



 在海量数据中,如何找出出现频率最高的前k个数或最大的前k个数?本文介绍了一种基于堆数据结构的解决方案,详细阐述了算法思想,并提供了具体的实现代码,展示了在有限空间下解决此类问题的方法,最后分析了时间复杂度。
在海量数据中,如何找出出现频率最高的前k个数或最大的前k个数?本文介绍了一种基于堆数据结构的解决方案,详细阐述了算法思想,并提供了具体的实现代码,展示了在有限空间下解决此类问题的方法,最后分析了时间复杂度。
提示:这里解决 top K 问题是基于堆数据结构下的,对这块还有问题的可以点以下链接:
https://blog.youkuaiyun.com/z_x_m_m_q/article/details/82320357
Top K问题:
Topk问题是一个经典的海量数据处理问题, 在海量数据中找出出现频率最高的前k个数,或者从海量数据中找出最大的前k个数,这类问题通常被称为Top K问题
比如,热搜上每天更新出的排行前10的热门搜索信息,陕西人最爱吃的水果种类等,都可以使用topK问题来解决
海量数据:
海量数据拥有的一大特点就是数据量比较大, 一般情况下内存空间是不足以一次性来存储的,或者处理海量数据是往往有空间上的限制
例如:面试官给你100W个数据,请找出其中最大的前K个数,并且现在仅仅有1M的空间?
在32位操作系统中,默认每个数据为4字节,很显然 1M 的空间是存放不了要处理的目标数据
算法思想:
从大量数据中找出前 K 个最大数为例来说明:
首先以给定数据中的前 K 个数建立小堆,然后从 K+1 个数据开始与堆顶元素作比较,小于或等于堆顶元素时,保持建立的小堆不变;大于堆顶元素时,将该数据与堆顶元素交换,此时有可能破坏了小堆的有序性,需要从堆顶元素开始来一次向下调整使堆恢复成小堆
算法代码:
这里我提供一个 main 函数开始的完整的代码,还有部分注释,供大家参考
#include"pch.h"
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
#include<time.h>
void Swap(int* x,int* y) //交换函数,建议使用这种方式交换
{
int tmp = *x;
*x = *y;
*y = tmp;
}
void HeapAdjustDown(int* a,int n,int root) //堆的向下调整函数
{
int parent = root;
int child = 2 * parent + 1;
while (child < n) {
if (child+1 < n && a[child+1] < a[child])
++child;
if (a[child] < a[parent])
Swap(&a[child], &a[parent]);
else
break;
parent = child;
child = 2 * parent + 1;
}
}
void Top_K(int* a,int n,int k)
{
int i = 0;
int* hp = (int*)malloc(sizeof(int)*k); //用于始终存储堆中的 K 个数,记得释放空间
for (i = 0;i < k;++i)
hp[i] = a[i];
for (i = (k-2)/2;i >= 0;--i) //建堆
{
HeapAdjustDown(hp,k,i);
}
for (i = k;i < n;++i) //从 K+1 个数开始与堆顶元素一一比较
{
if (a[i] > hp[0]) //a[0]:堆顶元素
{
hp[0] = a[i];
HeapAdjustDown(hp, k, 0);
}
}
for (i = 0;i < k;++i) //简单的看下输出结果
{
printf("%d ",hp[i]);
}
free(hp);
hp = NULL;
}
int main()
{
int i = 0;
int a[1024];
srand((unsigned)time(NULL));
for (i = 0;i < 1024;++i)
{
a[i] = rand();
}
Top_K(a,sizeof(a)/sizeof(a[0]),8);
return 0;
}结果展示:
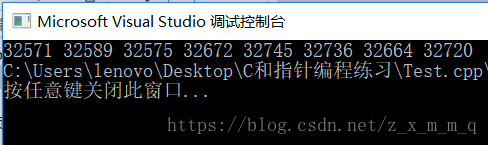
上面从大量数据中找出的最大的 8 个数显然满足小堆的性质。
时间复杂度:
基于堆数据结构下的 Top K 问题时间复杂度为:,这是很显然的

















 1764
1764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









