







在上一篇文章中,已经利用DataLoader加载预处理后的数据集
【目标检测之数据集加载】利用DataLoader加载已预处理后的数据集【附代码】_z240626191s的博客-优快云博客
接下来将从零开始,搭建自己的目标检测网络,实现训练和预测。【声明:这里借鉴SSD目标检测网络,同时移除了最后的4个特征层,只将VGG16最终的特征层用于预测】
目录
目标检测网络
目标检测网络:VGG16
定义VGG16
base = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512]
def vgg(i):
layers = [] # 用于存放vgg网络的list
in_channels = i # 最前面那层的维度--300*300*3,因此i=3
for v in base: # 在通道列表中进行遍历
if v == 'M': # 池化,补不补边界
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else: # 判断是否在池化层,卷积层都是3*3,v是输出通道数
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
# 每层卷积后使用ReLU激活函数
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6) # 通道(1024)膨胀,用卷积层代替全连接层
# # dilation=卷积核元素之间的间距,扩大卷积感受野的范围,没有增加卷积size,使用了空洞数为6的空洞卷积
conv7 = nn.Conv2d(1024, 1024, kernel_size=1) # 在conv7输出19*19的特征层
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
# layers有20层 VGG前17层,加上pool5,conv6,conv7
return layers建立自己的模型Mymodel
这里需要继承nn.Module
参数说明:
phase主要用来判断模型是处于训练阶段还是测试阶段,但为test字段时,直接用原SSD的Detect()函数就可以了。
num_classes:类的数量【参考了SSD,所以类别数量应为:自己的类数量+1(包含了背景类)】
confidence:置信度
nms_iou:NMS阈值
注意:在self.backbone = nn.ModuleList(vgg(3))是调用上面定义的vgg16网络代码,同时需要加上nn.ModuleList(),不然会报错。
PriorBox的代码后面将给出
class Mymodel(nn.Module):
def __init__(self, phase, num_classes,confidence, nms_iou):
super(Mymodel, self).__init__()
self.phase = phase
self.cfg = Config
self.num_classes = num_classes
self.backbone = nn.ModuleList(vgg(3))
box = [4] # 最后一个特征层锚框数量
self.priorbox = PriorBox(self.cfg)
with torch.no_grad():
self.priors = Variable(self.priorbox.forward())
loc_layers = [nn.Conv2d(self.backbone[-2].out_channels, box[0] * 4, kernel_size=3,padding=1)]
conf_layers = [nn.Conv2d(self.backbone[-2].out_channels, box[0] * num_classes, kernel_size = 3, padding = 1)]
self.loc = nn.ModuleList(loc_layers)
self.conf = nn.ModuleList(conf_layers)
if phase == 'test':
self.softmax = nn.Softmax(dim=-1) # 所有类的概率相加为1
# Detect(num_classes,bkg_label,top_k,conf_thresh,nms_thresh)
# top_k:一张图片中,每一类的预测框的数量
# conf_thresh 置信度阈值
# nms_thresh:值越小表示要求的预测框重叠度越小,0.0表示不允许重叠
self.detect = Detect(num_classes, 0, 200, confidence, nms_iou)
def forward(self, x):
loc = list() # 用来存放位置回归结果
conf = list() # 用来存放分类回归结果
featrue = list() # 用来存储特征层
for k in range(len(self.backbone)):
x = self.backbone[k](x)
featrue.append(x) # 最后一个特征层为(batch_size,1024,19,19)
for (x, l, c) in zip(featrue, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == "test":
output = self.detect(
loc.view(loc.size(0), -1, 4),
self.softmax(conf.view(conf.size(0), -1, self.num_classes)),
self.priors
)
else: # 训练时期
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
self.priors
)
return output打印一下网络模型:
Mymodel(
(backbone): ModuleList(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(31): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6))
(32): ReLU(inplace=True)
(33): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
(34): ReLU(inplace=True)
)
(loc): ModuleList(
(0): Conv2d(1024, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(conf): ModuleList(
(0): Conv2d(1024, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
