






在上篇文章中对Stable Diffusion进行了初步的认识,也给出了使用案例,这篇文章将进一步的去刨析一下SD模型。
SD模型的组成
在之前也讲过了,SD由CLIP、UNet、Schedule,VAE组成。再来回顾一下知识点:
1.CLIP Text Encoder(文本编码器)
作用:将文本信息进行编码生成对应的特征矩阵方便输入到SD模型中。
2.VAE Encoder(变分自编码器)
作用:生成Latent Feature(隐空间特征)和文本特征同时作为模型输入。如果是图生图任务则将图像进行编码生成Latent Feature;如果是文生图则用随机生成的高斯噪声矩阵作为Latent Feature作为输入。【也就是在输入SD模型前有两个输入,文本特征和隐空间特征】
3.U-Net网络
作用:用于不断地预测噪声,并在每次预测噪声过程中加入文本语义特征。
4.Schedule
作用:对UNet预测的噪声进行优化处理(动态调整预测的噪声,控制U-Net预测噪声的强度)
5.VAE Decoder(解码器)
作用:将最终得到的Latent Feature经过解码器生成图像。
在SD的迭代过程中(去噪过程),噪声会不断的减少,图像信息和文本语义信息会不断的增加。
也就是说Unet的输入有两部分组成,一个是latent、一个是输入文本特征(prompt)。
1.图生图:需要将图像通过VAE encoder生成latent,并与文本特征进行输入
2.文生图:使用随机高斯噪声代替图像latent,并与文本特征进行输入。
在上一篇文章中可以教了大家如何快速使用diffusers搭建SD模型。但这种方法不够灵活,我们对每个部分进行分析,在这篇文章中会分模块加载Model并手动搭建SD模型。
这里以文生图为例。(文末会附上完整的代码)
CLIP Model单独加载
在生成文本特征的时候需要有两个步骤:1.prompt->token 2.token->text_embedding
# 1.prompt特征提取
# 1.1 prompt转token
text_tokenizer = CLIPTokenizer.from_pretrained(sd_weight_path, subfolder="tokenizer")
text_token_ids = text_tokenizer(
prompt,
padding='max_length',
max_length=text_tokenizer.model_max_length,
truncation=True,
return_tensors='pt'
).input_ids
# 1.2提取prompt_embedding
text_encoder = CLIPTextModel.from_pretrained(sd_weight_path,subfolder='text_encoder')
text_embeddings = text_encoder(text_token_ids)[0]Schedule单独加载
Schedule是和UNet相结合的,用于优化不同时间步t时刻的latent。
或者可以这样理解,不同时间t对应不同的噪声级别和潜在表示。缩放输入可以确保输入在每个时间步都是标准化的,使其对应当前时间t所对应的噪声分布,使模型能够稳定地处理不同程度的噪声。
这里我的理解感觉和CNN中的BN层有点相似,但也有不同,这里我谈一下自己的理解:
扩散模型中的schedule,对输入进行缩放的目的是控制和调整不同时间t对应的噪声程度,使得latent在每个时间t的数据分布和训练时是一样的,从而可以稳定的去噪。也就是和BN类似,都是对输入进行标准化或者缩放使数据在特定分布下更稳定。但不同的是,BN层是为了解决梯度消失和爆炸,加快训练速度,而扩散模型的缩放是每个时刻t对latent的缩放,为的是控制噪声水平。
# 2.单独加载调度算法,生成噪声表
scheduler = PNDMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
scheduler.set_timesteps(25)
timesteps = scheduler.timestepsUNet单独加载
# 3.单独加载UNet
unet = UNet2DConditionModel.from_pretrained(sd_weight_path,subfolder='unet')UNet预测噪声
UNet做噪声预测的时候代码如下,其中latents_model_input是经过Schedule优化后的特征图,t是对应的时间t,text_embeddings是输入的文本特征。
输出是预测噪声,然后对噪声进行分块(chunk操作)得到两个噪声,一个是无条件噪声,一个是条件噪声。
无条件噪声:
无条件噪声是指模型在没有任何(如文本、标签等)输入情况下,单纯的基于latents得到噪声,这部分噪声预测代表了生成过程中的基础噪声水平。
条件噪声:
条件噪声预测是模型在给定某种条件(如文本嵌入)输入的情况下,基于潜在变量和这些条件预测的噪声。这部分噪声预测代表了生成过程在特定条件下的噪声水平。
noise_pred = unet(
latents_model_input,
t,
encoder_hidden_states=text_embeddings,
cross_attention_kwargs=None,
