父进程调用 wait 函数时,已经有多个子进程退出且都处于僵尸状态,那么哪一个子进程会被先处理是不确定的。
wait 函数存在一定的局限性:
- 不能等待特定的子进程。如果进程存在多个子进程,而它只想获取某个子进程的退出信息,并不关心其他子进程的退出信息,此时 wait 只能一一等待,通过查看返回值来判断是否为关心的子进程
- 如果没有子进程退出,wait 只能阻塞。有些时候,仅仅是想尝试获取退出进程的退出信息,如果不存在子进程退出就立即返回,不需要阻塞等待,类似于 trywait 的概念,wait 函数没有提供 trywait 的接口
- wait 函数只能发现子进程的终止事件,如果子进程因某信号而停止,或者停止的子进程收到 SIGCONT 信号又恢复执行,这些事件 wait 函数是无法获知的。换言之,wait 函数能探知子进程的死亡,却不能探知子进程的昏迷(暂停),也无法探知子进程从昏迷中苏醒(恢复执行)
进程等待 ☞ waitpid()
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *status, int options);
第一个参数是 pid_t 类型,有了此值,不难看出 waitpid 函数肯定具备了精确打击的能力。waitpid 函数可以明确指明要等待哪一个子进程退出(以及停止和恢复执行)。更具体的表达是:
- pid > 0 :表示等待进程的 ID 为 pid 的子进程,也就是上面提到的精确打击的对象
- pid = 0 :表示等待与调用进程同一个进程组里面的任意子进程;因为有些子进程不一定和父进程归属于同一个进程组,这样的子进程 waitpid 函数就毫不关心了
- pid = -1 :表示等待任意子进程,同 wait 类似
- pid < -1 :等待进程组 ID 与 pid 绝对值相等的所有子进程
内核之中,wait 和 waitpid 函数调用的都是 wait4 系统调用。函数中间部分,根据 pid 的正负或者是否为 0 和 -1 来定义 wait_opts 类型的变量 wo,后面会根据 wo 来控制用户关心的那些事件。
内核的 do_wait 函数会根据 wait_opts 类型的变量 wo 变量来控制到底在等待那些子进程的退出信息。
当前进程的每一个线程(在内核层面,线程就是进程,每个线程都有独立的 task_struct 结构体),都会遍历其子进程。在内核中,task_struct 中的 children 成员变量是个链表头,该进程的所有子进程都会链入该链表,遍历起来比较方便。
但是我们并不一定关心所有的子进程。当 wait 和 waitpid 函数的第一个参数 pid 等于 -1 的时候,表示任意子进程我们都关心。但是如果是 waitpid 函数的其他情况,则表示我们只关心其中的某些子进程或某个子进程。内核需要对所有的子进程进行过滤,找到关心的子进程。这个过滤的环节是在内核的 eligible_pid 函数中完成的。
waitpid 函数的第三个参数 options 是一个掩码,可以同时存在多个标志。当 options 没有设置任何标志位时,其行为与 wait 类似,及阻塞等待。
options 标志位可以是以下标志位的组合:
- WUNTRACED :除了关心终止子进程的信息,也关心那些因信号而停止的子进程信息
- WCONTINUED :除了关系终止子进程的信息,也关心那些因信号而恢复执行的子进程的信息
- WNOHANG :制定的子进程并未发生状态改变,立即返回,不会阻塞。这种情况下的返回值是 0。如果没有与 pid 匹配的子进程,则返回 -1,并设置 error 为 ECHLD,根据返回值和 error 可以区分这两种情况
传统的 wait 函数只关注子进程的终止,而 waitpid 函数则可以通过前两个标志位来检测子进程的停止和从停止中恢复这两个事件。
说到这里,需要解释一下什么是“使进程停止”、什么是“使进程继续”,以及为什么需要这些。设想下如下场景:正在某机器上编译一个大型项目,编译的过程要消耗很多 CPU 资源和磁盘 I/O 资源,并且耗时很久。如果我想用机器暂时处理其他事情,虽然可能只占几分钟时间,但这会使这几分钟内的用户体验非常糟糕。这时候杀掉编译进程是一个选择,但这个方案并不好。因为编译耗时很久,杀死进程,你将不得不从头开始编译项目。这时候,我们需要的仅仅是让编译进程停下来,把 CPU 资源和 I/O 资源暂时让出来,让我们从容地做自己的事情,几分钟的时间,我用完了,让编译的进程继续工作就行了。