现在整体的网络就基本搭建完,接下来是定义先验框。
先验框的定义
这里先验框的定义是参考了SSD中的定义方法,当然大家也可以用YOLO的(但需要先聚类一下生成锚框),或者像centernet一样变为无锚框网络(我试了一下该方法,检测效果不太好)。
首先需要对生成的特征层生成网格点坐标矩阵,因为大小为19*19,所以每行每列将产生19个点,可以将特征层生成的网格画出来更明显的展示一下:
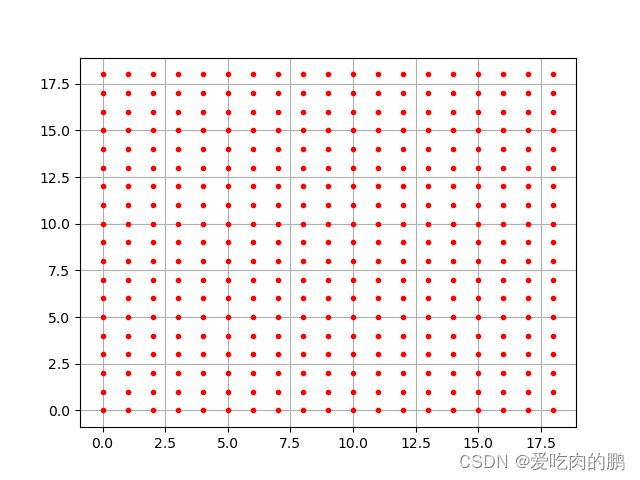
网格点坐标矩阵:网格点即网格之间交叉的点,然后这个点用坐标形式表示,将所有的x坐标放在一个X矩阵中,y坐标统一放一个Y的矩阵中。
我们已经知道了上述的坐标,那我们就可以计算得到每个网格的中心点位置。
然后我们可以计算一下每个网格中获得的默认框相对于原始图像的比例Sk值,代码中的self.min_sizes和self.max_sizes分别对应最小和最大先验框的尺度,这个尺度后面会说是怎么计算来了 。代码中的小尺寸和大尺寸正方形是每个网格产生的默认先验框,再通过aspect_ratios又会产生2个尺寸的长方形先验框,一共4个先验框。
参数self.steps=[16]是一个步长,特征图距离原始图大小的距离,或者是映射关系,比如现在的特征层大小为19*19,原始图300*300,则19*16≈300。
class PriorBox(object):
def __init__(self, cfg):
super(PriorBox, self).__init__()
# 获得输入图片的大小,默认为300x300
self.image_size = 300
self.num_priors = 1
self.variance = [0.1]
self.feature_maps = [19] # conv7输出的特征层大小
self.min_sizes = [60] # 对应最小的先验框尺寸
self.max_sizes = [111] # # 对应最大的先验框尺寸
self.steps = [16] # 相当于该特征层和原图的映射关系
self.aspect_ratios = [[2]] # 横纵比
self.clip = cfg['clip']
for v in self.variance:
if v <= 0:
raise ValueError('Variances must be greater than 0')
def forward(self):
mean = []
#----------------------------------------#
# 获得1个大小为19*19的有效特征层用于预测
#----------------------------------------#
for k, f in enumerate(self.feature_maps):
#----------------------------------------#
# 对特征层生成网格点坐标矩阵
#----------------------------------------#
x,y = np.meshgrid(np.arange(f),np.arange(f))
x = x.reshape(-1)
y = y.reshape(-1)
#----------------------------------------#
# 所有先验框均为归一化的形式
# 即在0-1之间
#----------------------------------------#
for i, j in zip(y,x):
f_k = self.image_size / self.steps[k]
#----------------------------------------#
# 计算网格的中心
#----------------------------------------#
cx = (j + 0.5) / f_k
cy = (i + 0.5) / f_k
#----------------------------------------#
# 获得小的正方形
#----------------------------------------#
s_k = self.min_sizes[k]/self.image_size
mean += [cx, cy, s_k, s_k]
#----------------------------------------#
# 获得大的正方形
#----------------------------------------#
s_k_prime = sqrt(s_k * (self.max_sizes[k]/self.image_size))
mean += [cx, cy, s_k_prime, s_k_prime]
#----------------------------------------#
# 获得两个的长方形
#----------------------------------------#
for ar in self.aspect_ratios[k]:
mean += [cx, cy, s_k*sqrt(ar), s_k/sqrt(ar)]
mean += [cx, cy, s_k/sqrt(ar), s_k*sqrt(ar)]
output = torch.Tensor(mean).view(-1, 4)
# 产生1444个先验框:19*19*4=1444
if self.clip:
output.clamp_(max=1, min=0)
return output好了,现在我们要说一下min_sizes=[60]和max_size=[111]怎么计算来的 :
在SSD文中的ratio取[0.2,0.9]但在实际中,扩大了10陪。即范围为【20,90】
所以计算conv7特征层:min_sizes=min_dim*ratio/100=300*20/100=60,max_sizes=min_dim*(ratio+step)/100=300*(20+17)/100=111;注意这里的step不是steps,不一样。这里的step是SSD文中提到的这个公式:
Sk= Smin + (Smax-Smin)/(m-1) * (k-1),k∈[1,m],Smin=0.2,Smax=0.9
(Smax-Smin)/(m-1)=17,表示在[20,90]每17步取一次,即20,37,57,71,88各取一个Sk,用这些比例数字除以100,再乘原始图像大小。所以也可以这样算:如果是conv7,那么Sk等于20,min_sizes=20/100 * 300 = 60。
可以参考:关于SSD默认框产生的详细解读_anqian123321的博客-优快云博客_ssd先验框
损失函数
损失函数这里我直接用的SSD中的损失函数,这里就不再过多叙述,可以直接看原论文。
class MultiBoxLoss(nn.Module):
