






在线策略强化学习(On-policy)和离线策略强化学习(Of-policy)的区别?
首先了解个概念行为策略和目标策略,行为策略是选择动作的策略,用于收集经验。而目标策略是被优化和改进的策略,是agent最终想要学到的策略。
On-policy的行为策略和目标策略是同一个,收集的数据可以直接改进策略
Off-policy的行为策略和目标策略不是同一个,代理可以用探索性更强的策略收集数据
| 特性 | On-policy | Off-policy |
|---|---|---|
| 策略关系 | 行为策略与目标策略相同 | 行为策略与目标策略不同 |
| 样本利用率 | 低、只能用当前的数据 | 高、能够利用历史交互数据 |
| 策略偏差 | 低、行为和目标策略相同 | 高、历史数据不一定是最优策略的选择 |
环境模型用监督学习的方法
监督学习的方法学习状态转移模型和奖励函数,例如用CNN、RNN等等。
状态转移模型的输入是st和at,输出st+1
奖励函数模型的输入是st和at,输出的是rt
监督学习是依赖训练集,对于没见过的数据效果差
强化学习是通过反复与环境交互试错,学习策略获得最大化累积奖励的路径。
模型的作用是预测未来会发生什么,模型的目标是让智能体学习到最优策略。
学习的模型是具有随机性环境,解决过拟合问题(模型学习的过程中的过拟合了已有数据,会表现出极度的自信,而环境本身是随机性的)
什么是概率,什么是似然?
概率是结果还没有产生之前,会根据现有环境的性质(参数)预测某件事件发生的概率
似然是概率的相反,它是根据已经确定的结果来推测产生这个结果的可能环境(参数)(根据结果判断事情本身性质的过程)

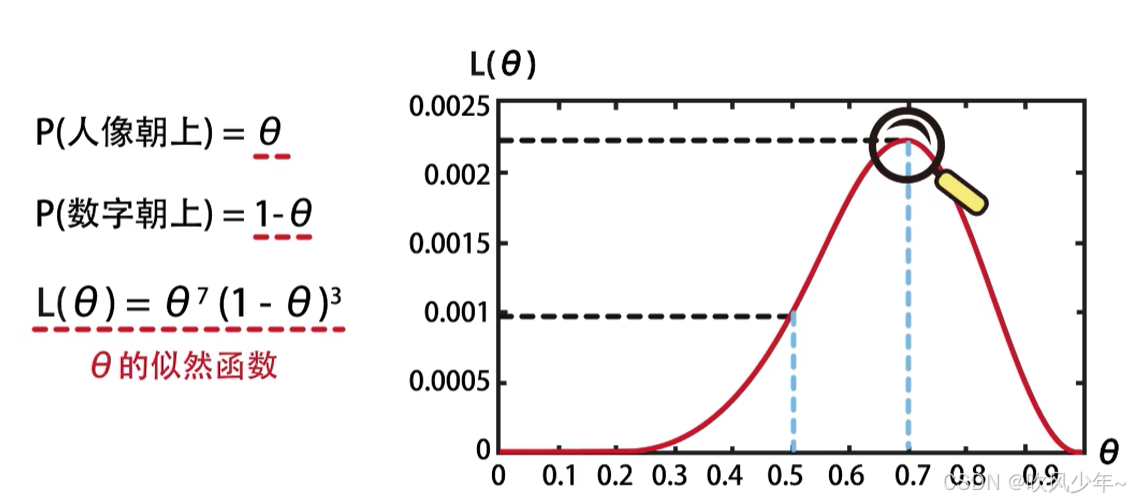
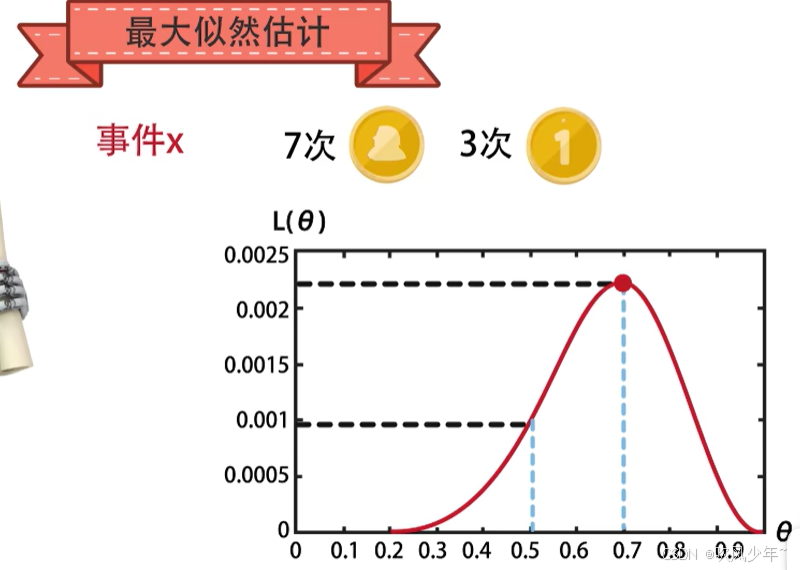
似然是根据结果来推断参数,概率是根据参数推断结果
模型学习存在的问题
过拟合、数据不足(对于随机环境)
模型的误差会导致策略的误差
1.模型生成的数据于真实采样的数据存在分布差异,如果使用模型生成完整的轨迹,而每一步都有可能产生偏差,这些误差就会被放大,导致策略学习偏差。所以可以用不采样完整轨迹的方法,而采样较短的轨迹
2.仅仅靠虚拟数据训练,agent会学习到错误的策略。off-policy能够使用真实数据和虚拟数据,利用真实数据修正偏差
模型对于真实样本数据训练表现得太好,而在新数据上表现较差,过拟合忽略了环境的随机性
对于样本数据非常大得情况下,收集得数据很难覆盖所有得状态,导致模型在某些重要得环境下缺乏足够的数据进行有效的学习
方法:
每执行一个动作后,将样本添加到模型训练数据中,重新学习模型,不断修正自己.
策略与规划的区别
策略是根据当前的状态选择的动作
规划是根据当前的状态、环境、策略,计算出最佳的动作序列,在理论上最大化奖励


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