return_dict=False,
)[0] # 预测噪声
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
# 7.5为相关因子
noise_pred = noise_pred_uncond + 7.5 * (noise_pred_text - noise_pred_uncond)VAE单独加载
# 4.单独加载VAE
# 进行解码
vae = AutoencoderKL.from_pretrained(sd_weight_path, subfolder='vae').to("cuda", dtype=torch.float32)去噪可视化
比如这里输入的prompt为:'a girl, beautiful',neg pormpt为空时,对每次去噪后的latents可视化,代码如下:
# 3.单独加载UNet
unet = UNet2DConditionModel.from_pretrained(sd_weight_path,subfolder='unet')
for i, t in tqdm(enumerate(timesteps)):
latents_model_input = torch.cat([latents] * 2)
latents_model_input = scheduler.scale_model_input(latents_model_input, t)
noise_pred = unet(
latents_model_input,
t,
encoder_hidden_states=text_embeddings,
cross_attention_kwargs=None,
return_dict=False,
)[0] # 预测噪声
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
# 7.5为相关因子
noise_pred = noise_pred_uncond + 7.5 * (noise_pred_text - noise_pred_uncond)
# x_t->x_t-1 去噪操作
latents = scheduler.step(noise_pred, t, latents,return_dict=False)[0]
save_noise_pred_feat(latents, i)可视化结果(部分图):
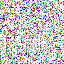 | 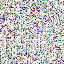 | 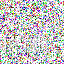 | 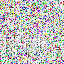 | 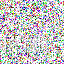 |
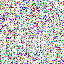 | 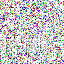 | 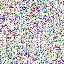 | 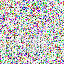 | 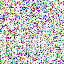 |
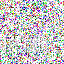 | 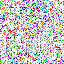 | 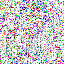 | 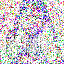 | 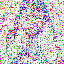 |
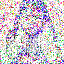 | 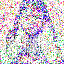 | 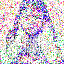 | 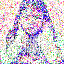 | 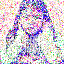 |
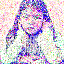 | 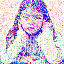 | 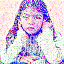 |  |  |
latents解码
# 进行解码
vae = AutoencoderKL.from_pretrained(sd_weight_path, subfolder='vae').to("cuda", dtype=torch.float32)
image = vae.decode(latents.to("cuda", dtype=torch.float32) / vae.config.scaling_factor, return_dict=False)[0]最终解码的效果图如下:
(大体还是可以,就是可以看到多了一只手,我这里neg prompt为空)