def __init__(self, num_classes, overlap_thresh, prior_for_matching,
bkg_label, neg_mining, neg_pos, neg_overlap, encode_target,
use_gpu=True, negatives_for_hard=100.0):
super(MultiBoxLoss, self).__init__()
self.use_gpu = use_gpu
self.num_classes = num_classes
self.threshold = overlap_thresh
self.background_label = bkg_label
self.encode_target = encode_target
self.use_prior_for_matching = prior_for_matching
self.do_neg_mining = neg_mining
self.negpos_ratio = neg_pos
self.neg_overlap = neg_overlap
self.negatives_for_hard = negatives_for_hard
self.variance = Config['variance']
#@torchsnooper.snoop()
def forward(self, predictions, targets):
#--------------------------------------------------#
# 取出预测结果的三个值:回归信息,置信度,先验框
#--------------------------------------------------#
loc_data, conf_data, priors = predictions
#--------------------------------------------------#
# 计算出batch_size和先验框的数量
#--------------------------------------------------#
num = loc_data.size(0)
num_priors = (priors.size(0))
#--------------------------------------------------#
# 创建一个tensor进行处理
#--------------------------------------------------#
loc_t = torch.zeros(num, num_priors, 4).type(torch.FloatTensor)
conf_t = torch.zeros(num, num_priors).long()
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
priors = priors.cuda()
for idx in range(num):
# 获得真实框与标签 targets[x1,y1,x2,y2,label]
truths = targets[idx][:, :-1] # 获取(x1,y1,x2,y2)坐标
labels = targets[idx][:, -1] # 获取(label)
if(len(truths)==0):
continue
# 获得先验框
defaults = priors
#--------------------------------------------------#
# 利用真实框和先验框进行匹配。
# 如果真实框和先验框的重合度较高,则认为匹配上了。
# 该先验框用于负责检测出该真实框。
#--------------------------------------------------#
match(self.threshold, truths, defaults, self.variance, labels, loc_t, conf_t, idx)
#--------------------------------------------------#
# 转化成Variable
# loc_t (num, num_priors, 4)
# conf_t (num, num_priors)
#--------------------------------------------------#
loc_t = Variable(loc_t, requires_grad=False)
conf_t = Variable(conf_t, requires_grad=False)
# 所有conf_t>0的地方,代表内部包含物体
pos = conf_t > 0
#--------------------------------------------------#
# 求和得到每一个图片内部有多少正样本
# num_pos (num, )
#--------------------------------------------------#
num_pos = pos.sum(dim=1, keepdim=True)
#--------------------------------------------------#
# 取出所有的正样本,并计算loss
# pos_idx (num, num_priors, 4)
#--------------------------------------------------#
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
#--------------------------------------------------#
# batch_conf (num * num_priors, num_classes)
# loss_c (num, num_priors)
#--------------------------------------------------#
batch_conf = conf_data.view(-1, self.num_classes)
# 这个地方是在寻找难分类的先验框
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
loss_c = loss_c.view(num, -1)
# 难分类的先验框不把正样本考虑进去,只考虑难分类的负样本
loss_c[pos] = 0
#--------------------------------------------------#
# loss_idx (num, num_priors)
# idx_rank (num, num_priors)
#--------------------------------------------------#
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
