




NanoLog是什么?
github源码:https://github.com/PlatformLab/NanoLog
nano是高吞吐量,超低延时的日志系统,使用printf风格打印日志;可以达到 8000w/s的吞吐量,并且单条日志打印耗时的tp50指标仅7ns,并且日志输出为压缩后的二进制格式,比文本日志体积大大减少
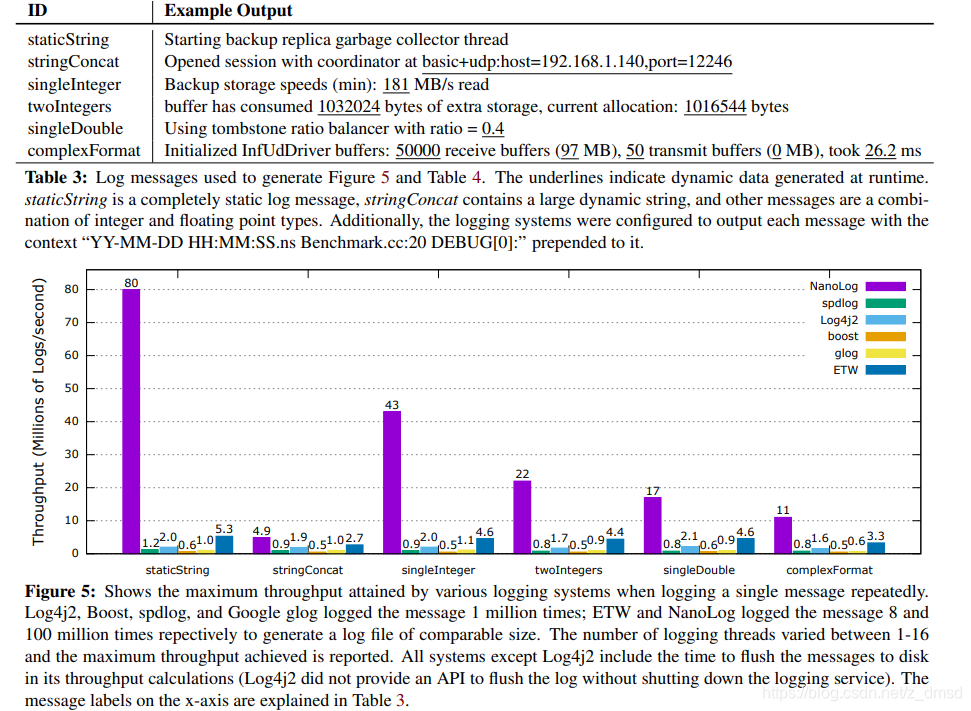
和普通日志系统对比
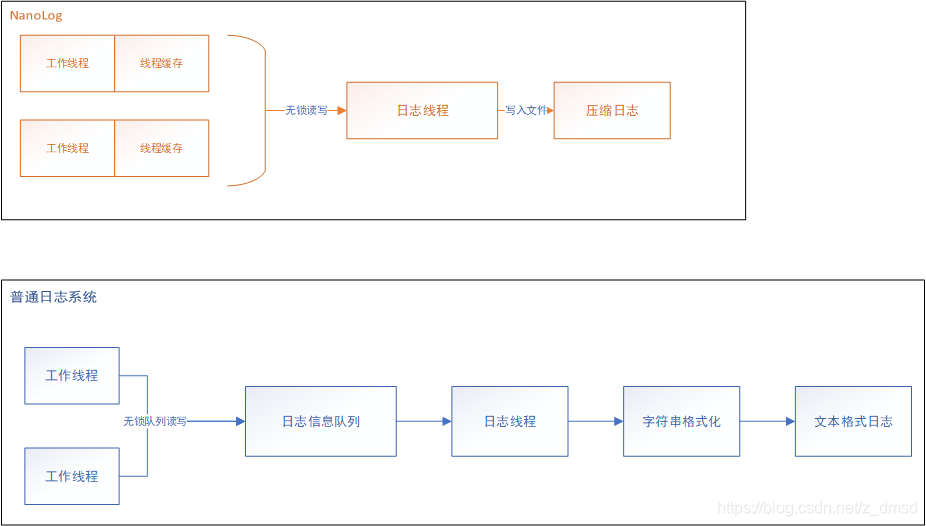
图中两个都是日志系统运行时的流程,可以发现,普通日志系统比nanolog多了两个较为耗时的流程:加锁,字符串格式化;
NanoLog则是将这两个步骤完全在运行时去除,这也是为什么它比其他日志系统延迟更低,吞吐量更高的重要原因;
当然,它也有一些缺点:输出的日志文件是压缩格式的,即二进制格式,不方便阅读,需要借助日志解压缩工具(随源码提供)进行解析,不过,对于线上发布后的服务,实时查看日志并不是必需的;
为什么快
线程局部的日志缓存 —解决加锁问题
nanolog为每个线程都创建了一个线程局部的日志缓存,也就是下面的StagingBuffer,
这里有意思的是,线程局部的缓存利用了C++11中的 thread_local关键字进行创建,与此同时也使用了 gcc特有的关键字 __thread,关于这两者的细微区别,可以看:
What is the performance penalty of C++11 thread_local variables in GCC 4.8?