Linux 提供 SIGTOP 和 SIGCONT 两个信号,来完成暂停和恢复的动作,可以通过执行 kill -SIGTOP 或 kill -19 来暂停一个进程的执行,通过执行 kill -SIGCONT 或 kill -18 来让一个暂停的进程恢复执行。
waitpid 函数可以通过 WUNTRACED 标志位关注停止的事件,如果有子进程收到信号处于停止状态,waitpid 函数就可以返回。
waitpid 函数可以通过 WCONTINUED 标志位关注恢复执行的事件,如果有子进程收到信号而恢复执行,waitpid 函数就可以返回。
但是上述两个事件和子进程的终止事件是并列的关系,waitpid 函数成功返回的时候,可能是等到了子进程的终止事件,也可能是等到了暂停或恢复执行的事件。这需要通过 ststus 的值来区分。。。
等待子进程 ☞ 等待状态值
无论是 wait 函数还是 waitpid 函数,都有一个 status 变量。这个变量是一个 int 型指针。可以传递 NULL,表示不关心子进程的状态信息。如果不为空,则可以根据填充的 status 值,可以获取到子进程的好多信息:

根据上图,直接根据 status 的值可以获得进程的退出方式,但是为了保证可以移植性,不应该直接解析 status 的值来获取退出状态。因此系统提供了相应的宏,用来解析返回值。
进程是正常退出的
有两个宏和正常退出相关。
- WIFEXITED(status) :如果子进程正常退出,则返回 true,否则返回 false
- WEXITSTATUS(status) :如果子进程正常退出,则本宏用来获取进程的退出状态
进程收到信号导致退出
有三个宏和这种情况相关。
- WIFSIGNALED(status) :如果进程是被信号杀死的,则返回 true,否则返回 false
- WTERMSIG(status) :如果进程是被信号杀死的,则返回杀死进程的信号的值
- WCOREDUMP(status) :如果子进程产生了 core dump,则返回 true,否则返回 false
进程收到信号被停止
有两个宏与这种情况相关。
- WIFSTOPPED(status) :如果子进程因收到相关信号,暂停执行,处于停止状态,则返回 true,否则返回 false
- WSTOPSIG(status) :如果子进程处于停止状态,这个宏返回导致子进程停止的信号的值
之所以需要 WSTOPSIG(status) 宏来返回导致子进程停止的信号值,是因为不只一个信号可以导致子进程停止:SIGTOP、SIGTSTP、SIGTTIN、SIGTTOU,都可以使进程停止。
子进程恢复执行
有一宏与这种情况相关 :WIFCONTINUED(status) 如果由于 SIGCONT 信号的递送,子进程恢复执行,则返回 true,否则返回 false。
只有 SIGCONT 信号才能使子进程从停止状态中恢复过来。如果子进程恢复执行,只可能是收到了 SIGCONT 信号。
有了上面的宏,我们在判断子进程退出状态时会变得非常方便。。。
进程等待 ☞ waitid()
该函数的引进是因为 waitpid 函数还是存在不足之处,比如 waitpid 函数返回时,可能是因为子进程终止,也可能是因为子进程停止,这是 waitpid 函数的致命缺陷。如果用户不关心子进程的终止事件,只关心子进程的停止事件,waitpid 函数是做不到的。
尽管 wait 和 waitpid 函数是目前普遍使用的,但 waitid 函数的设计更加合理。
#include <sys/types.h>
#include <sys/wait.h>
int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options);
关于这个函数先介绍这么多。。。
进程退出和等待的内核实现
exec 家族
整个 exec 家族有 6 个函数,这些函数都是构建在 execve 系统调用之上的。该系统调用的作用是:将新程序加载到进程的地址空间,丢弃旧有的程序,进程的栈、数组段、堆栈等都会被新程序替换。