#--------------------------------------------------#
# 求和得到每一个图片内部有多少正样本
# num_pos (num, )
# neg (num, num_priors)
#--------------------------------------------------#
num_pos = pos.long().sum(1, keepdim=True)
# 限制负样本数量
num_neg = torch.clamp(self.negpos_ratio * num_pos, max = pos.size(1) - 1)
num_neg[num_neg.eq(0)] = self.negatives_for_hard
neg = idx_rank < num_neg.expand_as(idx_rank)
#--------------------------------------------------#
# 求和得到每一个图片内部有多少正样本
# pos_idx (num, num_priors, num_classes)
# neg_idx (num, num_priors, num_classes)
#--------------------------------------------------#
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
# 选取出用于训练的正样本与负样本,计算loss
conf_p = conf_data[(pos_idx + neg_idx).gt(0)].view(-1, self.num_classes)
targets_weighted = conf_t[(pos + neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)
N = torch.max(num_pos.data.sum(), torch.ones_like(num_pos.data.sum()))
loss_l /= N
loss_c /= N
# embed()
return loss_l, loss_c训练
训练主函数
首先是模型实例化,调用损失函数等,传入一些形参。然后如果要加载预权重,比如VGG16或者原SSD的权重,直接加载或报关于keys错误。因此,需要将原
pretrained_dict = {k:v for k,v in pretrained_dict.items() if np.shape(model_dict[k])== np.shape(pretrained_dict[k])}
改为:
pretrained_dict = {k:v for k,v in pretrained_dict.items() if pretrained_dict.keys()==model_dict.keys()}
意思只有键值名字相等才可以加载,不是比对形状。
if __name__ == '__main__':
cuda = True
criterion = MultiBoxLoss(2, 0.5, True, 0, True, 3, 0.5, False, cuda) # 定义损失函数
model = Mymodel("train", num_classes=2, confidence=0.6, nms_iou=0.5)
model_path = r'./nets/ssd_weights.pth'
model_dict = model.state_dict()
device = torch.device('cuda')
pretrained_dict = torch.load(model_path, map_location=device)
#pretrained_dict = {k:v for k,v in pretrained_dict.items() if np.shape(model_dict[k])== np.shape(pretrained_dict[k])}
pretrained_dict = {k:v for k,v in pretrained_dict.items() if pretrained_dict.keys()==model_dict.keys()}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
print("完成预权重的加载")
model.to(device)
batch_size = 2
annotation_path = r'2007_train.txt'
with open(annotation_path, encoding='utf-8') as f:
lines = f.readlines()
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
val = 0.1
num_val = int(len(lines) * val)
num_train = len(lines) - num_val
model.train()
Use_Data_Loader = True
lr = 5e-4
optimizer = optim.Adam(model.parameters(), lr=lr)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.92)
Init_Epoch = 0
Freeze_Epoch = 50
if Use_Data_Loader:
train_dataset = MyDatasets(lines[:num_train], (300, 300),
True) # train_dataset返回数据集和标签(且这个是可以迭代的)
train_data = DataLoader(train_dataset, batch_size, False, num_workers=4, pin_memory=True,
collate_fn=my_dataset_collate)
val_dataset = MyDatasets(lines[num_train:], (300, 300), False)
val_data = DataLoader(val_dataset, shuffle=True, batch_size=batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=my_dataset_collate)
epoch_size = num_train // batch_size
epoch_size_val = num_val // batch_size
for param in model.backbone.parameters():
param.requires_grad = True
for epoch in range(50):