比如这里输入的neg_prompt为:
neg_prompt = 'extra limbs, extra arms, extra hands, disfigured, distorted anatomy, unnatural proportions, unrealistic, malformed'
生成图像为:

如果此时输入的neg_prompt为:
neg_prompt = 'extra limbs, extra arms, extra hands, disfigured, distorted anatomy, unnatural proportions, unrealistic, malformed, unnatural expression, creepy eyes, unrealistic facial features, disfigured face, distorted expression, awkward smile, disproportionate eyes, unrealistic gaze, malformed eyes'
生成图像如下:

完整代码
import torch
from diffusers.pipelines.alt_diffusion.pipeline_alt_diffusion import rescale_noise_cfg
from diffusers.utils import randn_tensor
from transformers import CLIPTokenizer, CLIPTextModel
from diffusers import UNet2DConditionModel, PNDMScheduler, LMSDiscreteScheduler, AutoencoderKL
from tqdm import tqdm
import numpy as np
from PIL import Image
import cv2
'''
这是一个最小化实现算法
快速学习sd过程
'''
# 用以保存特征图
def save_noise_pred_feat(noise_pred, save_name):
noise_pred = (noise_pred / 2 + 0.5).clamp(0, 1)
# 将Tensor转换为 NumPy 数组
noise_pred_np = noise_pred.detach().cpu().numpy()
# 将通道数从第二个维度移动到最后一个维度
# (前提假设通道数是第二个维度)
noise_pred_np = np.moveaxis(noise_pred_np, 1, -1)
# 反归一化
noise_pred_np = (noise_pred_np * 255).round().astype(np.uint8)
# 如果你想将所有特征图合并成一个图像保存,可以使用 PIL 的拼接功能
# 这里仅作示例
combined_img = Image.fromarray(np.concatenate(noise_pred_np, axis=1))
combined_img.save(f'{save_name}_combined_feature_map.png')
@torch.no_grad()
def UNET():
# 随机种子
generator = torch.Generator("cpu").manual_seed(1024)
# 权重路径
sd_weight_path = 'F:/Stable_webui/stable-diffusion-webui/models/Stable-diffusion/stable-diffusion-v1-5'
# prompt
prompt = 'a girl, beautiful'
# neg prompt
neg_prompt = 'extra limbs, extra arms, extra hands, disfigured, distorted anatomy, unnatural proportions, unrealistic, malformed, unnatural expression, creepy eyes, unrealistic facial features, disfigured face, distorted expression, awkward smile, disproportionate eyes, unrealistic gaze, malformed eyes'
# 1.prompt特征提取
# 1.1 prompt转token
text_tokenizer = CLIPTokenizer.from_pretrained(sd_weight_path, subfolder="tokenizer")
text_token_ids = text_tokenizer(
prompt,
padding='max_length',
max_length=text_tokenizer.model_max_length,
truncation=True,
return_tensors='pt'
).input_ids
neg_token_ids = text_tokenizer(
neg_prompt,
padding='max_length',
max_length=77,
truncation=True,
return_tensors='pt'
)
# 1.2提取prompt_embedding
text_encoder = CLIPTextModel.from_pretrained(sd_weight_path,subfolder='text_encoder')
text_embeddings = text_encoder(text_token_ids)[0]
text_embeddings = text_embeddings.repeat(1,1,1)
text_embeddings = text_embeddings.view(1*1,77,-1)
neg_prompt_embeds = text_encoder(
neg_token_ids.input_ids,
attention_mask=None,
)[0]
del text_encoder, text_tokenizer
neg_prompt_embeds = neg_prompt_embeds.repeat(1, 1, 1)
neg_prompt_embeds = neg_prompt_embeds.view(1*1, 77, -1)
# 文本特征向量
text_embeddings = torch.cat([neg_prompt_embeds, text_embeddings])
# 2.单独加载调度算法,生成噪声表,在总的时间步数num_train_timesteps中,这个噪声表的值在beta_start到beta_end中,对应公式的αt
scheduler = PNDMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
scheduler.set_timesteps(25)
timesteps = scheduler.timesteps
print("timesteps :" + str(timesteps))
# 如果是文生图,那么就用一个随机噪声来代替这个图
latents = randn_tensor((1, 4, 64, 64), generator=generator, dtype=torch.float32)
latents = scheduler.init_noise_sigma * latents
# 3.单独加载UNet
unet = UNet2DConditionModel.from_pretrained(sd_weight_path,subfolder='unet')
for i, t in tqdm(enumerate(timesteps)):
latents_model_input = torch.cat([latents] * 2)
latents_model_input = scheduler.scale_model_input(latents_model_input, t)
noise_pred = unet(
latents_model_input,
t,
encoder_hidden_states=text_embeddings,
cross_attention_kwargs=None,
return_dict=False,
)[0] # 预测噪声
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
# 7.5为相关因子
noise_pred = noise_pred_uncond + 7.5 * (noise_pred_text - noise_pred_uncond)
# x_t->x_t-1 去噪操作
latents = scheduler.step(noise_pred, t, latents,return_dict=False)[0]
# save_noise_pred_feat(latents, i)
# 4.单独加载VAE
# 进行解码
vae = AutoencoderKL.from_pretrained(sd_weight_path, subfolder='vae').to("cuda", dtype=torch.float32)
image = vae.decode(latents.to("cuda", dtype=torch.float32) / vae.config.scaling_factor, return_dict=False)[0]
# 后处理
rec_image = (image / 2 + 0.5).clamp(0, 1) # 归一化到0~1
rec_image = rec_image.cpu().permute(0, 2, 3, 1).numpy()
# 反归一化
rec_image = (rec_image * 255).round().astype("uint8")
rec_image = rec_image[0]
# 保存重建后图像
cv2.imwrite("mysd.png", cv2.cvtColor(rec_image, cv2.COLOR_RGB2BGR))
torch.cuda.empty_cache()
UNET()

















 3469
3469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











