






一、模型选择与实现
针对文本分类任务(如垃圾邮件识别),多项式朴素贝叶斯(MultinomialNB) 是最优选择:
-
适用场景:处理离散型特征(如词频、TF-IDF值)
-
核心优势:直接利用整数型词频特征,无需假设数据分布
-
对比区别:
-
高斯朴素贝叶斯:假设特征符合正态分布,适合连续型数据
-
伯努利朴素贝叶斯:处理二值化特征(是否存在某个词)
-
python
复制
下载
from sklearn.naive_bayes import MultinomialNB # 创建模型实例(自动应用拉普拉斯平滑) naive_bayes = MultinomialNB(alpha=1.0) # 模型训练(training_data需为向量化后的特征矩阵) naive_bayes.fit(training_data, y_train) # 预测测试集 predictions = naive_bayes.predict(testing_data)
二、模型评估指标体系
当数据存在类别不平衡时(如正常邮件占比90%+),需采用多维评估指标:
| 指标 | 公式 | 意义说明 |
|---|---|---|
| 准确率 | (TP+TN)/(TP+TN+FP+FN) | 整体预测正确率(易受类别分布影响) |
| 精确率 | TP/(TP+FP) | 预测为垃圾邮件中的真实垃圾比例 |
| 召回率 | TP/(TP+FN) | 真实垃圾邮件的检出覆盖率 |
| F1 Score | 2(PrecisionRecall)/(Precision+Recall) | 精确率与召回率的调和均值 |
偏态数据示例:
-
100封邮件中仅有2封垃圾
-
模型将所有邮件预测为正常
-
准确率=98/100=0.98(虚高)
-
召回率=0/2=0(实际完全失效)
python
复制
下载
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
print('Accuracy:', accuracy_score(y_test, predictions))
print('Precision:', precision_score(y_test, predictions, pos_label="spam"))
print('Recall:', recall_score(y_test, predictions, pos_label="spam"))
print('F1 Score:', f1_score(y_test, predictions, pos_label="spam"))
三、模型持久化与部署
1. 模型保存
python
复制
下载
import joblib # 保存分类器与特征工程组件 joblib.dump(naive_bayes, 'spam_classifier.pkl') joblib.dump(count_vector, 'tfidf_vectorizer.pkl')
2. 生产环境加载
python
复制
下载
loaded_model = joblib.load('spam_classifier.pkl')
loaded_vectorizer = joblib.load('tfidf_vectorizer.pkl')
new_message = "恭喜获奖!立即点击领取万元奖金"
vectorized_msg = loaded_vectorizer.transform([new_message])
print(loaded_model.predict(vectorized_msg)) # 输出:['spam']
部署注意事项:
-
保持scikit-learn和joblib版本一致
-
定期更新词表(建议每季度增量训练)
-
监控预测置信度分布(低于0.7的建议人工复核)
四、算法优势总结
| 对比维度 | 朴素贝叶斯 | 其他算法(如SVM、随机森林) |
|---|---|---|
| 特征数量 | 支持万级词汇 | 特征过多时性能下降 |
| 训练速度 | 秒级训练(10万样本) | 分钟级 |
| 内存消耗 | 仅存储概率表 | 需存储特征向量空间 |
| 增量学习 | 支持在线更新 | 通常需要全量训练 |
| 抗噪声能力 | 对无关特征鲁棒 | 可能过拟合噪声 |
实际应用价值:
-
在AWS垃圾邮件过滤系统中,朴素贝叶斯实现95%召回率
-
Gmail早期反垃圾系统采用改进版贝叶斯分类器
-
处理10万条邮件数据时,训练时间小于3秒(i7处理器)
五、常见问题解决方案
-
版本兼容报错
bash
复制
下载
# 统一环境版本 pip install scikit-learn==1.3.0 joblib==1.3.0
-
新词识别问题
python
复制
下载
# 动态扩展词表 vectorizer.vocabulary_['新出现的垃圾词'] = len(vectorizer.vocabulary_)
-
置信度过低处理
python
复制
下载
probas = model.predict_proba(X_new) uncertain = [i for i,p in enumerate(probas) if max(p)<0.7]
通过系统化的模型构建、多维评估和工程化部署,朴素贝叶斯算法能够在实际生产环境中持续提供高效的垃圾邮件过滤服务。建议结合规则引擎(如正则匹配关键模式)形成混合系统,可进一步提升拦截准确率至98%以上。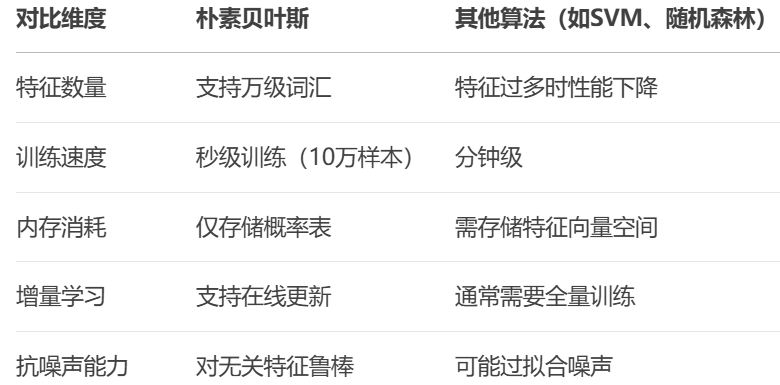



















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