// 核心类,运行时的一些日志内存管理,后台日志线程管理
class RuntimeLogger {
private:
// Storage for staging uncompressed log statements for compression
static __thread StagingBuffer *stagingBuffer;
// Destroys the __thread StagingBuffer upon its own destruction, which
// is synchronized with thread death
static thread_local StagingBufferDestroyer sbc;
//xxx
}
光有线程局部的缓存,日志线程就没法访问线程的缓存了,所以还需要一个全局的线程缓存列表,供日志线程访问
因为线程局部缓存只会创建一次,因此虽然缓存列表是全局需加锁的,日志线程访问它时,加锁的消耗也是可以忽略不记的;
// Globally the thread-local stagingBuffers
std::vector<StagingBuffer *> threadBuffers;
inline void
ensureStagingBufferAllocated() {
if (stagingBuffer == nullptr) {
std::unique_lock<std::mutex> guard(bufferMutex);
uint32_t bufferId = nextBufferId++;
// Unlocked for the expensive StagingBuffer allocation
guard.unlock();
stagingBuffer = new StagingBuffer(bufferId);
guard.lock();
threadBuffers.push_back(stagingBuffer);
}
}
静态信息和动态信息分离,动态信息延后处理
静态信息处理
下面是Nanolog在工作线程中用于写日志的宏,
#define NANO_LOG(severity, format, ...) do {
\
constexpr int numNibbles = NanoLogInternal::getNumNibblesNeeded(format); \
constexpr int nParams = NanoLogInternal::countFmtParams(format); \
\
/*** Very Important*** These must be 'static' so that we can save pointers
* to these variables and have them persist beyond the invocation.
* The static logId is used to forever associate this local scope (tied
* to an expansion of #NANO_LOG) with an id and the paramTypes array is
* used by the compression function, which is invoked in another thread
* at a much later time. */ \
static constexpr std::array<NanoLogInternal::ParamType, nParams> paramTypes = \
NanoLogInternal::analyzeFormatString<nParams>(format); \
static int logId = NanoLogInternal::UNASSIGNED_LOGID; \
\
if (NanoLog::severity > NanoLog::getLogLevel()) \
break; \
\
/* Triggers the GNU printf checker by passing it into a no-op function.
* Trick: This call is surrounded by an if false so that the VA_ARGS don't
* evaluate for cases like '++i'.*/ \
if (false) {
NanoLogInternal::checkFormat(format, ##__VA_ARGS__); } /*NOLINT(cppcoreguidelines-pro-type-vararg, hicpp-vararg)*/\
\
NanoLogInternal::log(logId, __FILE__, __LINE__, NanoLog::severity, format, \
numNibbles, paramTypes, ##__VA_ARGS__); \
} while(0)
这里获取了几个信息
- numNibbles:格式化字符串中,非字符串类型的参数个数,比如
%d,%l等参数的个数 - nParams: 格式化字符串中,参数的个数,相当于是
%的个数
上面这两个都是在编译期即可计算好的,意味着运行时是无消耗的
- paramTypes:格式化字符串中,所有参数的参数类型, 即将
%..映射为NanoLog内部定义的ParamType - logId:当前日志的格式化字符串的logId,可以理解为一个编号,因为运行时这个信息是不变的,因此我们可以把这些信息存储下来,需要时使用logId索引即可
这里需要注意到,logId是静态的,意味着logId编号会在当前作用域记录下来,即工作线程打印日志的地方,这是必须的,因为运行时需要保证每个打印日志的地方能使用正确的logId获取到正确的格式化字符串信息等
template< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