基于 execve 系统调用的 6 个 exec 函数,接口虽然各异,功能却是相同的。
execve 函数
execve 函数的接口定义如下:
#include <unistd.h>
int execve(const char *filename, char *const argv[],
char *const envp[]);
第一个参数 filename 是准备执行的新程序的路径名,可以是绝对路径,也可以是相对于当前工作目录的相对路径。
第二个参数很容易让我们联想到 C 语言 main 函数的第二个参数,事实上二者格式也是一样的:字符串指针组成的数组,以 NULL 结束。argv[0] 一般对应可执行文件的文件名,也就是路径名最后一个 / 后面的部分。当然如果 argv[0] 不遵守这个约定也无妨,因为 execve 可以从第一个参数获取到可执行文件的文件名,只要不是 NULL 即可。
第三个参数与 C 语言的 main 函数的第三个参数 envp 一样,也是字符串指针数组,以 NULL 结束,指针指向的字符串的格式为 name=value。
一般来说,execve 函数总是紧随 fork 函数之后。父进程调用 fork 函数之后,子进程执行 execve 函数,抛弃父进程的程序段。但是也可以不执行 fork 函数,直接调用 execve 函数,替换当前进程:
#include <stdio.h>
#include <unistd.h>
int main(){
char *const argv[] = {"ls","-l",NULL};
if(execve("/bin/ls",argv,NULL) == -1){
printf("execve error!\n");
}
printf("666\n");
return 0;
}
上面这个程序没有调用 fork,直接调用了 execve 函数,通过替换,该程序变成了 ls -l。
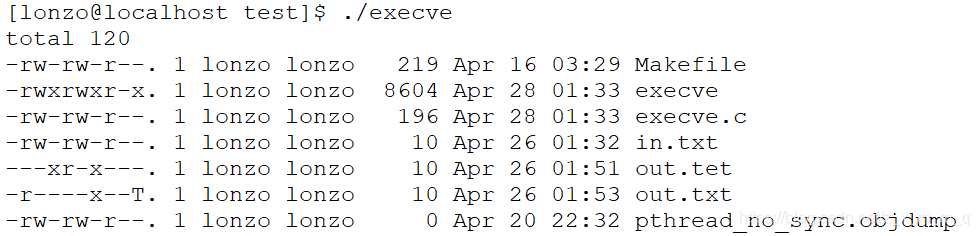
代码最后的 “666” 没有被打印出来, 这是因为 execve 函数的返回是特殊的。如果失败,则会返回 -1,如果成功,则永远不返回。
所以无需检查 execve 函数的返回值,只要返回,就必然是 -1。可以从 error 判断出错的原因。出错的可能情况非常之多,man 手册提供了 19 中不同的 error,罗列了 22 中调用失败的情景。很难记住,好在大部分不常见,常见的情况有以下几种:
- EACCES :这个是我们最容易想到的,就是第一个参数不是一个普通文件,或者对该文件没有可执行权限,或者目录结构中某一级目录不可搜索,或者文件所在的系统是以 MS_NOEXEC 标志挂载的。
- ENOENT :文件不存在
- ETXTBSY :存在其他进程尝试修改 filename 所指代的文件
- ENOEXEC :这个错误其实是一中比较高端的错误,文件存在,也可以执行,但是无法执行,比如说,Windows 下的可执行文件,拿到 Linux 下,调用 execve 来执行,文件的格式不对,就会返回这种错误
上面的 ENOEXEC 错误码,其实已经触及到 execve 函数的核心,及那些文件是可以被执行的,execve 函数又是如何执行的呢。。。
exec 家族
从内核的角度来说,提供 execve 函数就足够了,但是从应用层编程的角度来说,execve 函数不那么好使:
- 第一个参数必须是绝对路径或相对于当前工作目录的相对路径。习惯在 shell 下工作的用户觉得不太方便,因为日常工作都是写 ls、mkdir 之类命令的,没有人回去写 /bin/ls 或者 /bin/mkdir。shell 提供了环境变量 PATH,即可执行程序的查找路径,我们不必写出完整的路径,使用起来很方便,而 execve 函数享受不到这个福利,因此使用不便
- execve 函数的第三个参数是环境变量指针数组,用户使用 execve 函数编程时不得不自己负责环境变量,书写大量的 "key=value",但大部分情况下并不需要定制环境变量,只要使用当前的环境变量即可
正是为了提供相应的便利,所以用户层提供了 6 个函数,当然,这些函数本质上都是调用 execve 系统调用,只是使用的方法有所不同:
#include <unistd.h>
extern char **environ;
int execl(const char *path, const char *arg0, ... /*, (char *)0 */);
int execv(const char *path, char *const argv[]);
int execle(const char *path, const char *arg0, ... /*,
(char *)0, char *const envp[]*/);
int execve(const char *path, char *const argv[], char *const envp[]);
int execlp(const char *file, const char *arg0, ... /*, (char *)0 */);
int execvp(const char *file, char *const argv[]);
上述 6 个函数带 l 的表示参数采用列表,带 v 的表示参数采用数组;带 p 的表示可以使用环境变量 PATH,带 e 的表示要自己维护环境变量,而不使用当前环境变量。所以这些函数接口是比较好理解的。
使用实例如下:
#include <unistd.h>
char *const argv[] = {"ps","-l",NULL};
char *const envp[] = {"PATH=/bin:/usr/bin","TERM=console",NULL};
execl("/bin/ps","-l",NULL);
//带 p 的,可以使用环境变量 PATH,无需写全路径
execlp("ps","ps","-l",NULL);
//带 e 的需要自己组装环境变量
execle("/bin/ps","ps","-l",NULL,envp);
execv("/bin/ps",argv);
//带 p 的可以使用环境变量 PATH,无需写全路径
execvp("ps",argv,);
//带 e 的需要自己组装环境变量
execve("/bin/ps",argv,envp);execve 函数的内核实现
比较难,先放放。。。
exec 与信号
exec 系列函数,会将现有进程的所有文本段抛弃,直接奔向新生活。调用 exec 系列函数之前,进程可能执行过 signal 或 sigaction 函数,为某些信号注册了新的信号处理函数。一旦决裂,那些信号处理函数将无处可寻了。所以内核会为那些信号负责,那些曾经注册了新的处理函数的信号,将它们的处理函数重新设置为 SIG_DLF。
这里有一个特例,将 SIGCHLD 信号的处理函数设置为 SIG_IGN(忽略),调用 exec 系列函数之后,SIGCHLD 信号的处理函数保持 SIG_IGN 还是重新设置成 SIG_DFL 这点取决于操作系统。对于 Linux 来说,采用的是前者,即保持为 SIG_IGN。
执行 exec 之后进程继承的属性
执行 exec 系列函数的进程,其个性虽然叛逆,与过去做了决裂,但是也继承了过去的一些属性。执行 exec 系列函数之后,与进程相关的 ID 都保持不变。如果在调用 exec 之前,设置了告警(如调用了 alarm 函数),那么在告警时间到后,它仍然会产生一个信号。在执行 exec 后,挂起信号依然保留。创建文件时,掩码 umask 和执行 exec 之前一样。
system 函数
前面提到了 fork 函数、exec 系列函数、wait 函数。库将这些接口揉合在一起,提供了一个 system 函数。程序可以通过调用 system 函数,来执行任意的 shell 命令。可以让 C 程序很方便的调用其他语言编写的程序。关于这个函数,如何根据返回值定位失败的原因是个比较麻烦的问题。
system 函数接口
#include <stdlib.h>
int system(const char *command);system 函数与信号
总结
进程是操作系统非常重要的概念。和程序相比,进程是有生命的,是流动的。

















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