do_train(model, criterion, epoch, epoch_size, epoch_size_val, train_data, val_data, Freeze_Epoch, cuda)
lr_scheduler.step()训练函数:
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def do_train(model, criterion, epoch, epoch_size, epoch_size_val, gen, genval, Epoch, cuda):
loc_loss = 0
conf_loss = 0
loc_loss_val = 0
conf_loss_val = 0
model.train()
with tqdm(total=epoch_size, desc=f'Epoch {epoch + 1}/{Epoch}', postfix=dict, mininterval=0.3) as pbar:
for iteration, batch in enumerate(gen):
if iteration >= epoch_size:
break
images, targets = batch[0], batch[1] # images[batch_size,3,300,300]
# targets是一个列表,有5个向量(x1,y1,x2,y2,标签)
with torch.no_grad():
if cuda:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor)).cuda()
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)).cuda() for ann in targets]
else:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor))
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets]
output = model(
images) # output返回loc(batch_size,num_anchors,4[坐标]),conf(batch_size,num_anchors,num_classes)
optimizer.zero_grad()
loss_l, loss_c = criterion(output, targets)
loss = loss_l + loss_c
# ----------------------#
# 反向传播
# ----------------------#
loss.backward()
optimizer.step()
loc_loss += loss_l.item()
conf_loss += loss_c.item()
pbar.set_postfix(**{'loc_loss': loc_loss / (iteration + 1),
'conf_loss': conf_loss / (iteration + 1),
'lr': get_lr(optimizer)})
pbar.update(1)
model.eval()
print('Start Validation')
with tqdm(total=epoch_size_val, desc=f'Epoch {epoch + 1}/{Epoch}', postfix=dict, mininterval=0.3) as pbar:
for iteration, batch in enumerate(genval):
if iteration >= epoch_size_val:
break
images, targets = batch[0], batch[1]
with torch.no_grad():
if cuda:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor)).cuda()
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)).cuda() for ann in targets]
else:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor))
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets]
out = model(images)
optimizer.zero_grad()
loss_l, loss_c = criterion(out, targets)
loc_loss_val += loss_l.item()
conf_loss_val += loss_c.item()
pbar.set_postfix(**{'loc_loss': loc_loss_val / (iteration + 1),
'conf_loss': conf_loss_val / (iteration + 1),
'lr': get_lr(optimizer)})
pbar.update(1)
total_loss = loc_loss + conf_loss
val_loss = loc_loss_val + conf_loss_val
print('Finish Validation')
print('Epoch:' + str(epoch + 1) + '/' + str(Epoch))
print('Total Loss: %.4f || Val Loss: %.4f ' % (total_loss / (epoch_size + 1), val_loss / (epoch_size_val + 1)))
print('Saving state, iter:', str(epoch + 1))
torch.save(model.state_dict(),r'./logs/mymodel.pth')我这里只训练了50个epoch。试试效果,是可以正常训练的。
预测
边界框解码
在预测前,我们需要对预测结果进行解码
参数说明:num_classes是类别数量
bkg_label:背景类标签
top_k:指的把预测概率高的前k个结果
conf_thresh:置信度
nms_thresh:NMS阈值
class Detect(nn.Module):
def __init__(self, num_classes, bkg_label, top_k, conf_thresh, nms_thresh):
super().__init__()
self.num_classes = num_classes
self.background_label = bkg_label
self.top_k = top_k
self.nms_thresh = nms_thresh
if nms_thresh <= 0:
raise ValueError('nms_threshold must be non negative.')
self.conf_thresh = conf_thresh
self.variance = Config['variance']
def forward(self, loc_data, conf_data, prior_data):
#--------------------------------#
# 先转换成cpu下运行
#--------------------------------#
loc_data = loc_data.cpu()
conf_data = conf_data.cpu()
#--------------------------------#
# num的值为batch_size
# num_priors为先验框的数量
#--------------------------------#
num = loc_data.size(0)
num_priors = prior_data.size(0)
output = torch.zeros(num, self.num_classes, self.top_k, 5) # 建立一个output阵列存放输出
#--------------------------------------#
# 对分类预测结果进行reshape
# num, num_classes, num_priors
#--------------------------------------#
conf_preds = conf_data.view(num, num_priors, self.num_classes).transpose(2, 1) # transpose是将num_priors,num_classes维度进行反转
# 对每一张图片进行处理正常预测的时候只有一张图片,所以只会循环一次
for i in range(num):
#--------------------------------------#
# 对先验框解码获得预测框
# 解码后,获得的结果的shape为
# num_priors, 4
#--------------------------------------#
decoded_boxes = decode(loc_data[i], prior_data, self.variance) # 回归预测loc_data的结果对先验框进行调整
conf_scores = conf_preds[i].clone()
#--------------------------------------#
# 获得每一个类对应的分类结果
# num_priors,
#--------------------------------------#
for cl in range(1, self.num_classes):
#--------------------------------------#
# 首先利用门限进行判断
# 然后取出满足门限的得分
#--------------------------------------#
c_mask = conf_scores[cl].gt(self.conf_thresh)
scores = conf_scores[cl][c_mask]
if scores.size(0) == 0:
continue
l_mask = c_mask.unsqueeze(1).expand_as(decoded_boxes)
#--------------------------------------#
# 将满足门限的预测框取出来
#--------------------------------------#
boxes = decoded_boxes[l_mask].view(-1, 4)
#--------------------------------------#
# 利用这些预测框进行非极大抑制
#--------------------------------------#
ids, count = nms(boxes, scores, self.nms_thresh, self.top_k)
output[i, cl, :count] = torch.cat((scores[ids[:count]].unsqueeze(1), boxes[ids[:count]]), 1)
return output输出预测结果
这里的最终预测我也用的SSD中的方法,完整代码如下:
class VGG16(object):
_defaults = {
"model_path": 'logs/mymodel.pth', # 加载权重文件
"classes_path": 'model_data/new_classes.txt', # 加载类文件
"input_shape": (300, 300, 3), # 图像的shape
"confidence": 0.6, # 置信度
"nms_iou": 0.5, # NMS阈值
"cuda": True, # 是否用GPU
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
def __init__(self, **kwargs):
self.__dict__.update(self._defaults)
self.class_names = self._get_class()
self.generate()
# ---------------------------------------------------#
# 获得所有的分类
# ---------------------------------------------------#
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
# ---------------------------------------------------#
# 载入模型
# ---------------------------------------------------#
def generate(self):
# -------------------------------#
# 计算总的类的数量
# -------------------------------#
self.num_classes = len(self.class_names) + 1
# -------------------------------#
# 载入模型与权值
# -------------------------------#
model = Mymodel("test",2,self.confidence, self.nms_iou) # 实例化,调用模型
print('Loading weights into state dict...')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.load_state_dict(torch.load(self.model_path, map_location=device))
self.net = model.eval() # 模型测试
if self.cuda:
self.net = torch.nn.DataParallel(self.net)
cudnn.benchmark = True
self.net = self.net.cuda()
print('{} model, anchors, and classes loaded.'.format(self.model_path))
# 画框设置不同的颜色
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
# ---------------------------------------------------#
# 检测图片
# ---------------------------------------------------#
def detect_image(self, image):
image_shape = np.array(np.shape(image)[0:2])
# ---------------------------------------------------#
# 不失真的resize,给图像周围增加灰条
# ---------------------------------------------------#
crop_img = np.array(letterbox_image(image, (self.input_shape[1], self.input_shape[0])))
with torch.no_grad():
# ---------------------------------------------------#
# 图片预处理,归一化
# ---------------------------------------------------#
photo = Variable(
torch.from_numpy(np.expand_dims(np.transpose(crop_img - MEANS, (2, 0, 1)), 0)).type(torch.FloatTensor))
if self.cuda:
photo = photo.cuda()
# ---------------------------------------------------#
# 传入网络进行预测
# ---------------------------------------------------#
preds = self.net(photo)
top_conf = []
top_label = []
top_bboxes = []
# ---------------------------------------------------#
# preds的shape为 1, num_classes, top_k, 5
# ---------------------------------------------------#
for i in range(preds.size(1)):
j = 0
while preds[0, i, j, 0] >= self.confidence:
# ---------------------------------------------------#
# score为当前预测框的得分
# label_name为预测框的种类
# ---------------------------------------------------#
score = preds[0, i, j, 0]
label_name = self.class_names[i - 1]
# ---------------------------------------------------#
# pt的shape为4, 当前预测框的左上角右下角
# ---------------------------------------------------#
pt = (preds[0, i, j, 1:]).detach().numpy()
coords = [pt[0], pt[1], pt[2], pt[3]]
top_conf.append(score)
top_label.append(label_name)
top_bboxes.append(coords)
j = j + 1
# 如果不存在满足门限的预测框,直接返回原图
if len(top_conf) <= 0:
return image
top_conf = np.array(top_conf)
top_label = np.array(top_label)
top_bboxes = np.array(top_bboxes)
top_xmin, top_ymin, top_xmax, top_ymax = np.expand_dims(top_bboxes[:, 0], -1), np.expand_dims(top_bboxes[:, 1],
-1), np.expand_dims(
top_bboxes[:, 2], -1), np.expand_dims(top_bboxes[:, 3], -1)
boxes = ssd_correct_boxes(top_ymin, top_xmin, top_ymax, top_xmax,
np.array([self.input_shape[0], self.input_shape[1]]), image_shape)
font = ImageFont.truetype(font='model_data/simhei.ttf',
size=np.floor(3e-2 * np.shape(image)[1] + 0.5).astype('int32'))
thickness = max((np.shape(image)[0] + np.shape(image)[1]) // self.input_shape[0], 1)
for i, c in enumerate(top_label):
predicted_class = c
score = top_conf[i]
top, left, bottom, right = boxes[i]
top = top - 5
left = left - 5
bottom = bottom + 5
right = right + 5
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(np.shape(image)[0], np.floor(bottom + 0.5).astype('int32'))
right = min(np.shape(image)[1], np.floor(right + 0.5).astype('int32'))
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
label = label.encode('utf-8')
print(label, top, left, bottom, right)
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[self.class_names.index(predicted_class)])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[self.class_names.index(predicted_class)])
draw.text(text_origin, str(label, 'UTF-8'), fill=(0, 0, 0), font=font)
del draw
return image预测结果:

 https://blog.youkuaiyun.com/weixin_44791964/article/details/104981486?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164596303916780357223568%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164596303916780357223568&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-5-104981486.pc_search_result_positive&utm_term=%E7%9D%BF%E6%99%BASSD&spm=1018.2226.3001.4187
https://blog.youkuaiyun.com/weixin_44791964/article/details/104981486?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164596303916780357223568%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164596303916780357223568&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-5-104981486.pc_search_result_positive&utm_term=%E7%9D%BF%E6%99%BASSD&spm=1018.2226.3001.4187完整代码
代码已公布在github上,有问题欢迎讨论:https://github.com/YINYIPENG-EN/builde-my-VGG16-detection https://github.com/YINYIPENG-EN/builde-my-VGG16-detection
https://github.com/YINYIPENG-EN/builde-my-VGG16-detection


















 7217
7217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











